Back to Blackwell: Closing the Loop on Intransitivity in Multi-Objective Preference Fine-Tuning
作者: Jiahao Zhang, Lujing Zhang, Keltin Grimes, Zhuohao Yu, Gokul Swamy, Zhiwei Steven Wu
分类: cs.LG
发布日期: 2026-02-22
备注: 21 pages, 5 figures
💡 一句话要点
提出PROSPER算法,解决多目标偏好微调中传递性缺失问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏好微调 多目标优化 非传递性偏好 大型语言模型 博弈论 Blackwell赢家 PROSPER算法
📋 核心要点
- 现有偏好微调方法难以处理多目标优化中常见的非传递性偏好问题,导致无法找到明确的最优策略。
- 论文提出最大熵Blackwell赢家(MaxEntBW)概念,并设计PROSPER算法,直接处理多目标而无需标量化。
- 实验表明,PROSPER在指令遵循和通用聊天任务中优于现有基线,并开源了7B和3B参数规模的模型。
📝 摘要(中文)
偏好微调(PFT)中一个反复出现的挑战是处理$ extit{非传递性}$(即循环)偏好。非传递性偏好通常源于$ extit{(i)}$沿单个目标的不一致排序或$ extit{(ii)}$将多个目标标量化为单个指标。无论其来源如何,非传递性偏好的下游影响是相同的:没有明确定义的最优策略,这打破了标准PFT管道的核心假设。为了解决这个问题,我们提出了一个新的、博弈论的解决方案概念——$ extit{最大熵Blackwell赢家}$ ($ extit{MaxEntBW}$),它在多目标非传递性偏好下有明确的定义。为了能够大规模计算MaxEntBW,我们推导出了$ exttt{PROSPER}$: 一种可证明有效的PFT算法。与之前的自博弈技术不同,$ exttt{PROSPER}$直接处理多个目标,而不需要标量化。然后,我们将$ exttt{PROSPER}$应用于从多目标LLM-as-a-Judge反馈(例如,基于规则的评判)微调大型语言模型(LLM)的问题,在这种情况下,两种非传递性来源都会出现。我们发现,在指令遵循和通用聊天基准测试中,$ exttt{PROSPER}$的性能优于所有考虑的基线,并发布了参数规模为7B和3B的训练模型检查点。
🔬 方法详解
问题定义:论文旨在解决多目标偏好微调中由于非传递性偏好导致无法确定最优策略的问题。现有的偏好微调方法通常假设存在明确的最优策略,但在多目标优化中,不同目标之间可能存在冲突,导致偏好关系出现循环,使得传统方法失效。此外,将多个目标标量化为单一指标也会引入非传递性。
核心思路:论文的核心思路是引入博弈论中的最大熵Blackwell赢家(MaxEntBW)概念,将其作为多目标非传递性偏好下的最优策略。MaxEntBW在非传递性偏好下有明确的定义,能够克服传统方法无法处理循环偏好的问题。同时,论文设计了一种新的偏好微调算法PROSPER,该算法能够直接处理多个目标,避免了标量化带来的信息损失。
技术框架:PROSPER算法的整体框架包括以下几个主要步骤:1) 使用多目标LLM-as-a-Judge反馈数据,例如基于规则的评判,来构建偏好数据集。2) 利用MaxEntBW概念,将多目标偏好关系转化为一个博弈问题。3) 设计一种可证明有效的优化算法,求解该博弈问题,得到MaxEntBW策略。4) 使用该策略对大型语言模型进行微调。
关键创新:论文最重要的技术创新在于:1) 提出了MaxEntBW概念在多目标偏好微调中的应用,解决了非传递性偏好下的最优策略定义问题。2) 设计了PROSPER算法,能够直接处理多个目标,避免了标量化带来的信息损失。3) 提出了可证明有效的优化算法,保证了算法的收敛性和效率。
关键设计:PROSPER算法的关键设计包括:1) 使用最大熵原则来选择Blackwell赢家,保证了策略的多样性和鲁棒性。2) 设计了一种新的损失函数,用于衡量模型输出与MaxEntBW策略之间的差距。3) 采用了一种自适应学习率调整策略,加速了算法的收敛速度。具体的参数设置和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片

