How to Allocate, How to Learn? Dynamic Rollout Allocation and Advantage Modulation for Policy Optimization
作者: Yangyi Fang, Jiaye Lin, Xiaoliang Fu, Cong Qin, Haolin Shi, Chaowen Hu, Lu Pan, Ke Zeng, Xunliang Cai
分类: cs.LG, cs.AI
发布日期: 2026-02-22
💡 一句话要点
DynaMO:针对LLM推理,优化Rollout分配与优势调制的策略优化框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 策略优化 资源分配 梯度调制 数学推理 可验证奖励
📋 核心要点
- 现有RLVR方法在LLM推理中采用均匀rollout分配,忽略了不同问题梯度方差的差异,导致资源利用率不高。
- DynaMO框架通过理论推导,提出方差最小化rollout分配策略,并结合梯度感知的优势调制,优化策略更新过程。
- 实验结果表明,DynaMO在数学推理基准测试中,相较于现有RLVR方法,性能得到显著提升,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为DynaMO的双管齐下的优化框架,旨在解决基于可验证奖励的强化学习(RLVR)应用于大型语言模型(LLM)推理时面临的资源分配和策略优化动态问题。现有方法的均匀rollout分配忽略了不同问题之间梯度方差的异质性,而softmax策略结构会导致高置信度正确动作的梯度衰减,同时过度的梯度更新可能破坏训练稳定性。DynaMO在序列层面,从第一性原理推导出方差最小化分配,并将伯努利方差确立为梯度信息量的可计算代理。在token层面,开发了基于梯度感知的优势调制,以补偿高置信度正确动作的梯度衰减,并利用熵变化作为可计算指标来稳定过度更新幅度。在各种数学推理基准上的大量实验表明,DynaMO相对于强大的RLVR基线具有一致的改进。
🔬 方法详解
问题定义:现有基于可验证奖励的强化学习(RLVR)方法在应用于大型语言模型(LLM)推理时,面临两个主要问题。一是均匀rollout分配策略忽略了不同问题之间梯度方差的异质性,导致资源分配效率低下。二是softmax策略结构导致高置信度正确动作的梯度衰减,使得模型难以进一步优化这些动作,同时过大的梯度更新幅度又可能导致训练不稳定。
核心思路:DynaMO的核心思路是根据问题的梯度信息量动态分配rollout资源,并对优势函数进行梯度感知的调制。通过最小化rollout的方差来优化资源分配,确保更有信息量的样本得到更多关注。同时,通过梯度感知的优势调制,补偿高置信度正确动作的梯度衰减,并利用熵变化来控制更新幅度,从而稳定训练过程。
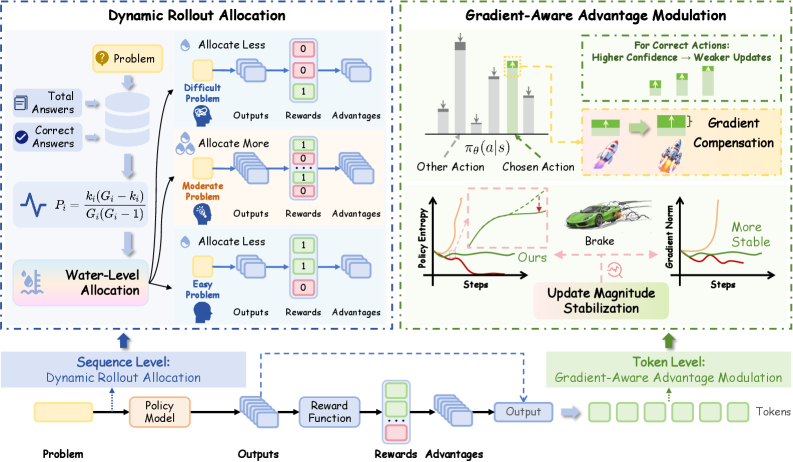
技术框架:DynaMO框架包含两个主要模块:动态Rollout分配和优势调制。动态Rollout分配模块根据每个问题的伯努利方差(作为梯度信息量的代理)动态调整rollout的数量。优势调制模块则根据token级别的梯度信息,对优势函数进行调制,以补偿高置信度动作的梯度衰减,并利用熵变化来稳定更新幅度。整体流程是,首先进行rollout,然后计算每个问题的伯努利方差,根据方差分配rollout资源,接着计算优势函数,并进行梯度感知的调制,最后更新策略。
关键创新:DynaMO的关键创新在于其双管齐下的优化策略。一是提出了基于方差最小化的动态rollout分配方法,能够更有效地利用计算资源。二是提出了梯度感知的优势调制方法,能够解决softmax策略结构导致的梯度衰减问题,并稳定训练过程。与现有方法相比,DynaMO能够更有效地学习和优化LLM的推理策略。
关键设计:在动态Rollout分配方面,论文将伯努利方差作为梯度信息量的可计算代理,并基于此推导出方差最小化的分配策略。在优势调制方面,论文设计了一种基于梯度幅度的调制函数,用于补偿高置信度动作的梯度衰减。此外,论文还利用熵变化作为指标,动态调整更新幅度,以防止训练不稳定。具体的参数设置和损失函数细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
