Quantum Maximum Likelihood Prediction via Hilbert Space Embeddings
作者: Sreejith Sreekumar, Nir Weinberger
分类: cs.IT, cs.LG, quant-ph, stat.ML
发布日期: 2026-02-20
备注: 32+4 pages, 1 figure
💡 一句话要点
提出基于希尔伯特空间嵌入的量子最大似然预测框架,用于统一处理经典和量子LLM。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量子机器学习 大型语言模型 上下文学习 最大似然估计 希尔伯特空间 量子信息论 密度算子 非渐近分析
📋 核心要点
- 现有对LLM上下文预测能力的解释不足,缺乏统一的理论框架。
- 将训练视为概率分布到量子密度算子的嵌入,上下文学习为量子模型上的最大似然预测。
- 推导了非渐近性能保证,并提供了一个统一处理经典和量子LLM的框架。
📝 摘要(中文)
本文从信息几何和统计的角度,为现代大型语言模型(LLM)的上下文预测能力提出了另一种概念视角。受Bach[2023]的启发,我们将训练建模为学习概率分布到量子密度算子空间的嵌入,并将上下文学习建模为指定类别的量子模型上的最大似然预测。当量子模型类别足够具有表达性时,我们用量子逆信息投影和量子毕达哥拉斯定理来解释这个预测器。此外,我们还在迹范数和量子相对熵方面推导了非渐近性能保证,包括收敛速度和集中不等式。我们的方法提供了一个统一的框架来处理经典和量子LLM。
🔬 方法详解
问题定义:论文旨在解决对大型语言模型(LLM)的上下文学习能力缺乏统一理论解释的问题。现有方法往往针对特定模型或任务,缺乏一般性和理论支撑。论文试图从信息几何和统计的角度,建立一个统一的框架来理解和分析LLM的上下文学习能力。
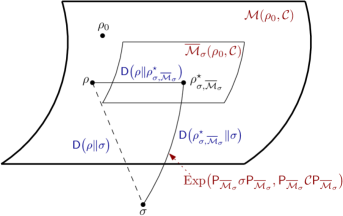
核心思路:论文的核心思路是将训练过程视为学习概率分布到量子密度算子空间的嵌入。具体来说,每个上下文(context)被映射到一个量子态,而预测过程则被建模为在量子态空间中寻找与给定上下文最匹配的量子模型。这种基于量子力学的视角能够提供更丰富的数学工具和理论框架,从而更好地理解LLM的内在机制。
技术框架:该框架主要包含以下几个阶段:1) 将训练数据表示为概率分布;2) 将概率分布嵌入到量子密度算子空间,得到相应的量子态表示;3) 定义一类量子模型,用于描述上下文与预测之间的关系;4) 利用最大似然估计,在量子模型类别中寻找最优模型,用于进行上下文预测;5) 利用量子逆信息投影和量子毕达哥拉斯定理对预测器进行解释和分析。
关键创新:论文最重要的技术创新在于将LLM的上下文学习问题转化为了量子密度算子空间中的最大似然预测问题。这种转化不仅提供了一个新的视角来理解LLM,还引入了量子信息论中的工具和理论,例如量子逆信息投影和量子毕达哥拉斯定理,从而能够更深入地分析LLM的性能。与现有方法相比,该方法具有更强的理论基础和更广泛的适用性。
关键设计:论文的关键设计包括:1) 选择合适的量子密度算子空间来嵌入概率分布;2) 定义合适的量子模型类别,以捕捉上下文与预测之间的关系;3) 推导最大似然估计的解析解或近似解;4) 利用迹范数和量子相对熵等指标来评估模型的性能,并推导非渐近性能保证。
🖼️ 关键图片
📊 实验亮点
论文推导了非渐近性能保证,包括收敛速度和集中不等式,为量子最大似然预测的性能提供了理论支撑。通过迹范数和量子相对熵等指标,对模型的性能进行了评估,并证明了该方法在理论上的优越性。具体实验数据未知,但理论分析表明该方法具有良好的收敛性和泛化能力。
🎯 应用场景
该研究成果可应用于量子自然语言处理、量子机器学习等领域,有助于设计更高效、更鲁棒的量子LLM。此外,该框架也为理解经典LLM的内在机制提供了新的思路,有助于改进现有LLM的性能和可解释性。未来,该研究或可促进经典和量子计算在自然语言处理领域的融合。
📄 摘要(原文)
Recent works have proposed various explanations for the ability of modern large language models (LLMs) to perform in-context prediction. We propose an alternative conceptual viewpoint from an information-geometric and statistical perspective. Motivated by Bach[2023], we model training as learning an embedding of probability distributions into the space of quantum density operators, and in-context learning as maximum-likelihood prediction over a specified class of quantum models. We provide an interpretation of this predictor in terms of quantum reverse information projection and quantum Pythagorean theorem when the class of quantum models is sufficiently expressive. We further derive non-asymptotic performance guarantees in terms of convergence rates and concentration inequalities, both in trace norm and quantum relative entropy. Our approach provides a unified framework to handle both classical and quantum LLMs.