TRUE: A Trustworthy Unified Explanation Framework for Large Language Model Reasoning
作者: Yujiao Yang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-21
💡 一句话要点
提出TRUE框架,用于提升大语言模型推理过程的可信性和可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 可解释性 推理验证 因果分析 失效模式分析
📋 核心要点
- 现有LLM解释方法缺乏结构性洞察,难以揭示推理的稳定性和系统性失效机制。
- TRUE框架通过集成可执行推理验证、可行区域DAG建模和因果失效模式分析,提供多层次解释。
- 实验表明TRUE框架能够提供可验证的解释,包括推理结构、可行区域表示和可解释的失效模式。
📝 摘要(中文)
大型语言模型(LLMs)在复杂推理任务中表现出强大的能力,但其决策过程仍然难以解释。现有的解释方法通常缺乏可信的结构性洞察,并且仅限于单实例分析,无法揭示推理的稳定性和系统性失效机制。为了解决这些局限性,我们提出了可信统一解释框架(TRUE),该框架集成了可执行推理验证、可行区域有向无环图(DAG)建模和因果失效模式分析。在实例层面,我们将推理轨迹重新定义为可执行的过程规范,并引入盲执行验证来评估操作有效性。在局部结构层面,我们通过结构一致的扰动构建可行区域DAG,从而能够显式地表征推理的稳定性和局部输入空间中的可执行区域。在类层面,我们引入了一种因果失效模式分析方法,该方法识别重复出现的结构性失效模式,并使用Shapley值量化其因果影响。在多个推理基准上的大量实验表明,所提出的框架提供了多层次、可验证的解释,包括单个实例的可执行推理结构、相邻输入的可行区域表示以及类层面具有量化重要性的可解释失效模式。这些结果建立了一个统一且有原则的范例,用于提高LLM推理系统的可解释性和可靠性。
🔬 方法详解
问题定义:现有的大语言模型在复杂推理任务中表现出色,但其推理过程如同黑盒,缺乏透明度和可解释性。现有的解释方法通常只能针对单个实例进行分析,无法揭示模型推理的稳定性和潜在的系统性错误模式。因此,如何提供可信、多层次的解释,并识别LLM推理过程中的失效模式,是本文要解决的核心问题。
