Incremental Transformer Neural Processes
作者: Philip Mortimer, Cristiana Diaconu, Tommy Rochussen, Bruno Mlodozeniec, Richard E. Turner
分类: cs.LG
发布日期: 2026-02-21
备注: Code provided at https://github.com/philipmortimer/incTNP-code
💡 一句话要点
提出增量Transformer神经过程(incTNP),加速序列数据建模并保持性能。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 增量学习 Transformer神经过程 序列建模 因果掩码 键值缓存
📋 核心要点
- 现有Transformer神经过程(TNP)在处理序列数据时,每次更新都需要重新计算,效率低下。
- incTNP借鉴大型语言模型,利用因果掩码和KV缓存,实现增量更新,降低计算复杂度。
- 实验表明,incTNP在保持或提升预测性能的同时,显著加速了序列推理过程。
📝 摘要(中文)
神经过程(NPs),特别是Transformer神经过程(TNPs),在时空预测和表格数据建模等任务中表现出色。然而,许多应用本质上是序列化的,涉及实时传感器读数或数据库更新等连续数据流。在这种情况下,模型应支持廉价的增量更新,而不是为每个新观测从头开始重新计算内部表示——这是现有TNP变体所缺乏的能力。受大型语言模型的启发,我们引入了增量TNP(incTNP)。通过利用因果掩码、键值(KV)缓存和数据高效的自回归训练策略,incTNP在降低更新的计算成本(从二次方到线性时间复杂度)的同时,匹配了标准TNP的预测性能。我们在一系列合成和真实世界的任务(包括表格回归和温度预测)上对我们的模型进行了实证评估。结果表明,令人惊讶的是,incTNP提供了与非因果TNP相当或更好的性能,同时为顺序推理解锁了数量级的加速。最后,我们通过调整“隐式贝叶斯性”的度量标准来评估模型更新的一致性,表明incTNP保留了与标准非因果TNP一样隐式贝叶斯的预测规则,证明incTNP实现了因果掩码的计算优势,而没有牺牲流式推理所需的一致性。
🔬 方法详解
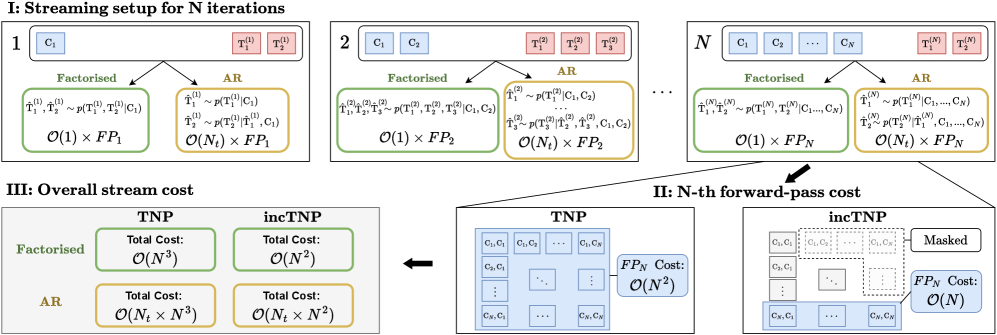
问题定义:现有的Transformer神经过程(TNPs)在处理序列数据时,每次接收到新的观测数据都需要从头开始重新计算内部表示,导致计算成本高昂,尤其是在数据流持续更新的场景下,这种重复计算成为性能瓶颈。因此,需要一种能够支持增量更新的TNP变体,以降低计算复杂度。
核心思路:incTNP的核心思路是借鉴大型语言模型(LLMs)的架构设计,特别是利用因果掩码(causal masking)和键值(KV)缓存(Key-Value caching)机制,来实现对序列数据的增量处理。通过这种方式,模型可以仅对新输入的数据进行计算,而无需重新处理整个序列,从而显著降低计算成本。
技术框架:incTNP的整体架构基于Transformer模型,并进行了关键修改以支持增量更新。主要包括以下几个模块:1)编码器:将输入数据编码成潜在表示;2)因果自注意力机制:利用因果掩码确保模型只能关注过去的信息,从而实现自回归建模;3)KV缓存:存储先前计算的键值对,以便在后续的增量更新中重复使用,避免重复计算;4)解码器:根据潜在表示和KV缓存生成预测结果。
关键创新:incTNP最关键的创新在于将大型语言模型中常用的因果掩码和KV缓存机制引入到Transformer神经过程中,从而实现了对序列数据的增量处理。与传统的TNPs相比,incTNP无需为每个新的观测数据从头开始重新计算内部表示,而是可以仅对新输入的数据进行计算,并利用KV缓存来重用先前计算的结果,从而显著降低了计算复杂度。
关键设计:incTNP的关键设计包括:1)因果掩码的具体实现方式,确保模型只能关注过去的信息;2)KV缓存的存储和检索策略,以最大程度地减少重复计算;3)数据高效的自回归训练策略,以提高模型的泛化能力;4)损失函数的设计,用于优化模型的预测性能和一致性。
🖼️ 关键图片
📊 实验亮点
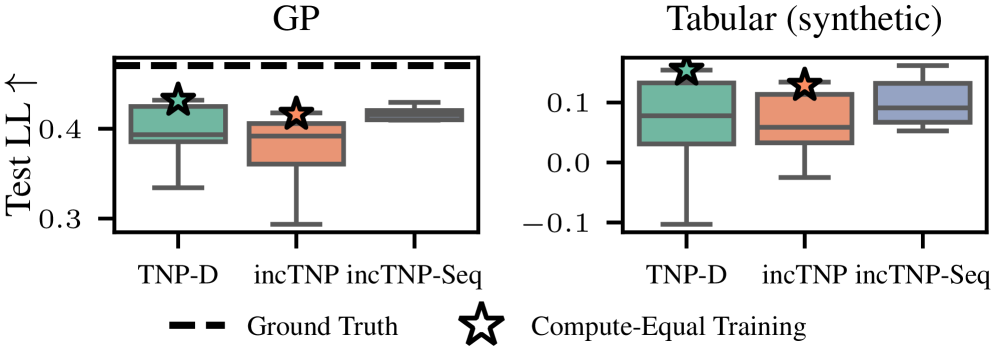
