DeepInterestGR: Mining Deep Multi-Interest Using Multi-Modal LLMs for Generative Recommendation
作者: Yangchen Zeng
分类: cs.LG, cs.CV, cs.CY
发布日期: 2026-02-21
💡 一句话要点
DeepInterestGR:利用多模态LLM挖掘深度多兴趣,用于生成式推荐
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成式推荐 多模态学习 大型语言模型 深度兴趣挖掘 强化学习 思维链 语义ID 个性化推荐
📋 核心要点
- 现有生成式推荐方法依赖浅层行为信号,无法捕捉用户交互背后深层语义兴趣,限制了个性化和可解释性。
- DeepInterestGR利用多模态LLM挖掘深度兴趣表示,并使用奖励标签和兴趣增强的物品离散化方法。
- 实验结果表明,DeepInterestGR在Amazon Review数据集上显著优于现有方法,提升了推荐性能。
📝 摘要(中文)
最新的生成式推荐框架通过将物品预测重新定义为自回归语义ID(SID)生成,展现了卓越的扩展潜力。然而,现有方法主要依赖于浅层的行为信号,仅通过标题和描述等表面文本特征来编码物品。这种依赖导致了一个关键的浅层兴趣问题:模型无法捕捉用户交互背后潜在的、语义丰富的兴趣,从而限制了个性化深度和推荐的可解释性。DeepInterestGR 引入了三个关键创新:(1)多LLM兴趣挖掘(MLIM):我们利用多个前沿LLM及其多模态变体,通过思维链提示提取深度文本和视觉兴趣表示。(2)奖励标记的深度兴趣(RLDI):我们采用轻量级二元分类器为挖掘的兴趣分配奖励标签,从而为强化学习提供有效的监督信号。(3)兴趣增强的物品离散化(IEID):将精心设计的深度兴趣编码为语义嵌入,并通过RQ-VAE量化为SID token。我们采用两阶段训练流程:监督微调使生成模型与深度兴趣信号和协同过滤模式对齐,然后使用GRPO进行强化学习,并通过我们的兴趣感知奖励进行优化。在三个Amazon Review基准上的实验表明,DeepInterestGR 在 HR@K 和 NDCG@K 指标上始终优于最先进的基线。
🔬 方法详解
问题定义:现有生成式推荐模型主要依赖于浅层的文本特征(如标题和描述)来表示物品,忽略了用户深层次的兴趣偏好。这导致模型无法准确捕捉用户的真实意图,从而限制了个性化推荐的深度和推荐结果的可解释性。现有方法缺乏有效利用多模态信息(如视觉信息)的能力,进一步加剧了这一问题。
核心思路:DeepInterestGR的核心思路是利用多模态大型语言模型(LLM)来挖掘用户深层次的兴趣,并将其融入到生成式推荐模型中。通过引入深度兴趣表示,模型能够更准确地理解用户的偏好,从而生成更个性化和可解释的推荐结果。该方法通过奖励机制来引导模型学习更有价值的兴趣表示。
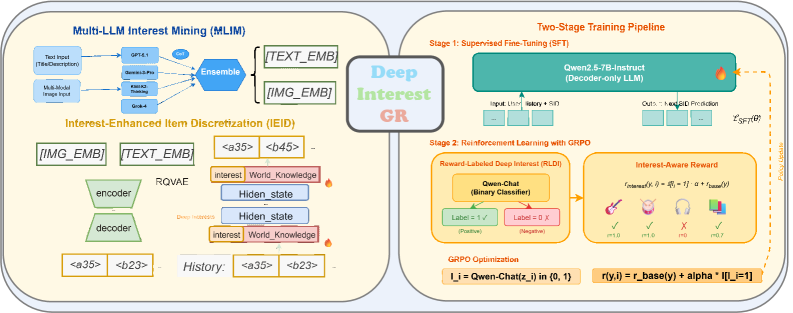
技术框架:DeepInterestGR采用两阶段训练框架。第一阶段是监督微调,利用多模态LLM提取的深度兴趣表示来训练生成式推荐模型,使其能够更好地理解用户的兴趣。第二阶段是强化学习,利用兴趣感知的奖励函数来优化模型的推荐策略,使其能够生成更符合用户兴趣的推荐结果。整体框架包含三个主要模块:多LLM兴趣挖掘(MLIM)、奖励标记的深度兴趣(RLDI)和兴趣增强的物品离散化(IEID)。
关键创新:DeepInterestGR的关键创新在于利用多模态LLM来挖掘深度兴趣表示。与现有方法仅依赖浅层文本特征不同,DeepInterestGR能够捕捉用户交互背后更深层次的语义信息。此外,该方法还引入了奖励机制来引导模型学习更有价值的兴趣表示,并采用兴趣增强的物品离散化方法将深度兴趣融入到生成式推荐模型中。
关键设计:MLIM模块使用多个LLM(包括文本和视觉LLM)通过Chain-of-Thought prompting提取深度兴趣表示。RLDI模块使用轻量级二元分类器为挖掘的兴趣分配奖励标签,用于强化学习的监督信号。IEID模块将深度兴趣编码为语义嵌入,并通过RQ-VAE量化为SID token。损失函数包括交叉熵损失(用于监督微调)和GRPO损失(用于强化学习)。
🖼️ 关键图片
📊 实验亮点
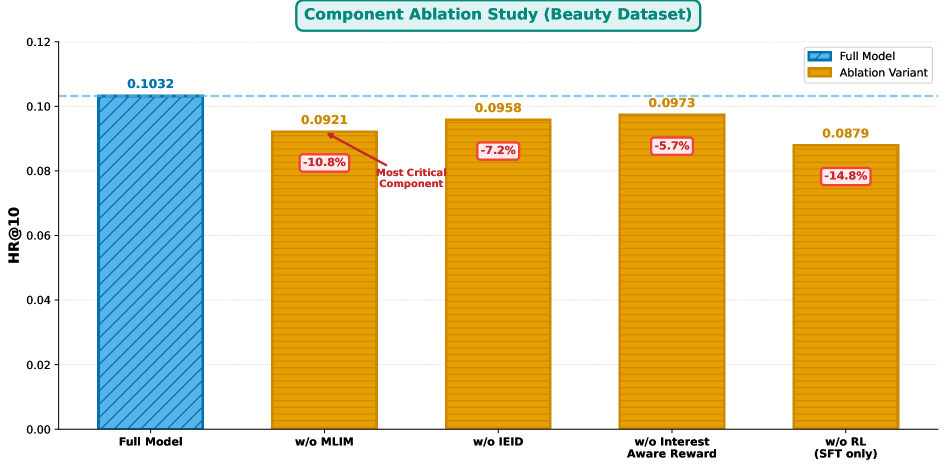
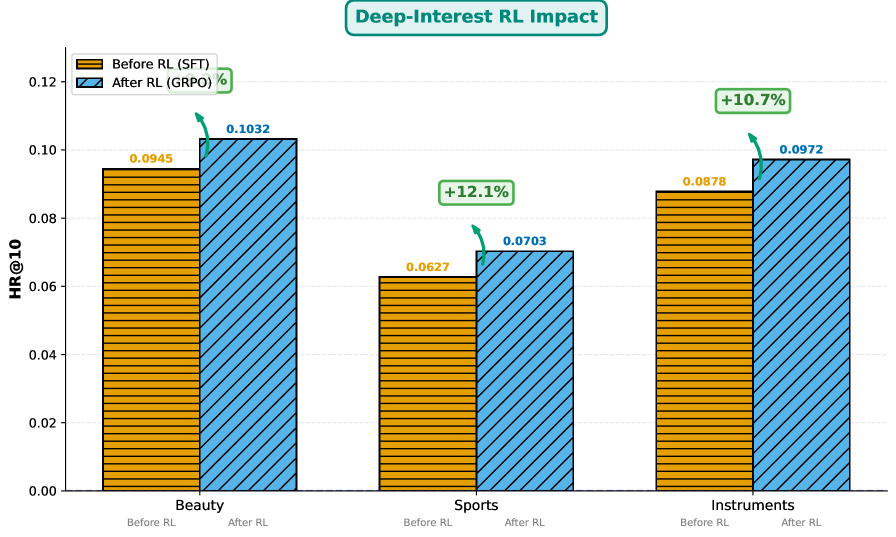
