Learning Invariant Visual Representations for Planning with Joint-Embedding Predictive World Models
作者: Leonardo F. Toso, Davit Shadunts, Yunyang Lu, Nihal Sharma, Donglin Zhan, Nam H. Nguyen, James Anderson
分类: cs.LG
发布日期: 2026-02-20
💡 一句话要点
提出基于双仿真的联合嵌入预测世界模型,提升规划在视觉干扰下的鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 视觉表征学习 双仿真 鲁棒性 联合嵌入 预测模型 机器人导航
📋 核心要点
- 现有基于视觉的世界模型对背景变化等“慢特征”敏感,导致泛化能力不足。
- 提出一种基于双仿真的联合嵌入预测模型,通过状态等价性约束抑制慢特征的影响。
- 实验表明,该模型在导航任务中对视觉干扰具有更强的鲁棒性,且潜在空间更小。
📝 摘要(中文)
本文针对基于高维视觉观测学习的世界模型在规划任务中,因对“慢特征”(如背景变化和干扰物)敏感而导致的测试时鲁棒性下降问题,提出了一种改进方案。该方案通过引入一个双仿真的编码器来增强预测目标,该编码器强制执行控制相关的状态等价性,将具有相似转移动态的状态映射到附近的潜在状态,同时限制慢特征的贡献。在不同背景变化和视觉干扰下的导航任务中,该模型始终提高了对慢特征的鲁棒性,同时在比DINO-WM小10倍的潜在空间中运行。此外,该模型与DINOv2、SimDINOv2和iBOT特征等预训练视觉编码器的选择无关,并保持鲁棒性。
🔬 方法详解
问题定义:论文旨在解决在视觉世界模型中,由于模型对与任务无关的“慢特征”(例如背景变化、光照变化、干扰物等)过于敏感,导致在测试环境中泛化能力差的问题。现有的联合嵌入预测架构(JEPAs),例如DINO世界模型(DINO-WM),虽然避免了像素级别的重建,但在面对这些慢特征时,性能会显著下降。
核心思路:论文的核心思路是通过引入双仿真(Bisimulation)的概念,强制模型学习控制相关的状态等价性。具体来说,如果两个状态在控制作用下产生相似的未来轨迹,那么它们应该在潜在空间中被映射到相近的位置。这样可以有效地抑制那些不影响控制策略的慢特征,从而提高模型的鲁棒性。