核心思路:TRUE框架的核心思路是将LLM的推理过程视为一个可执行的过程,通过验证推理轨迹的有效性来评估其可信度。同时,通过构建可行区域DAG来表征推理的稳定性,并利用因果分析方法识别导致推理失败的结构性模式。这种多层次的解释方法能够提供更全面、深入的理解,从而提高LLM推理系统的可靠性。
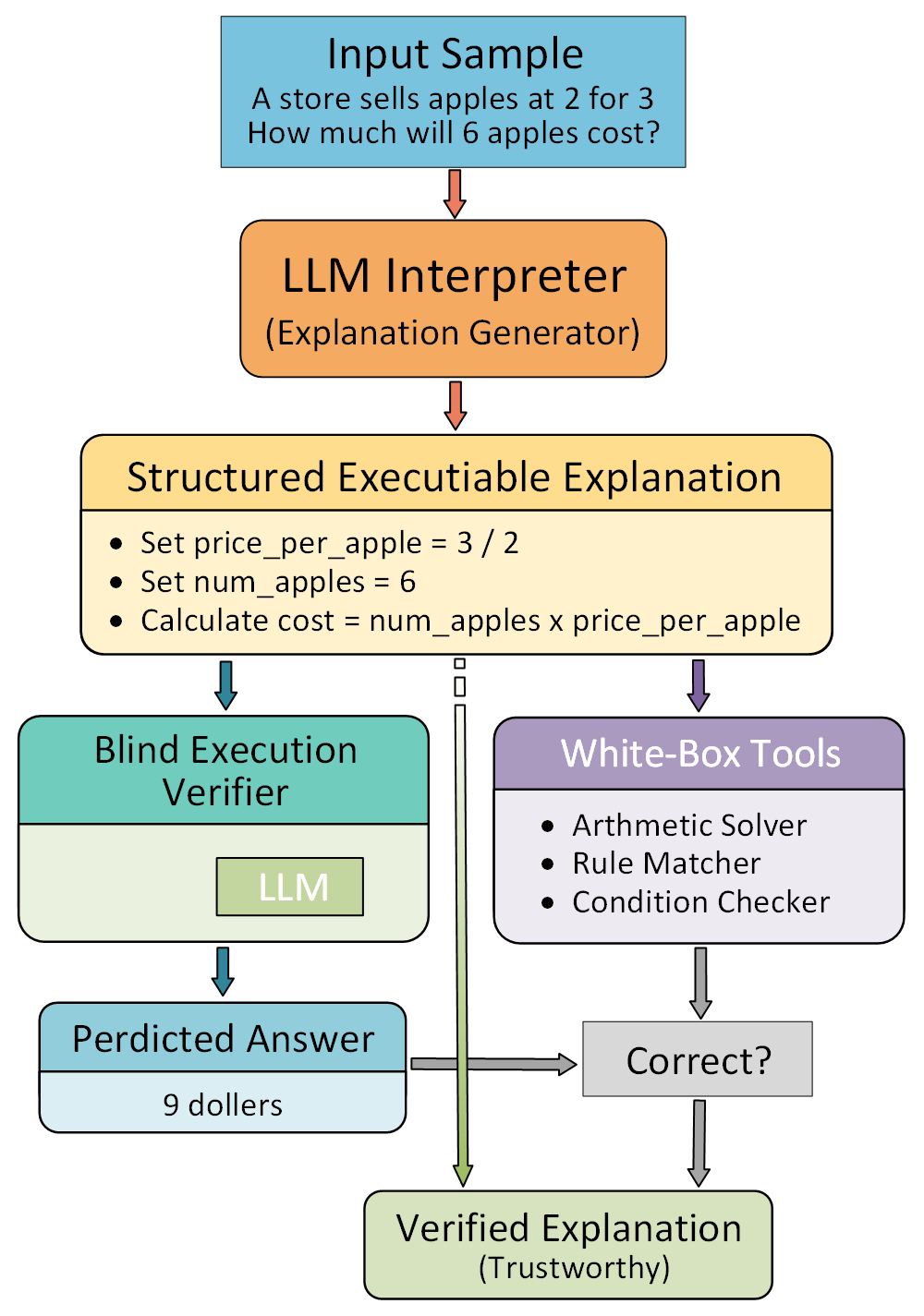
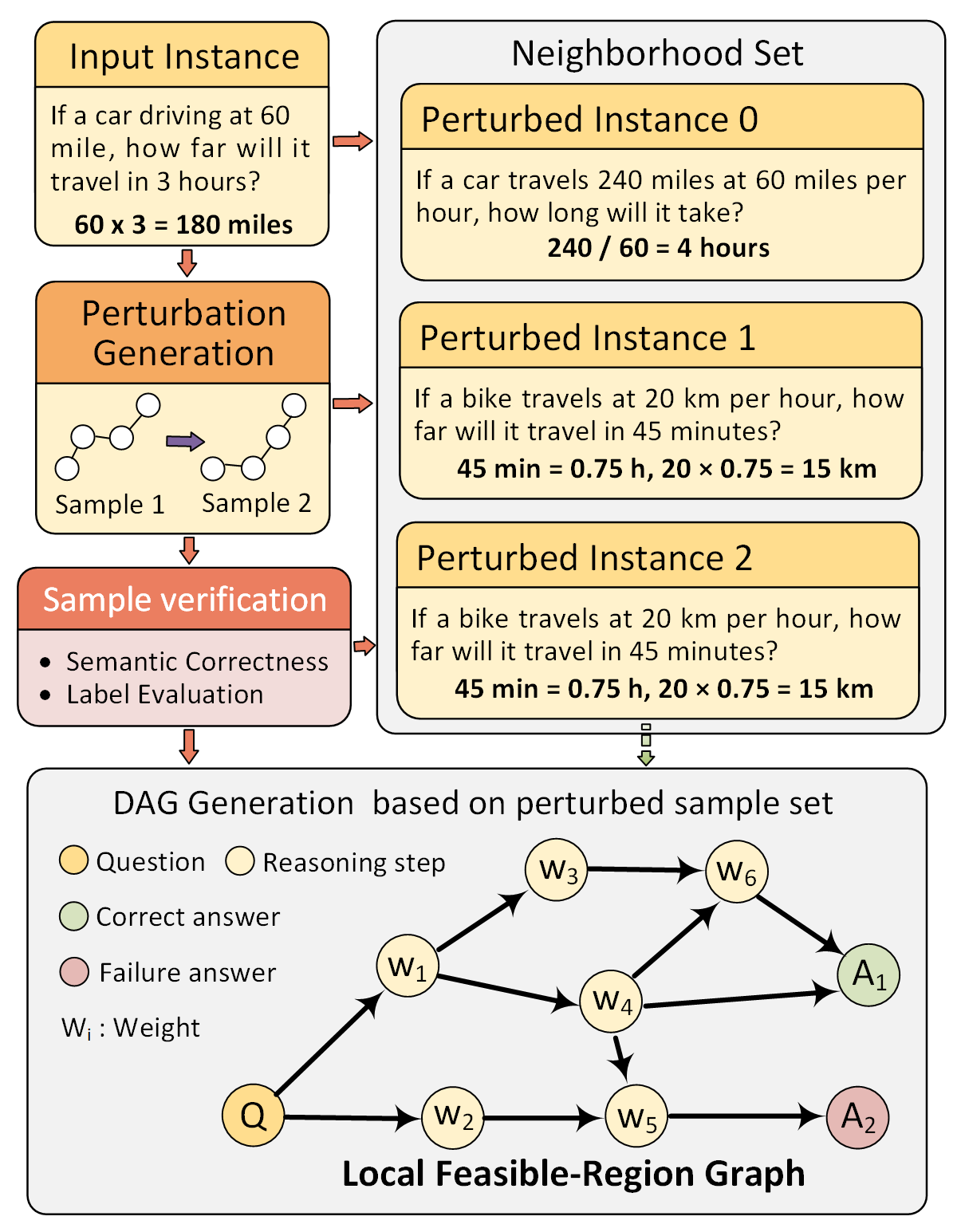
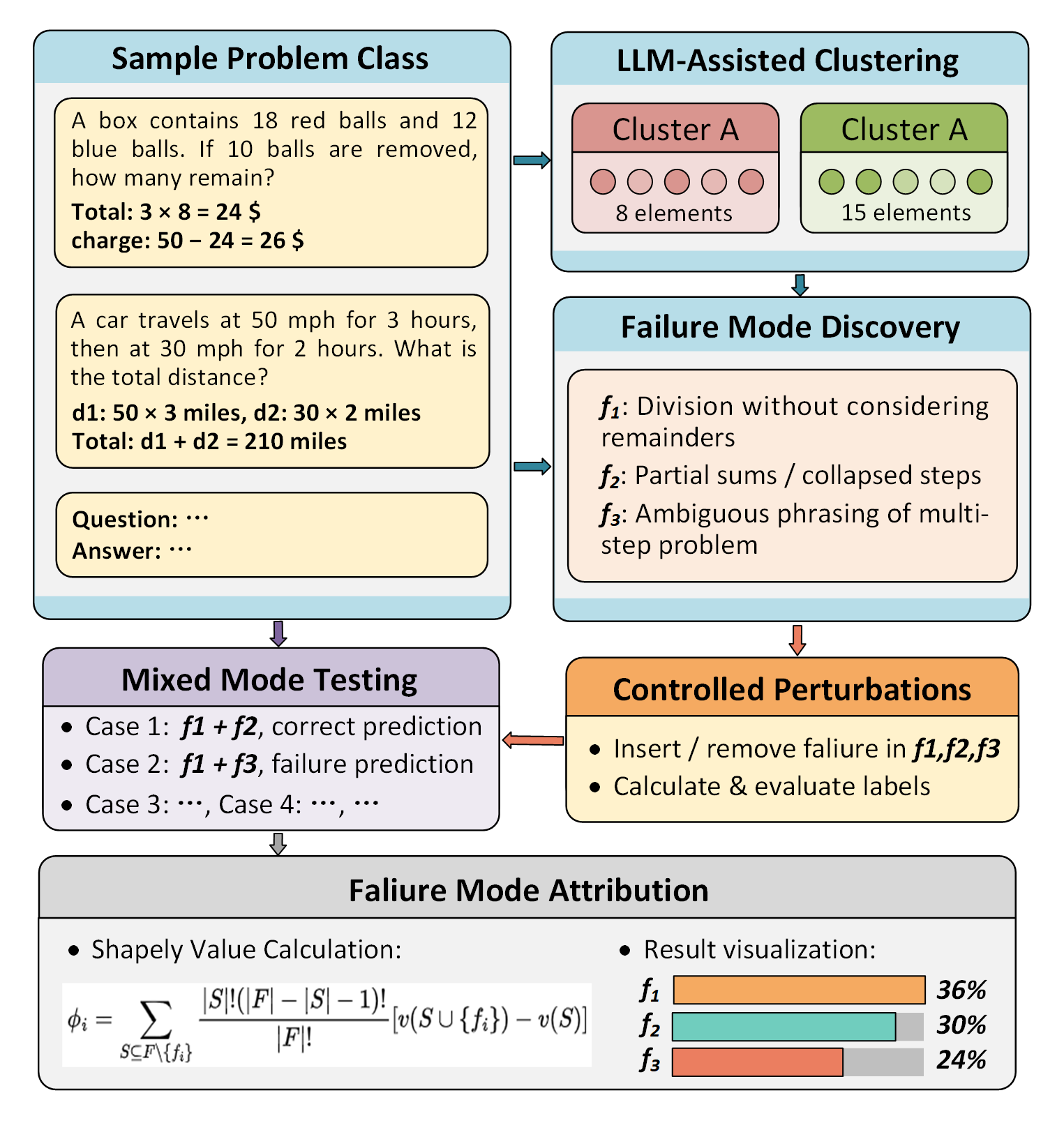
技术框架:TRUE框架包含三个主要模块:1) 可执行推理验证:将推理轨迹转化为可执行的过程规范,并进行盲执行验证,以评估操作的有效性。2) 可行区域DAG建模:通过结构一致的扰动构建可行区域DAG,从而表征推理的稳定性和局部输入空间中的可执行区域。3) 因果失效模式分析:识别重复出现的结构性失效模式,并使用Shapley值量化其因果影响。这三个模块分别从实例、局部结构和类层面提供了可解释性。
关键创新:TRUE框架的关键创新在于其统一的解释框架,它将可执行推理验证、可行区域DAG建模和因果失效模式分析整合在一起,从而提供了多层次、可验证的解释。与现有方法相比,TRUE框架不仅关注单个实例的解释,还关注推理的稳定性和系统性失效模式,从而提供了更全面、深入的理解。
关键设计:在可执行推理验证模块中,关键在于如何将推理轨迹转化为可执行的过程规范,并设计有效的盲执行验证方法。在可行区域DAG建模模块中,关键在于如何选择合适的扰动策略,以及如何构建能够准确表征推理稳定性的DAG结构。在因果失效模式分析模块中,关键在于如何识别重复出现的结构性失效模式,并使用Shapley值准确量化其因果影响。具体的参数设置和网络结构取决于具体的LLM和推理任务。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TRUE框架能够提供多层次、可验证的解释,包括单个实例的可执行推理结构、相邻输入的可行区域表示以及类层面具有量化重要性的可解释失效模式。通过TRUE框架,研究人员可以更深入地了解LLM的推理过程,并识别潜在的风险和偏差,从而提高LLM系统的可靠性和可信度。具体的性能提升数据和对比基线在论文中有详细描述。
