On the Semantic and Syntactic Information Encoded in Proto-Tokens for One-Step Text Reconstruction
作者: Ivan Bondarenko, Egor Palkin, Fedor Tikunov
分类: cs.LG, cs.CL
发布日期: 2026-02-20
💡 一句话要点
研究Proto-Tokens中编码的语义和句法信息,探索单步文本重建的非自回归路径。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 单步文本重建 Proto-Token 非自回归生成 语义控制 关系蒸馏
📋 核心要点
- 传统自回归LLM生成文本效率低,需要多次前向传播,限制了生成速度。
- 该论文探索使用少量proto-token一步重建文本,旨在突破自回归范式,提升生成效率。
- 实验分析了proto-token的语义和句法信息编码方式,并提出了正则化方法来控制语义结构。
📝 摘要(中文)
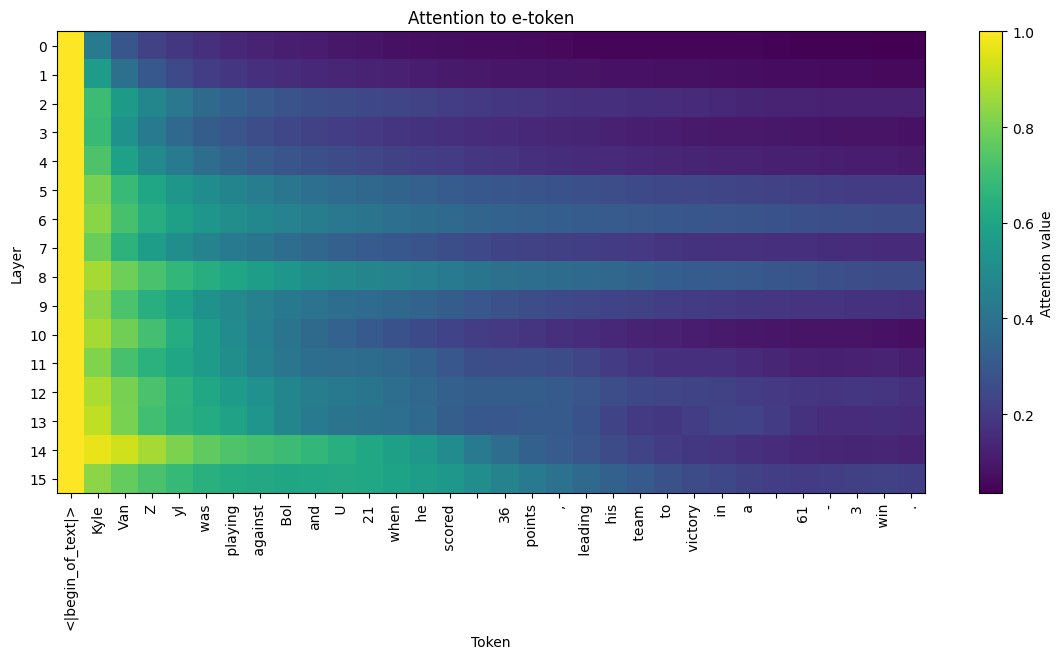
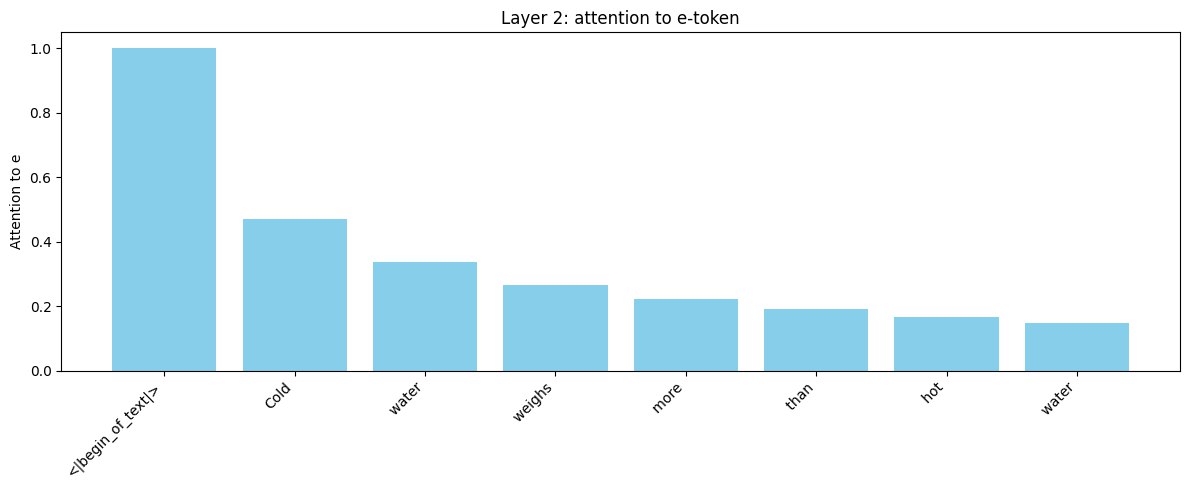
自回归大型语言模型(LLM)逐token生成文本,生成长度为n的序列需要n次前向传递。最近的研究表明,冻结的LLM可以通过单个前向传递,仅从两个学习到的proto-token重建数百个token,这为超越自回归范式提供了一种可能。本文研究了这些proto-token编码了哪些信息,以及它们在重建和受控约束下的行为。我们进行了一系列实验,旨在解耦两个proto-token中的语义和句法内容,分析e-token的稳定性,并可视化重建过程中对e-token的注意力模式。最后,我们测试了两种正则化方案,使用教师嵌入对e-token“施加”语义结构,包括基于锚点的损失和关系蒸馏目标。结果表明,在标准优化下,m-token比e-token更倾向于捕获语义信息;基于锚点的约束会显著降低重建精度;关系蒸馏可以将批次级别的语义关系转移到proto-token空间,而不会牺牲重建质量,这支持了未来非自回归seq2seq系统的可行性,该系统将proto-token预测作为中间表示。
🔬 方法详解
问题定义:论文旨在研究如何利用少量(两个)proto-token,通过单步前向传播,重建大量文本token。现有自回归LLM的痛点在于生成速度慢,因为需要逐个token生成,效率低下。该研究探索一种非自回归的文本生成方法,以提升生成速度。
核心思路:论文的核心思路是利用LLM的潜在能力,学习两个特殊的token(proto-token),使其能够编码足够的信息,从而在单步前向传播中重建完整的文本序列。通过分析这两个token的特性,并施加约束,可以控制生成文本的语义和句法。
技术框架:整体框架基于已有的研究工作,即利用冻结的LLM进行文本重建。主要包含以下几个阶段:1) 学习两个proto-token(m-token和e-token);2) 将这两个token输入到冻结的LLM中;3) LLM利用这两个token重建文本序列;4) 分析proto-token的特性,例如语义和句法信息的编码方式;5) 通过正则化方法,对proto-token施加语义约束。
关键创新:最重要的技术创新点在于对proto-token的语义和句法信息进行解耦和控制。论文通过实验分析了m-token和e-token分别编码的信息类型,并提出了基于锚点的损失和关系蒸馏目标,来对e-token施加语义约束。与现有方法的本质区别在于,该方法不再依赖自回归生成,而是通过学习proto-token来一次性生成整个序列。