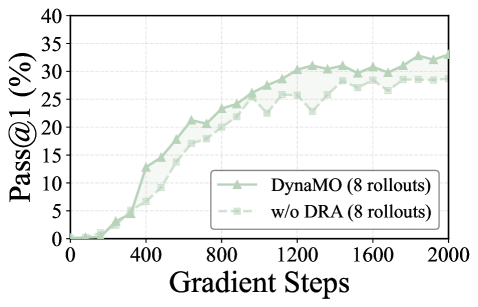
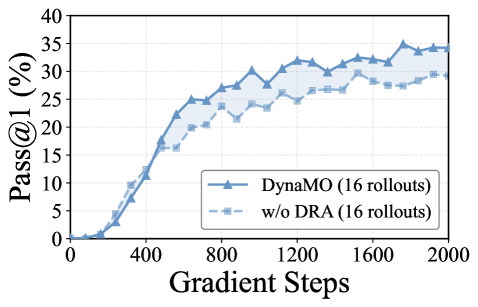
实验结果表明,DynaMO在多个数学推理基准测试中,相较于强大的RLVR基线,性能得到显著提升。例如,在某些基准测试中,DynaMO的准确率提升了5%以上。这些结果验证了DynaMO在资源分配和策略优化方面的有效性。
🎯 应用场景
DynaMO框架可广泛应用于需要复杂推理能力的大型语言模型(LLM)任务中,例如数学问题求解、代码生成、知识问答等。通过更有效地利用计算资源和优化策略更新,DynaMO能够提升LLM的推理性能和稳定性,从而推动LLM在各个领域的应用。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective for Large Language Model (LLM) reasoning, yet current methods face key challenges in resource allocation and policy optimization dynamics: (i) uniform rollout allocation ignores gradient variance heterogeneity across problems, and (ii) the softmax policy structure causes gradient attenuation for high-confidence correct actions, while excessive gradient updates may destabilize training. Therefore, we propose DynaMO, a theoretically-grounded dual-pronged optimization framework. At the sequence level, we prove that uniform allocation is suboptimal and derive variance-minimizing allocation from the first principle, establishing Bernoulli variance as a computable proxy for gradient informativeness. At the token level, we develop gradient-aware advantage modulation grounded in theoretical analysis of gradient magnitude bounds. Our framework compensates for gradient attenuation of high-confidence correct actions while utilizing entropy changes as computable indicators to stabilize excessive update magnitudes. Extensive experiments conducted on a diverse range of mathematical reasoning benchmarks demonstrate consistent improvements over strong RLVR baselines. Our implementation is available at: \href{https://anonymous.4open.science/r/dynamo-680E/README.md}{https://anonymous.4open.science/r/dynamo}.