Transformers for dynamical systems learn transfer operators in-context
作者: Anthony Bao, Jeffrey Lai, William Gilpin
分类: cs.LG, nlin.CD
发布日期: 2026-02-21
备注: 6 pages, 3 figures
💡 一句话要点
Transformer通过上下文学习动力系统传递算子,实现零样本预测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 动力系统 Transformer 上下文学习 零样本学习 传递算子
📋 核心要点
- 现有方法难以实现动力系统在不同物理环境下的零样本预测,阻碍了模型的泛化能力。
- 利用Transformer的注意力机制,通过上下文学习,实现动力系统传递算子的学习和预测。
- 实验表明,该方法能够在未见过的动力系统上实现有效的预测,揭示了Transformer的泛化能力。
📝 摘要(中文)
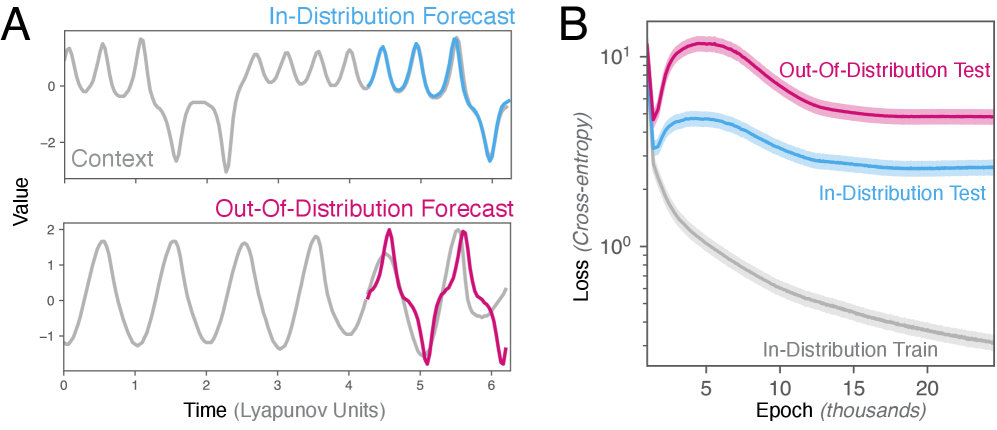
大规模科学机器学习基础模型能够适应训练期间未见过的物理环境,例如湍流尺度之间的零样本迁移。这种上下文学习现象挑战了传统对物理系统中学习和适应的理解。本文研究了动力系统的上下文学习,在一个最小的环境中:训练一个小的两层单头Transformer来预测一个动力系统,然后评估其在不重新训练的情况下预测不同动力系统的能力。研究发现,在训练中,分布内和分布外性能之间存在早期的权衡,表现为二次双下降现象。研究发现,基于注意力的模型在上下文中应用传递算子预测策略,包括:(1) 使用延迟嵌入提升低维时间序列,以检测系统的高维动力流形;(2) 识别和预测表征该流形上全局流的长期不变集。研究结果阐明了大型预训练模型在测试时无需重新训练即可预测未见过的物理系统的机制,并说明了基于注意力的模型利用全局吸引子信息进行短期预测的独特能力。
🔬 方法详解
问题定义:论文旨在解决动力系统预测中的零样本迁移问题。现有方法在面对训练数据之外的动力系统时,通常需要重新训练,泛化能力较差。痛点在于如何让模型能够快速适应新的动力系统,而无需大量的重新训练。
核心思路:论文的核心思路是利用Transformer的上下文学习能力,将动力系统的预测问题转化为一个传递算子的学习问题。通过学习一个动力系统,然后将其知识迁移到另一个动力系统上,实现零样本预测。核心在于利用注意力机制捕捉动力系统的全局信息,并学习其内在的动力学规律。