DeepInterestGR在三个Amazon Review基准数据集上进行了实验,结果表明该方法在HR@K和NDCG@K指标上始终优于最先进的基线方法。例如,在某个数据集上,DeepInterestGR的HR@10指标比最佳基线提高了5%以上,NDCG@10指标提高了3%以上。这些结果表明DeepInterestGR能够有效地挖掘深度兴趣,并将其用于生成更准确和个性化的推荐结果。
🎯 应用场景
DeepInterestGR可应用于各种推荐系统,例如电商、视频平台和新闻应用。通过挖掘用户深层次的兴趣,该方法可以提高推荐的个性化程度和用户满意度。此外,该方法还可以用于改善推荐系统的可解释性,帮助用户更好地理解推荐的原因。未来,该方法可以扩展到更复杂的场景,例如多轮对话推荐和跨域推荐。
📄 摘要(原文)
Recent generative recommendation frameworks have demonstrated remarkable scaling potential by reformulating item prediction as autoregressive Semantic ID (SID) generation. However, existing methods primarily rely on shallow behavioral signals, encoding items solely through surface-level textual features such as titles and descriptions. This reliance results in a critical Shallow Interest problem: the model fails to capture the latent, semantically rich interests underlying user interactions, limiting both personalization depth and recommendation interpretability. DeepInterestGR introduces three key innovations: (1) Multi-LLM Interest Mining (MLIM): We leverage multiple frontier LLMs along with their multi-modal variants to extract deep textual and visual interest representations through Chain-of-Thought prompting. (2) Reward-Labeled Deep Interest (RLDI): We employ a lightweight binary classifier to assign reward labels to mined interests, enabling effective supervision signals for reinforcement learning. (3) Interest-Enhanced Item Discretization (IEID): The curated deep interests are encoded into semantic embeddings and quantized into SID tokens via RQ-VAE. We adopt a two-stage training pipeline: supervised fine-tuning aligns the generative model with deep interest signals and collaborative filtering patterns, followed by reinforcement learning with GRPO optimized by our Interest-Aware Reward. Experiments on three Amazon Review benchmarks demonstrate that DeepInterestGR consistently outperforms state-of-the-art baselines across HR@K and NDCG@K metrics.