🎯 应用场景
TRUE框架可应用于各种需要高可靠性和可解释性的LLM推理场景,例如医疗诊断、金融风控、法律咨询等。通过识别和缓解LLM推理过程中的失效模式,可以提高决策的准确性和公平性,增强用户对LLM系统的信任。未来,该框架可以扩展到其他类型的AI系统,并与其他解释性AI技术相结合,以构建更可靠、可信的智能系统。
📄 摘要(原文)
Large language models (LLMs) have demonstrated strong capabilities in complex reasoning tasks, yet their decision-making processes remain difficult to interpret. Existing explanation methods often lack trustworthy structural insight and are limited to single-instance analysis, failing to reveal reasoning stability and systematic failure mechanisms. To address these limitations, we propose the Trustworthy Unified Explanation Framework (TRUE), which integrates executable reasoning verification, feasible-region directed acyclic graph (DAG) modeling, and causal failure mode analysis. At the instance level, we redefine reasoning traces as executable process specifications and introduce blind execution verification to assess operational validity. At the local structural level, we construct feasible-region DAGs via structure-consistent perturbations, enabling explicit characterization of reasoning stability and the executable region in the local input space. At the class level, we introduce a causal failure mode analysis method that identifies recurring structural failure patterns and quantifies their causal influence using Shapley values. Extensive experiments across multiple reasoning benchmarks demonstrate that the proposed framework provides multi-level, verifiable explanations, including executable reasoning structures for individual instances, feasible-region representations for neighboring inputs, and interpretable failure modes with quantified importance at the class level. These results establish a unified and principled paradigm for improving the interpretability and reliability of LLM reasoning systems.