Prior Aware Memorization: An Efficient Metric for Distinguishing Memorization from Generalization in Large Language Models
作者: Trishita Tiwari, Ari Trachtenberg, G. Edward Suh
分类: cs.LG
发布日期: 2026-02-21
💡 一句话要点
提出Prior-Aware Memorization,高效区分大语言模型中的记忆与泛化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数据泄露 模型记忆 模型泛化 隐私保护 先验概率 训练数据提取
📋 核心要点
- 现有方法难以区分LLM的真实记忆和对常见模式的泛化,导致高估数据泄露风险。
- 提出Prior-Aware Memorization,通过评估后缀与特定前缀的关联强度来识别真实记忆。
- 实验表明,先前被标记为记忆的序列中,高达90%是统计上常见的,强调了考虑模型先验的重要性。
📝 摘要(中文)
大型语言模型(LLM)的训练数据泄露引发了关于隐私、安全和版权合规的严重担忧。评估这种风险的核心挑战在于区分对训练数据的真实记忆和对统计上常见序列的生成。现有的记忆测量方法经常混淆这些现象,即使输出源于对常见模式的泛化,也会将其标记为记忆。Counterfactual Memorization通过比较使用和不使用目标序列训练的模型提供了一个原则性的解决方案,但其依赖于重新训练多个基线模型,导致计算成本高昂且在规模上不切实际。本文提出了Prior-Aware Memorization,这是一种理论上合理、轻量级且无需训练的标准,用于识别LLM中的真实记忆。其核心思想是评估候选后缀是否与其特定训练前缀强烈相关,或者由于统计上的普遍性,它是否以高概率出现在许多不相关的提示中。我们在LLaMA和OPT这两个预训练模型的训练语料库文本上评估了该指标,使用了长序列(模拟版权风险)和命名实体(模拟PII泄露)。结果表明,先前被标记为记忆的序列中,有55%到90%实际上是统计上常见的。SATML训练数据提取挑战数据集也得到了类似的结果,其中大约40%的序列表现出常见的模式行为,尽管它们只在训练数据中出现一次。这些结果表明,仅凭低频率不足以作为记忆的证据,并强调了在评估泄露时考虑模型先验的重要性。
🔬 方法详解
问题定义:现有方法在评估大型语言模型(LLM)的训练数据泄露风险时,难以区分模型对训练数据的真实记忆和对统计上常见序列的生成。这导致许多实际上是模型泛化能力的体现,而非真实记忆的内容,也被错误地标记为“记忆”,从而高估了数据泄露的风险。现有方法,如直接搜索训练数据或使用困惑度等指标,无法有效区分这两种情况。Counterfactual Memorization虽然原则上可行,但需要重新训练多个模型,计算成本过高,难以在大规模场景下应用。
核心思路:Prior-Aware Memorization的核心思路是,如果一个序列仅仅因为在训练数据中出现过就被模型生成,那么它应该与特定的训练前缀有很强的关联。反之,如果一个序列是统计上常见的,那么它即使出现在训练数据中,也可能因为其他原因(例如,在大量不同的上下文中都适用)而被模型生成。因此,该方法通过评估一个候选后缀是否与其特定的训练前缀强烈相关,或者它是否以高概率出现在许多不相关的提示中,来区分真实记忆和统计上的普遍性。
技术框架:该方法不需要重新训练模型,属于一种“训练自由”的方法。其主要流程包括:1) 确定一个候选的“记忆”序列(即,模型生成的序列,可能包含训练数据);2) 提取该序列的前缀(prompt);3) 使用LLM生成该前缀的多个补全(completions);4) 计算候选后缀在这些补全中出现的概率;5) 将该概率与一个阈值进行比较,以确定该后缀是否是由于与特定前缀的强关联而生成,还是由于其统计上的普遍性而生成。
关键创新:该方法最重要的创新点在于引入了“先验感知”(Prior-Aware)的概念,即在评估模型是否“记忆”了某个序列时,需要考虑该序列在整个语言模型中的先验概率(即,不依赖于特定前缀的概率)。这与现有方法只关注序列是否出现在训练数据中,或者模型是否能够生成该序列的思路有本质区别。
关键设计:该方法的关键设计在于如何有效地估计候选后缀的先验概率。论文中可能使用了多种方法,例如,通过随机生成大量不同的前缀,然后观察模型生成候选后缀的频率。此外,阈值的选择也是一个关键参数,它决定了区分“记忆”和“泛化”的边界。具体的损失函数和网络结构与该方法无关,因为它是一种后处理方法,不需要修改模型的训练过程。
🖼️ 关键图片

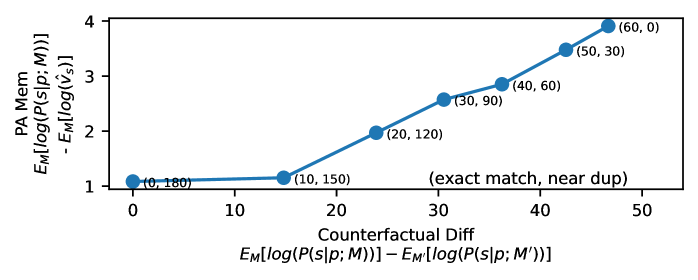
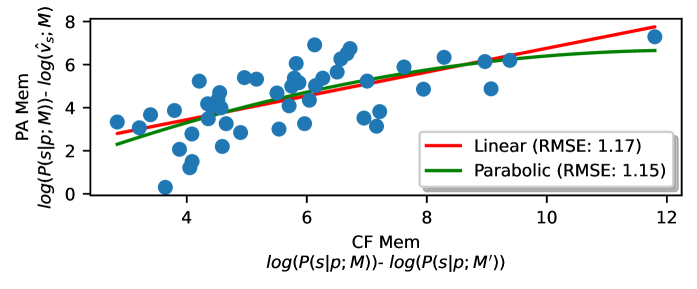
📊 实验亮点