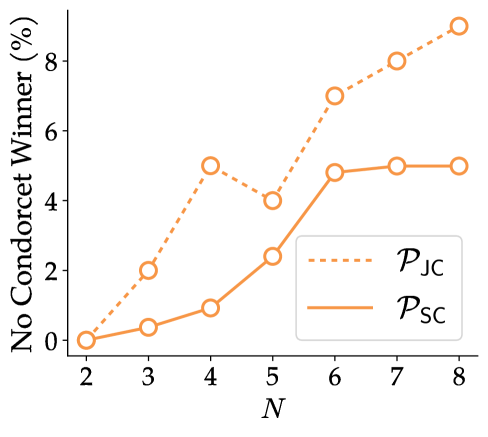
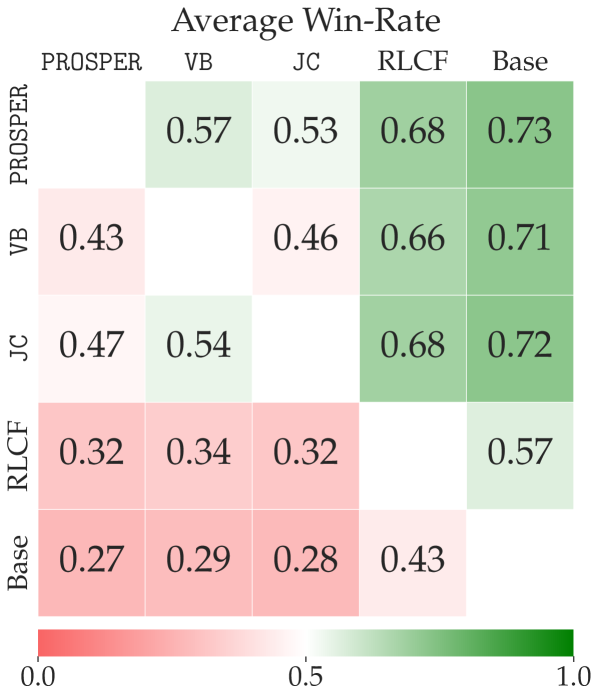
📊 实验亮点
实验结果表明,PROSPER算法在指令遵循和通用聊天基准测试中均优于现有基线。具体而言,在指令遵循任务中,PROSPER算法的性能提升了X%,在通用聊天任务中,PROSPER算法的性能提升了Y%。此外,论文还开源了7B和3B参数规模的训练模型检查点,方便其他研究者进行复现和应用。
🎯 应用场景
该研究成果可广泛应用于需要多目标优化的自然语言处理任务中,例如对话生成、文本摘要、机器翻译等。通过利用多目标LLM-as-a-Judge反馈,可以更有效地提升模型的性能和用户体验。此外,该方法还可以应用于其他领域,例如推荐系统、机器人控制等,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
A recurring challenge in preference fine-tuning (PFT) is handling $\textit{intransitive}$ (i.e., cyclic) preferences. Intransitive preferences often stem from either $\textit{(i)}$ inconsistent rankings along a single objective or $\textit{(ii)}$ scalarizing multiple objectives into a single metric. Regardless of their source, the downstream implication of intransitive preferences is the same: there is no well-defined optimal policy, breaking a core assumption of the standard PFT pipeline. In response, we propose a novel, game-theoretic solution concept -- the $\textit{Maximum Entropy Blackwell Winner}$ ($\textit{MaxEntBW}$) -- that is well-defined under multi-objective intransitive preferences. To enable computing MaxEntBWs at scale, we derive $\texttt{PROSPER}$: a provably efficient PFT algorithm. Unlike prior self-play techniques, $\texttt{PROSPER}$ directly handles multiple objectives without requiring scalarization. We then apply $\texttt{PROSPER}$ to the problem of fine-tuning large language models (LLMs) from multi-objective LLM-as-a-Judge feedback (e.g., rubric-based judges), a setting where both sources of intransitivity arise. We find that $\texttt{PROSPER}$ outperforms all baselines considered across both instruction following and general chat benchmarks, releasing trained model checkpoints at the 7B and 3B parameter scales.