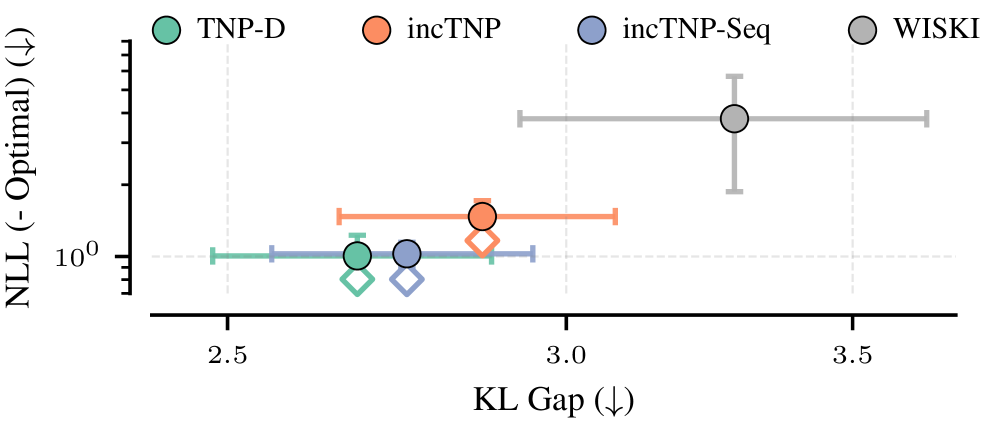
实验结果表明,incTNP在表格回归和温度预测等任务上,性能可与非因果TNP相媲美甚至更优。更重要的是,incTNP将序列推理的计算成本从二次方降低到线性,实现了数量级的加速。此外,通过隐式贝叶斯性度量,证明了incTNP在实现计算优势的同时,保持了与标准TNP相当的预测一致性。
🎯 应用场景
incTNP适用于各种需要处理连续数据流的场景,例如实时传感器数据分析、金融时间序列预测、智能交通系统和工业过程监控。通过降低计算成本,incTNP使得在资源受限的环境中部署复杂的序列模型成为可能,并为实时决策和控制提供了更快的响应速度。
📄 摘要(原文)
Neural Processes (NPs), and specifically Transformer Neural Processes (TNPs), have demonstrated remarkable performance across tasks ranging from spatiotemporal forecasting to tabular data modelling. However, many of these applications are inherently sequential, involving continuous data streams such as real-time sensor readings or database updates. In such settings, models should support cheap, incremental updates rather than recomputing internal representations from scratch for every new observation -- a capability existing TNP variants lack. Drawing inspiration from Large Language Models, we introduce the Incremental TNP (incTNP). By leveraging causal masking, Key-Value (KV) caching, and a data-efficient autoregressive training strategy, incTNP matches the predictive performance of standard TNPs while reducing the computational cost of updates from quadratic to linear time complexity. We empirically evaluate our model on a range of synthetic and real-world tasks, including tabular regression and temperature prediction. Our results show that, surprisingly, incTNP delivers performance comparable to -- or better than -- non-causal TNPs while unlocking orders-of-magnitude speedups for sequential inference. Finally, we assess the consistency of the model's updates -- by adapting a metric of ``implicit Bayesianness", we show that incTNP retains a prediction rule as implicitly Bayesian as standard non-causal TNPs, demonstrating that incTNP achieves the computational benefits of causal masking without sacrificing the consistency required for streaming inference.