实验结果表明,使用Prior-Aware Memorization方法,可以发现先前被标记为记忆的序列中,有55%到90%实际上是统计上常见的。在SATML训练数据提取挑战数据集上,大约40%的序列表现出常见的模式行为,尽管它们只在训练数据中出现一次。这些结果有力地证明了低频率不足以作为记忆的证据,并突出了考虑模型先验的重要性。
🎯 应用场景
该研究成果可应用于评估和降低大型语言模型的数据泄露风险,尤其是在处理包含个人身份信息(PII)或受版权保护的内容时。通过更准确地识别真实记忆,可以有针对性地采取措施,例如数据脱敏、模型微调或生成内容过滤,从而提高模型的安全性和合规性。此外,该方法还可以用于评估不同模型的记忆能力,为模型选择和部署提供参考。
📄 摘要(原文)
Training data leakage from Large Language Models (LLMs) raises serious concerns related to privacy, security, and copyright compliance. A central challenge in assessing this risk is distinguishing genuine memorization of training data from the generation of statistically common sequences. Existing approaches to measuring memorization often conflate these phenomena, labeling outputs as memorized even when they arise from generalization over common patterns. Counterfactual Memorization provides a principled solution by comparing models trained with and without a target sequence, but its reliance on retraining multiple baseline models makes it computationally expensive and impractical at scale. This work introduces Prior-Aware Memorization, a theoretically grounded, lightweight and training-free criterion for identifying genuine memorization in LLMs. The key idea is to evaluate whether a candidate suffix is strongly associated with its specific training prefix or whether it appears with high probability across many unrelated prompts due to statistical commonality. We evaluate this metric on text from the training corpora of two pre-trained models, LLaMA and OPT, using both long sequences (to simulate copyright risks) and named entities (to simulate PII leakage). Our results show that between 55% and 90% of sequences previously labeled as memorized are in fact statistically common. Similar findings hold for the SATML training data extraction challenge dataset, where roughly 40% of sequences exhibit common-pattern behavior despite appearing only once in the training data. These results demonstrate that low frequency alone is insufficient evidence of memorization and highlight the importance of accounting for model priors when assessing leakage.