关键设计:论文的关键设计包括:1) 使用基于锚点的损失函数,将e-token与预定义的语义锚点对齐,从而控制其语义信息;2) 使用关系蒸馏目标,将批次级别的语义关系从教师模型转移到proto-token空间;3) 分析注意力模式,观察LLM在重建过程中如何利用proto-token的信息;4) 通过实验评估不同正则化方法对重建精度和语义控制的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在标准优化下,m-token倾向于捕获更多的语义信息。基于锚点的约束会显著降低重建精度,而关系蒸馏可以在不牺牲重建质量的前提下,将批次级别的语义关系转移到proto-token空间。这些结果验证了通过正则化方法控制proto-token语义信息的可行性。
🎯 应用场景
该研究成果可应用于需要快速文本生成的场景,例如机器翻译、文本摘要、对话系统等。通过减少前向传播的次数,可以显著提升生成速度,降低计算成本。此外,该研究为非自回归序列生成提供了一种新的思路,有望推动相关领域的发展。
📄 摘要(原文)
Autoregressive large language models (LLMs) generate text token-by-token, requiring n forward passes to produce a sequence of length n. Recent work, Exploring the Latent Capacity of LLMs for One-Step Text Reconstruction (Mezentsev and Oseledets), shows that frozen LLMs can reconstruct hundreds of tokens from only two learned proto-tokens in a single forward pass, suggesting a path beyond the autoregressive paradigm. In this paper, we study what information these proto-tokens encode and how they behave under reconstruction and controlled constraints. We perform a series of experiments aimed at disentangling semantic and syntactic content in the two proto-tokens, analyzing stability properties of the e-token, and visualizing attention patterns to the e-token during reconstruction. Finally, we test two regularization schemes for "imposing" semantic structure on the e-token using teacher embeddings, including an anchor-based loss and a relational distillation objective. Our results indicate that the m-token tends to capture semantic information more strongly than the e-token under standard optimization; anchor-based constraints trade off sharply with reconstruction accuracy; and relational distillation can transfer batch-level semantic relations into the proto-token space without sacrificing reconstruction quality, supporting the feasibility of future non-autoregressive seq2seq systems that predict proto-tokens as an intermediate representation.