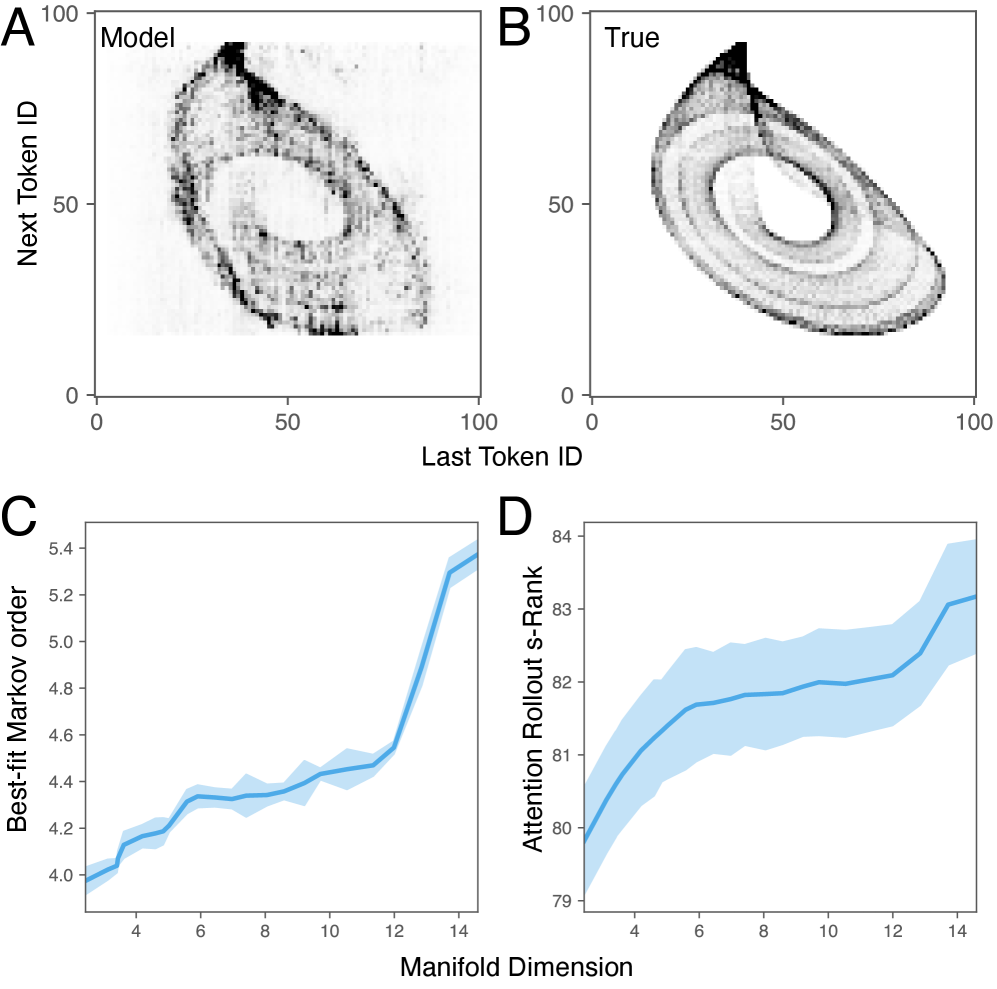
技术框架:整体框架包括以下几个阶段:1) 数据准备:将动力系统的时间序列数据进行延迟嵌入,以重构高维动力流形。2) 模型训练:使用一个小的两层单头Transformer进行训练,目标是预测下一个时间步的状态。3) 上下文学习:在测试阶段,将新的动力系统的时间序列输入到训练好的Transformer中,利用其上下文学习能力进行预测。4) 结果分析:分析Transformer的注意力权重,以理解其学习到的动力学规律。
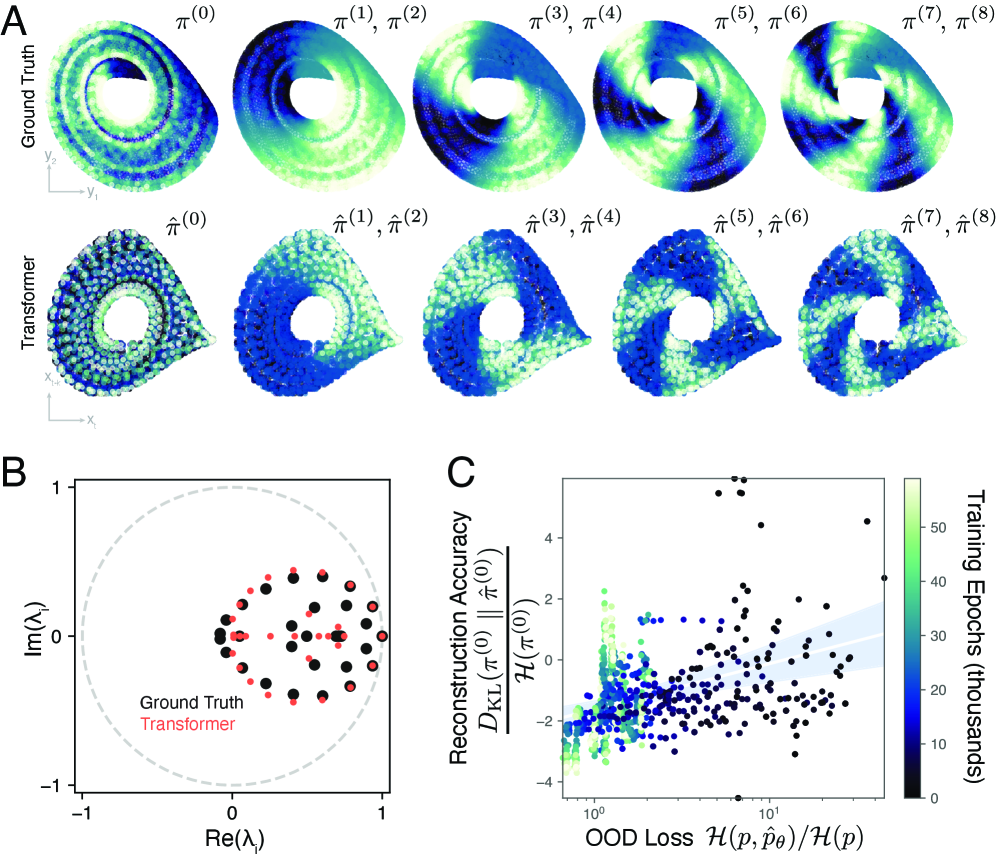
关键创新:最重要的技术创新点在于发现了Transformer在动力系统预测中应用传递算子的能力。具体来说,Transformer能够通过注意力机制捕捉动力系统的全局信息,并学习其不变集,从而实现对新动力系统的零样本预测。与现有方法的本质区别在于,现有方法通常需要针对每个动力系统进行单独训练,而该方法能够实现知识的迁移。
关键设计:论文使用了一个小的两层单头Transformer,以降低计算成本并提高可解释性。延迟嵌入的维数是一个关键参数,需要根据动力系统的复杂程度进行调整。损失函数采用均方误差,以衡量预测值与真实值之间的差距。注意力机制采用标准的Scaled Dot-Product Attention。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法能够在未见过的动力系统上实现有效的预测,验证了Transformer的泛化能力。研究发现,在训练过程中,分布内和分布外性能之间存在权衡,表现为二次双下降现象。此外,研究还揭示了Transformer通过注意力机制学习动力系统不变集的机制。
🎯 应用场景
该研究成果可应用于各种动力系统的预测和控制,例如天气预报、交通流量预测、金融市场分析等。通过利用预训练模型,可以快速适应新的动力系统,降低建模成本,提高预测精度。未来,该方法有望应用于更复杂的物理系统,例如湍流、气候变化等。
📄 摘要(原文)
Large-scale foundation models for scientific machine learning adapt to physical settings unseen during training, such as zero-shot transfer between turbulent scales. This phenomenon, in-context learning, challenges conventional understanding of learning and adaptation in physical systems. Here, we study in-context learning of dynamical systems in a minimal setting: we train a small two-layer, single-head transformer to forecast one dynamical system, and then evaluate its ability to forecast a different dynamical system without retraining. We discover an early tradeoff in training between in-distribution and out-of-distribution performance, which manifests as a secondary double descent phenomenon. We discover that attention-based models apply a transfer-operator forecasting strategy in-context. They (1) lift low-dimensional time series using delay embedding, to detect the system's higher-dimensional dynamical manifold, and (2) identify and forecast long-lived invariant sets that characterize the global flow on this manifold. Our results clarify the mechanism enabling large pretrained models to forecast unseen physical systems at test without retraining, and they illustrate the unique ability of attention-based models to leverage global attractor information in service of short-term forecasts.