Understanding Empirical Unlearning with Combinatorial Interpretability
作者: Shingo Kodama, Niv Cohen, Micah Adler, Nir Shavit
分类: cs.LG
发布日期: 2026-02-22
💡 一句话要点
利用组合可解释性理解经验性模型遗忘中的知识残留问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型遗忘 组合可解释性 知识残留 神经网络 模型安全
📋 核心要点
- 现有模型遗忘方法难以彻底移除知识,且缺乏对知识残留的有效理解和可解释性。
- 论文利用组合可解释性框架,在两层神经网络中直接检查模型权重编码的知识。
- 实验分析了知识移除的彻底性以及被移除知识的可恢复性,揭示了知识残留的机制。
📝 摘要(中文)
尽管目前许多方法旨在从预训练模型中遗忘或移除知识,但看似被擦除的知识通常会持续存在,并且可以通过各种方式恢复。由于大型基础模型的可解释性较差,理解这些知识如何持续存在仍然是一个重大挑战。为了解决这个问题,我们转向最近开发的组合可解释性框架。该框架专为两层神经网络设计,可以直接检查模型权重中编码的知识。我们在组合可解释性设置中重现了基线遗忘方法,并从两个维度检查它们的行为:(i)它们是否真正移除了目标概念(我们希望移除的概念)的知识,或者仅仅抑制了其表达,同时保留了底层信息;(ii)通过各种微调操作,可以多么容易地恢复据称被擦除的知识。我们的结果在一个完全可解释的设置中阐明了知识如何在遗忘后仍然存在,以及何时可能重新出现。
🔬 方法详解
问题定义:现有模型遗忘方法,例如微调或权重扰动,虽然能降低模型在特定任务上的表现,但往往无法彻底移除相关知识。这些被“遗忘”的知识可能以某种形式潜藏在模型中,并可能在后续的微调或其他操作中重新激活。现有方法缺乏对这一现象的深入理解和可解释性,难以评估知识移除的真实效果。
核心思路:论文的核心思路是利用组合可解释性框架,将复杂的深度学习模型简化为可解释的两层神经网络。通过分析网络权重,可以直接观察和理解模型中编码的知识,从而更清晰地评估遗忘方法的有效性以及知识残留的机制。这种方法允许研究人员在可控的环境下研究知识的移除和恢复过程。
