In-Context Planning with Latent Temporal Abstractions
作者: Baiting Luo, Yunuo Zhang, Nathaniel S. Keplinger, Samir Gupta, Abhishek Dubey, Ayan Mukhopadhyay
分类: cs.LG, cs.AI
发布日期: 2026-02-21
💡 一句话要点
提出I-TAP,结合上下文适应与在线规划,解决连续控制中随机动态和部分可观测问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 上下文学习 时间抽象 蒙特卡洛树搜索 部分可观测 连续控制 残差量化VAE
📋 核心要点
- 连续控制中的基于规划的强化学习受限于原始时间尺度规划导致的分支过多和长视野问题。
- I-TAP通过学习离散时间抽象空间,结合上下文适应和在线规划,解决环境部分可观测和动态变化问题。
- 实验表明,I-TAP在多种任务中匹配或超越了强大的离线基线,展示了其在随机动态和部分可观测性下的有效性。
📝 摘要(中文)
本文提出I-TAP(In-Context Latent Temporal-Abstraction Planner),一个离线强化学习框架,它将上下文适应与在线规划统一在学习到的离散时间抽象空间中。I-TAP从离线轨迹中学习一个观测条件残差量化VAE,将每个观测-宏动作段压缩成由粗到精的离散残差token堆栈,以及一个时间Transformer,从短期的历史记录中自回归地预测这些token堆栈。由此产生的序列模型同时充当抽象动作的上下文条件先验和潜在动态模型。在测试时,I-TAP直接在token空间中执行蒙特卡洛树搜索,使用短历史进行隐式适应而无需梯度更新,并将所选的token堆栈解码为可执行的动作。在确定性MuJoCo、具有episode潜在动态机制的随机MuJoCo以及高维Adroit操作(包括部分可观测变体)中,I-TAP始终匹配或优于强大的无模型和基于模型的离线基线,展示了在随机动态和部分可观测性下高效且鲁棒的上下文规划。
🔬 方法详解
问题定义:现有的基于规划的强化学习方法在连续控制任务中面临两个主要挑战:一是原始时间尺度上的规划会导致巨大的分支因子和过长的规划视野,计算成本高昂;二是真实环境通常是部分可观测的,并且存在动态机制的转变,使得静态、完全可观测的动态假设失效。因此,如何在部分可观测和动态变化的环境中进行高效的规划是一个关键问题。
核心思路:I-TAP的核心思路是学习一个离散的、抽象的时间动作空间,并在这个空间中进行规划。通过将连续的观测和动作序列压缩成离散的token序列,I-TAP能够降低规划的复杂性,并利用Transformer模型学习token之间的动态关系。此外,I-TAP利用上下文学习能力,通过短期的历史信息来适应环境的变化,而无需进行梯度更新。
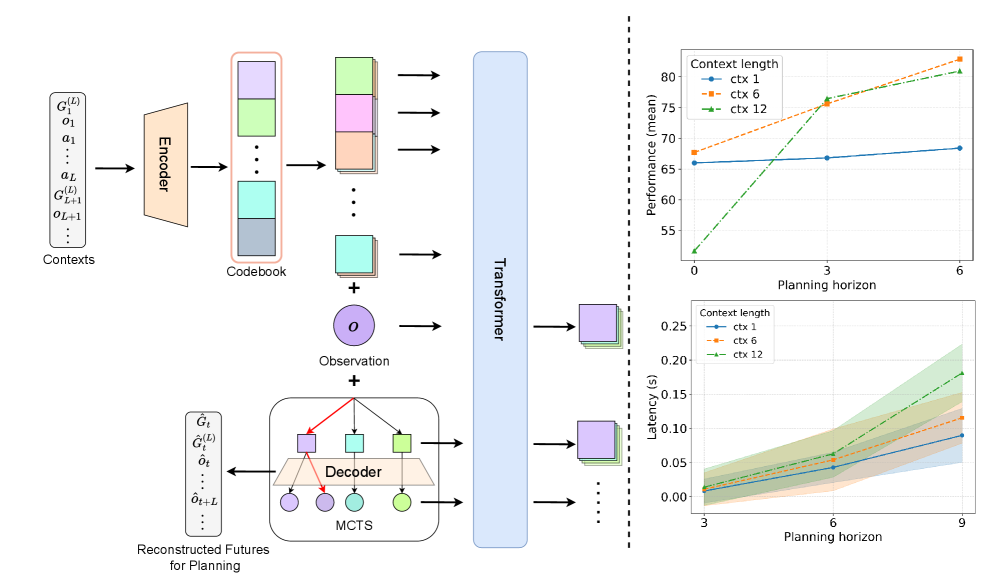
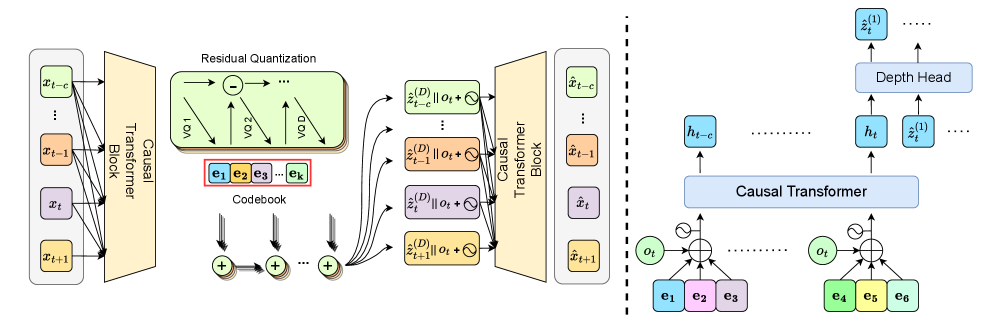
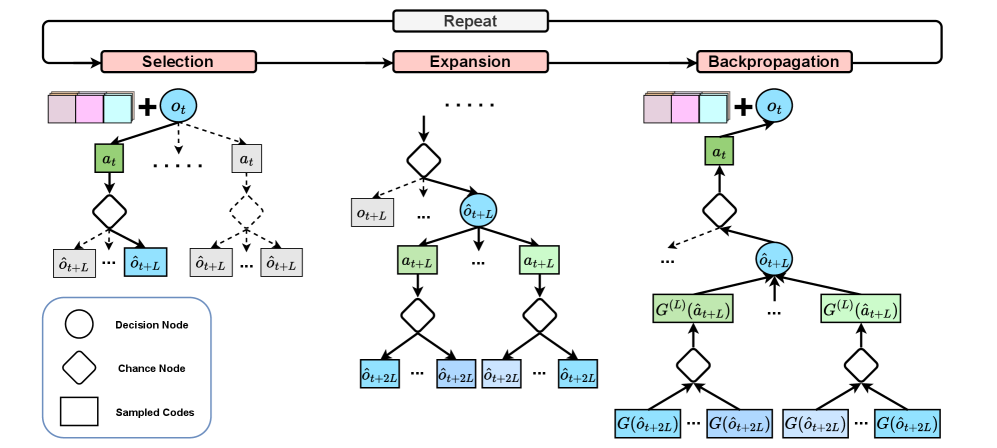
技术框架:I-TAP的整体框架包含以下几个主要模块:1) 离线数据收集:收集环境中的轨迹数据。2) 观测条件残差量化VAE:学习将观测-宏动作段压缩成离散的token堆栈。3) 时间Transformer:学习从短期的历史记录中自回归地预测token堆栈,作为潜在动态模型。4) 在线规划:在token空间中执行蒙特卡洛树搜索,选择最优的token序列。5) 动作解码:将选择的token堆栈解码为可执行的动作。
关键创新:I-TAP的关键创新在于将上下文学习和在线规划结合在一个学习到的离散时间抽象空间中。与传统的基于模型的强化学习方法相比,I-TAP不需要显式地建模环境的动态特性,而是通过Transformer模型学习token之间的隐式关系。此外,I-TAP利用上下文学习能力,能够快速适应环境的变化,而无需进行梯度更新。
关键设计:I-TAP使用残差量化VAE来学习离散的token表示,通过多层量化器逐步细化token的表示。时间Transformer使用标准的Transformer架构,通过自注意力机制学习token之间的依赖关系。蒙特卡洛树搜索使用UCT算法进行节点选择,并使用Transformer模型预测的token概率作为先验信息。动作解码器将token序列解码为连续的动作序列。