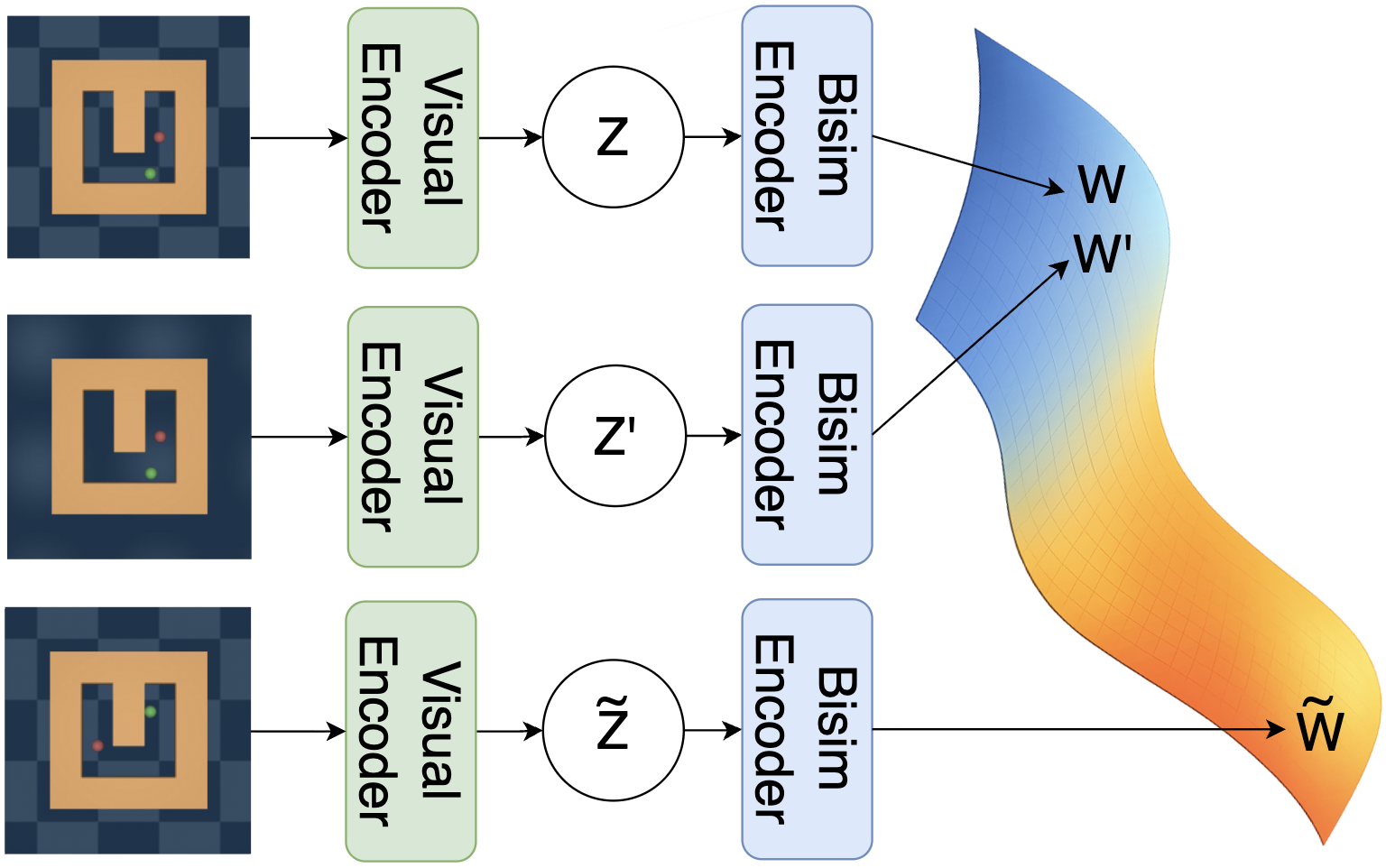
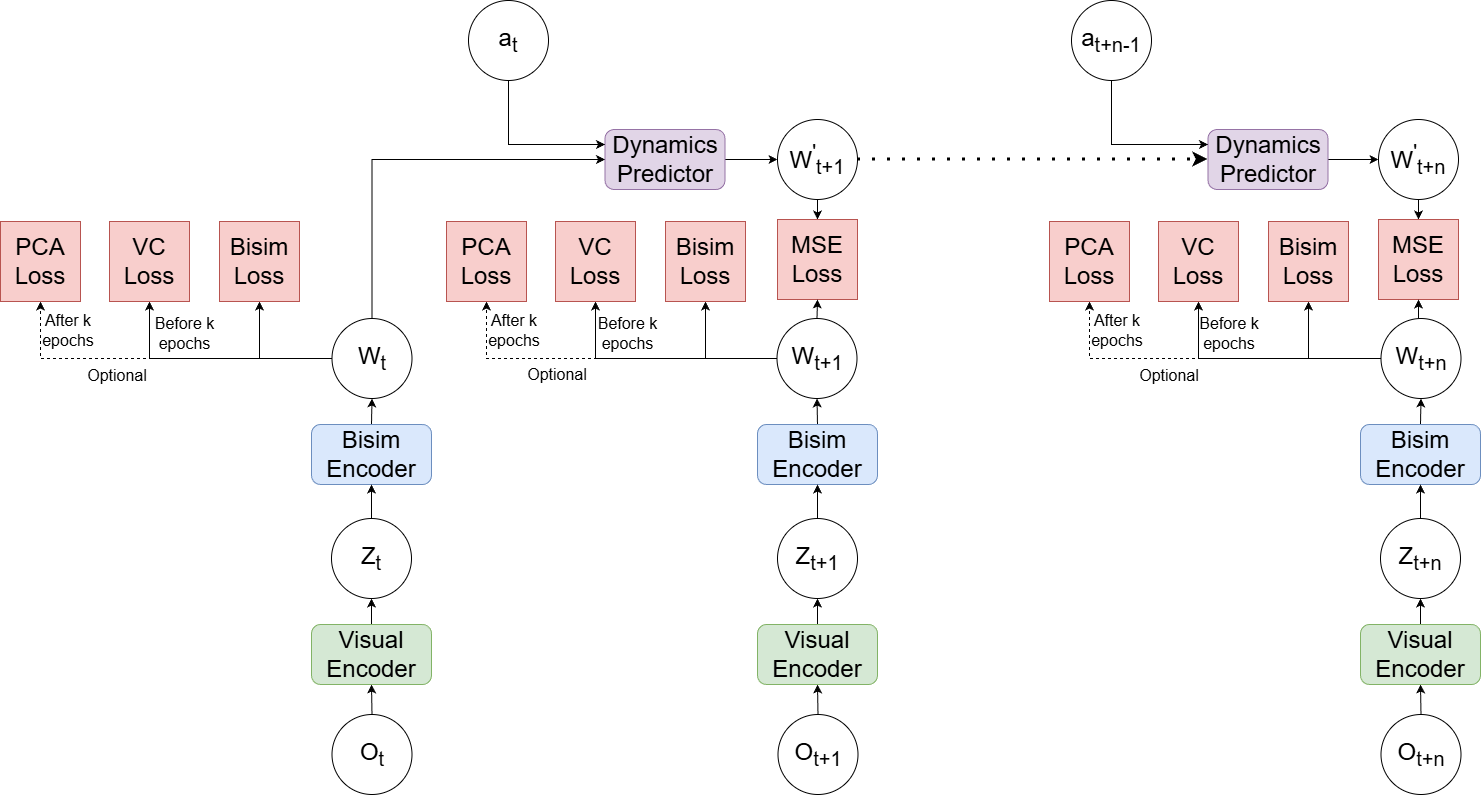
技术框架:整体框架包括一个预训练的视觉编码器、一个双仿真的编码器和一个预测模型。首先,视觉编码器将原始图像转换为视觉特征。然后,双仿真的编码器将视觉特征映射到潜在状态空间,并在此过程中强制执行状态等价性。最后,预测模型利用潜在状态来预测未来的状态。整个训练过程通过联合优化预测损失和双仿真损失来实现。
关键创新:论文的关键创新在于将双仿真的概念引入到联合嵌入预测世界模型中,从而有效地提高了模型对慢特征的鲁棒性。与传统的只关注预测准确性的方法不同,该方法显式地约束了潜在状态空间的结构,使得相似的状态具有相似的转移动态。
关键设计:双仿真损失函数是关键的设计之一。该损失函数鼓励具有相似转移动态的状态在潜在空间中彼此靠近。具体来说,对于两个状态s1和s2,以及一个控制动作a,如果s1和s2在执行动作a后转移到的下一个状态s1'和s2'也很相似,那么s1和s2应该在潜在空间中彼此靠近。论文中使用了对比学习的方式来计算双仿真损失,通过最小化正样本对之间的距离,最大化负样本对之间的距离。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该模型在不同背景变化和视觉干扰下的导航任务中,始终提高了对慢特征的鲁棒性。与DINO-WM相比,该模型可以在小10倍的潜在空间中运行,同时保持或提高性能。此外,该模型与不同的预训练视觉编码器(DINOv2、SimDINOv2和iBOT)结合使用时,均能保持鲁棒性,表明其具有良好的通用性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶等领域,尤其是在复杂、多变的现实环境中。通过提高模型对视觉干扰的鲁棒性,可以使机器人在更真实、更具挑战性的场景中做出更可靠的决策,从而提升系统的安全性和效率。此外,该方法还可以推广到其他需要从高维感官数据中学习控制策略的任务中。
📄 摘要(原文)
World models learned from high-dimensional visual observations allow agents to make decisions and plan directly in latent space, avoiding pixel-level reconstruction. However, recent latent predictive architectures (JEPAs), including the DINO world model (DINO-WM), display a degradation in test time robustness due to their sensitivity to "slow features". These include visual variations such as background changes and distractors that are irrelevant to the task being solved. We address this limitation by augmenting the predictive objective with a bisimulation encoder that enforces control-relevant state equivalence, mapping states with similar transition dynamics to nearby latent states while limiting contributions from slow features. We evaluate our model on a simple navigation task under different test-time background changes and visual distractors. Across all benchmarks, our model consistently improves robustness to slow features while operating in a reduced latent space, up to 10x smaller than that of DINO-WM. Moreover, our model is agnostic to the choice of pretrained visual encoder and maintains robustness when paired with DINOv2, SimDINOv2, and iBOT features.