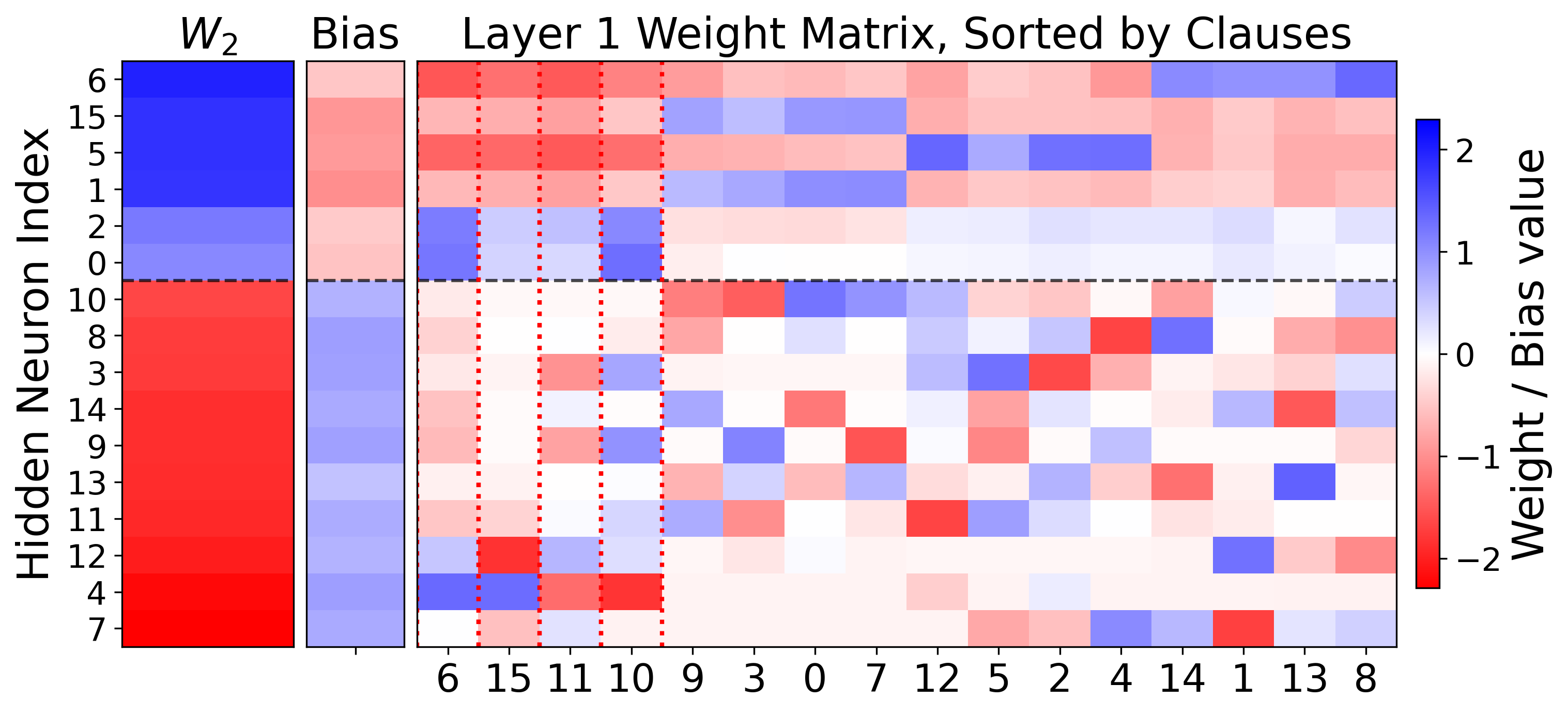
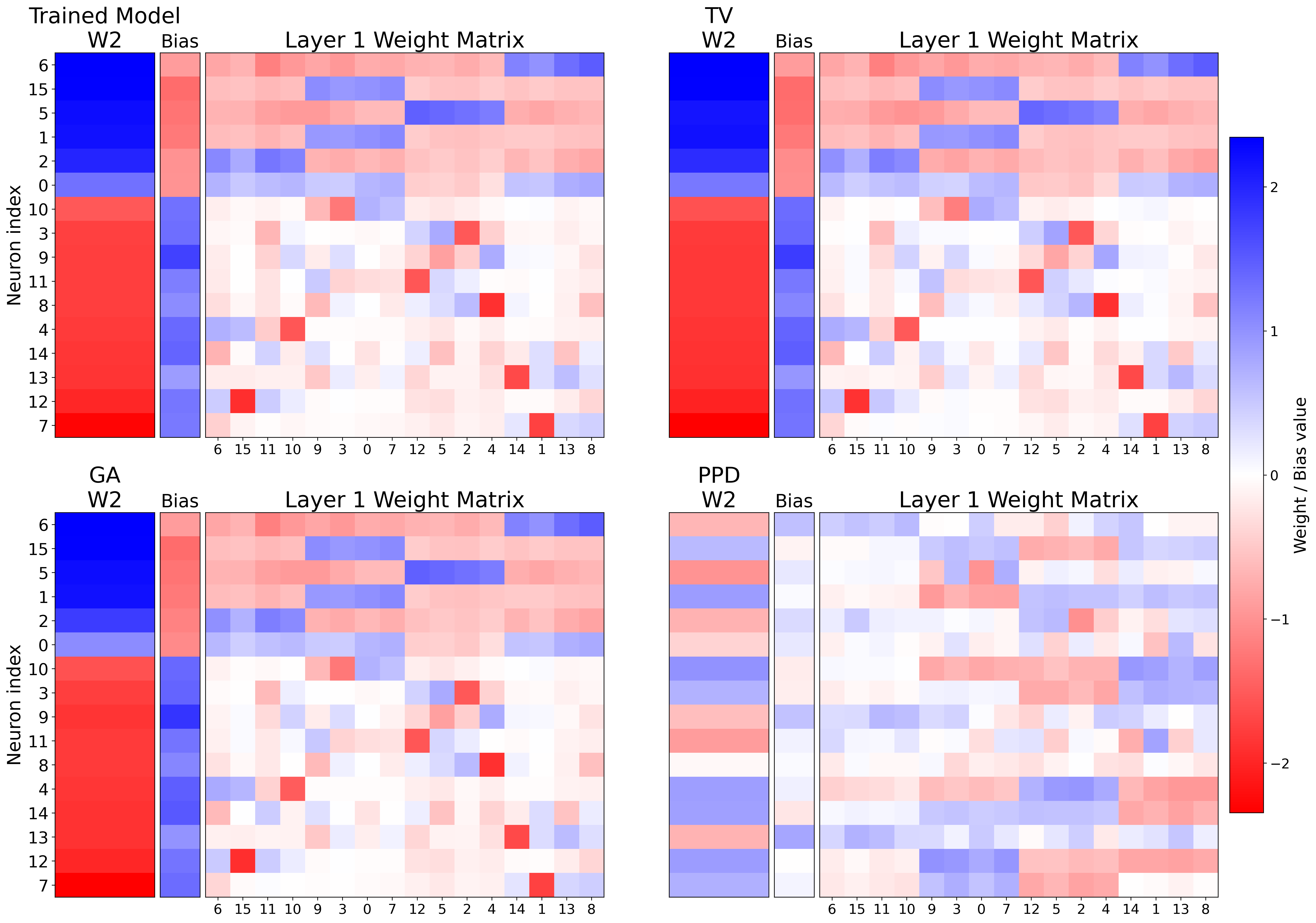
技术框架:该研究的技术框架主要包含以下几个步骤:1) 选择或构建一个两层神经网络模型;2) 在该模型上训练特定任务,使其具备需要被遗忘的知识;3) 应用现有的模型遗忘方法,例如微调或权重扰动;4) 利用组合可解释性框架分析模型权重,观察目标知识是否被真正移除,还是仅仅被抑制;5) 通过微调等操作,尝试恢复被“遗忘”的知识;6) 分析知识恢复的难易程度,评估遗忘方法的有效性。
关键创新:该论文的关键创新在于将组合可解释性框架应用于模型遗忘研究。与传统的黑盒方法不同,该方法能够直接观察模型内部的知识表示,从而更深入地理解遗忘过程。此外,该研究还关注知识残留问题,并探讨了知识恢复的可能性,这对于开发更有效的模型遗忘方法具有重要意义。
关键设计:论文的关键设计包括:1) 选择合适的两层神经网络结构,使其能够表达目标知识;2) 设计合理的实验方案,评估不同遗忘方法的效果;3) 使用组合可解释性框架,分析模型权重,提取关键的知识表示;4) 设计微调策略,尝试恢复被“遗忘”的知识;5) 定义合适的指标,量化知识移除和恢复的程度。
🖼️ 关键图片
📊 实验亮点
该研究在组合可解释性框架下,重现了基线遗忘方法,并从知识移除的彻底性和可恢复性两个维度进行了评估。实验结果表明,某些遗忘方法可能仅仅抑制了知识的表达,而没有真正移除底层信息。通过微调等操作,这些被“遗忘”的知识可以被相对容易地恢复。这些发现揭示了模型遗忘的复杂性,并为开发更有效的遗忘方法提供了指导。
🎯 应用场景
该研究成果可应用于对模型安全性要求较高的场景,例如涉及用户隐私或敏感信息的模型。通过更有效地移除模型中的相关知识,可以降低模型泄露隐私或被恶意利用的风险。此外,该研究也有助于开发更可靠的联邦学习和持续学习系统,确保模型在学习新知识的同时,能够安全地遗忘旧知识。
📄 摘要(原文)
While many recent methods aim to unlearn or remove knowledge from pretrained models, seemingly erased knowledge often persists and can be recovered in various ways. Because large foundation models are far from interpretable, understanding whether and how such knowledge persists remains a significant challenge. To address this, we turn to the recently developed framework of combinatorial interpretability. This framework, designed for two-layer neural networks, enables direct inspection of the knowledge encoded in the model weights. We reproduce baseline unlearning methods within the combinatorial interpretability setting and examine their behavior along two dimensions: (i) whether they truly remove knowledge of a target concept (the concept we wish to remove) or merely inhibit its expression while retaining the underlying information, and (ii) how easily the supposedly erased knowledge can be recovered through various fine-tuning operations. Our results shed light within a fully interpretable setting on how knowledge can persist despite unlearning and when it might resurface.