🖼️ 关键图片
📊 实验亮点
实验结果表明,I-TAP在确定性MuJoCo、随机MuJoCo和高维Adroit操作等多个任务中,均能匹配或超越强大的无模型和基于模型的离线基线。例如,在部分可观测的Adroit操作任务中,I-TAP的性能显著优于其他基线方法,证明了其在复杂环境中的有效性。
🎯 应用场景
I-TAP具有广泛的应用前景,例如机器人操作、自动驾驶、游戏AI等领域。该方法能够有效地解决环境部分可观测和动态变化的问题,提高智能体在复杂环境中的适应性和鲁棒性。此外,I-TAP的离线学习框架使其能够利用大量的离线数据进行训练,降低了在线学习的成本。
📄 摘要(原文)
Planning-based reinforcement learning for continuous control is bottlenecked by two practical issues: planning at primitive time scales leads to prohibitive branching and long horizons, while real environments are frequently partially observable and exhibit regime shifts that invalidate stationary, fully observed dynamics assumptions. We introduce I-TAP (In-Context Latent Temporal-Abstraction Planner), an offline RL framework that unifies in-context adaptation with online planning in a learned discrete temporal-abstraction space. From offline trajectories, I-TAP learns an observation-conditioned residual-quantization VAE that compresses each observation-macro-action segment into a coarse-to-fine stack of discrete residual tokens, and a temporal Transformer that autoregressively predicts these token stacks from a short recent history. The resulting sequence model acts simultaneously as a context-conditioned prior over abstract actions and a latent dynamics model. At test time, I-TAP performs Monte Carlo Tree Search directly in token space, using short histories for implicit adaptation without gradient update, and decodes selected token stacks into executable actions. Across deterministic MuJoCo, stochastic MuJoCo with per-episode latent dynamics regimes, and high-dimensional Adroit manipulation, including partially observable variants, I-TAP consistently matches or outperforms strong model-free and model-based offline baselines, demonstrating efficient and robust in-context planning under stochastic dynamics and partial observability.