Learning to Detect Language Model Training Data via Active Reconstruction
作者: Junjie Oscar Yin, John X. Morris, Vitaly Shmatikov, Sewon Min, Hannaneh Hajishirzi
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-22
💡 一句话要点
提出主动数据重构攻击以解决LLM训练数据检测问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 成员推断 主动数据重构 强化学习 大型语言模型 数据检测 隐私保护 模型安全
📋 核心要点
- 现有的成员推断攻击方法在固定模型权重上被动操作,无法有效利用模型的动态特性。
- 本文提出的ADRA方法通过强化学习主动诱导模型重构数据,利用重构能力差异进行成员推断。
- 实验结果显示,ADRA在多种数据检测任务中均显著优于传统方法,尤其在预训练和后训练检测上提升明显。
📝 摘要(中文)
检测大型语言模型(LLM)训练数据通常被视为一种成员推断攻击(MIA)问题。然而,传统的MIA方法在固定模型权重上被动操作,使用对数似然或文本生成。本文提出了主动数据重构攻击(ADRA),这是一种主动诱导模型通过训练重构给定文本的MIA方法。我们假设训练数据的重构能力比非成员数据更强,并利用这种差异进行成员推断。通过强化学习(RL)来主动引导数据重构,设计了重构指标和对比奖励。实验表明,ADRA及其自适应变体ADRA+在检测预训练、后训练和蒸馏数据方面均优于现有MIA方法,平均提升10.7%。
🔬 方法详解
问题定义:本文解决的是如何有效检测大型语言模型的训练数据,现有方法在固定模型权重上被动操作,无法充分利用模型的动态特性,导致检测效果不佳。
核心思路:论文的核心思路是通过主动数据重构攻击(ADRA)来引导模型重构特定文本,利用训练数据的重构能力比非成员数据更强的假设进行成员推断。
技术框架:整体架构包括使用强化学习(RL)对目标模型进行微调,以主动引导数据重构。主要模块包括重构指标设计和对比奖励机制。
关键创新:最重要的技术创新点在于将强化学习应用于成员推断,通过动态调整模型行为来提高重构能力,与传统的被动推断方法形成鲜明对比。
关键设计:在设计中,采用了特定的重构指标和对比奖励机制,以有效引导模型进行数据重构,同时在参数设置和损失函数上进行了优化,以提升整体性能。
🖼️ 关键图片
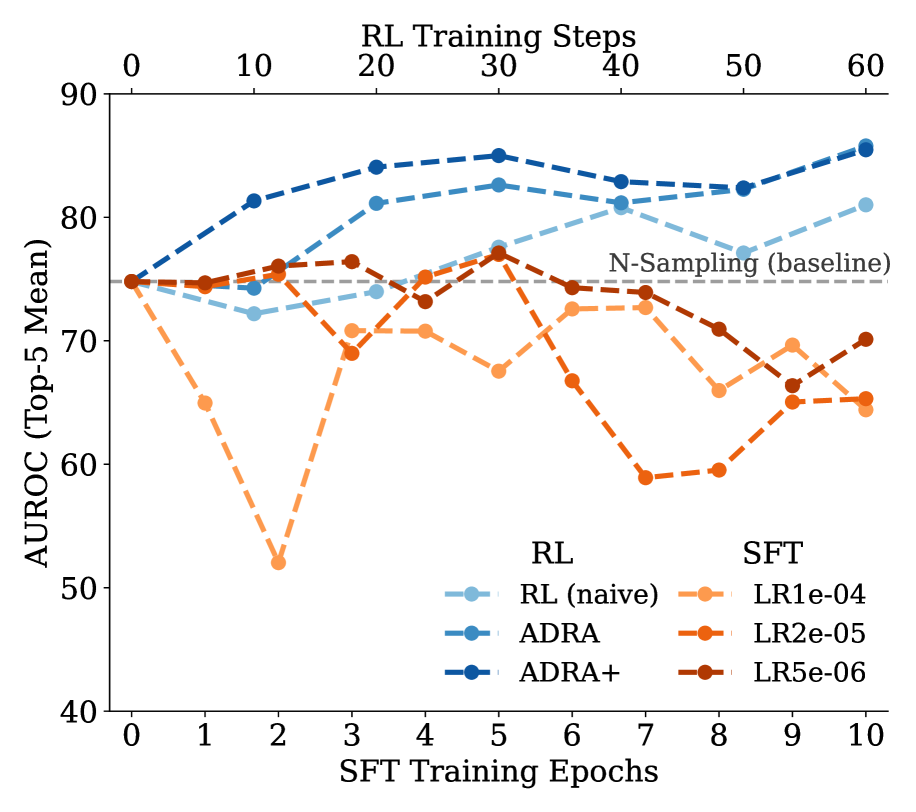
📊 实验亮点
实验结果表明,ADRA方法在检测预训练、后训练和蒸馏数据方面均显著优于现有的成员推断攻击方法,平均提升10.7%。特别是ADRA+在BookMIA上对预训练检测的提升达18.8%,在AIME上对后训练检测的提升为7.6%。
🎯 应用场景
该研究的潜在应用领域包括保护用户隐私、提高模型安全性以及优化训练数据管理。通过有效检测训练数据,能够帮助开发者更好地理解模型的学习过程,防止敏感信息泄露,并提升模型的透明度和可信度。
📄 摘要(原文)
Detecting LLM training data is generally framed as a membership inference attack (MIA) problem. However, conventional MIAs operate passively on fixed model weights, using log-likelihoods or text generations. In this work, we introduce \textbf{Active Data Reconstruction Attack} (ADRA), a family of MIA that actively induces a model to reconstruct a given text through training. We hypothesize that training data are \textit{more reconstructible} than non-members, and the difference in their reconstructibility can be exploited for membership inference. Motivated by findings that reinforcement learning (RL) sharpens behaviors already encoded in weights, we leverage on-policy RL to actively elicit data reconstruction by finetuning a policy initialized from the target model. To effectively use RL for MIA, we design reconstruction metrics and contrastive rewards. The resulting algorithms, \textsc{ADRA} and its adaptive variant \textsc{ADRA+}, improve both reconstruction and detection given a pool of candidate data. Experiments show that our methods consistently outperform existing MIAs in detecting pre-training, post-training, and distillation data, with an average improvement of 10.7\% over the previous runner-up. In particular, \MethodPlus~improves over Min-K\%++ by 18.8\% on BookMIA for pre-training detection and by 7.6\% on AIME for post-training detection.