[Re] Benchmarking LLM Capabilities in Negotiation through Scoreable Games
作者: Jorge Carrasco Pollo, Ioannis Kapetangeorgis, Joshua Rosenthal, John Hua Yao
分类: cs.LG, cs.AI
发布日期: 2026-02-20
备注: Accepted for publication at Transactions on Machine Learning Research (TMLR) and MLRC Journal Track, 2025. Code available at: https://github.com/joshrosie/FACT29
期刊: Transactions on Machine Learning Research (TMLR), June 2025
💡 一句话要点
复现与扩展LLM谈判能力基准测试,揭示模型评估的客观性挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多智能体谈判 基准测试 可重复性 模型评估
📋 核心要点
- 现有LLM谈判评估缺乏稳健性和通用性,难以客观比较不同模型。
- 通过复现和扩展Scoreable Games基准,深入分析LLM在谈判中的表现。
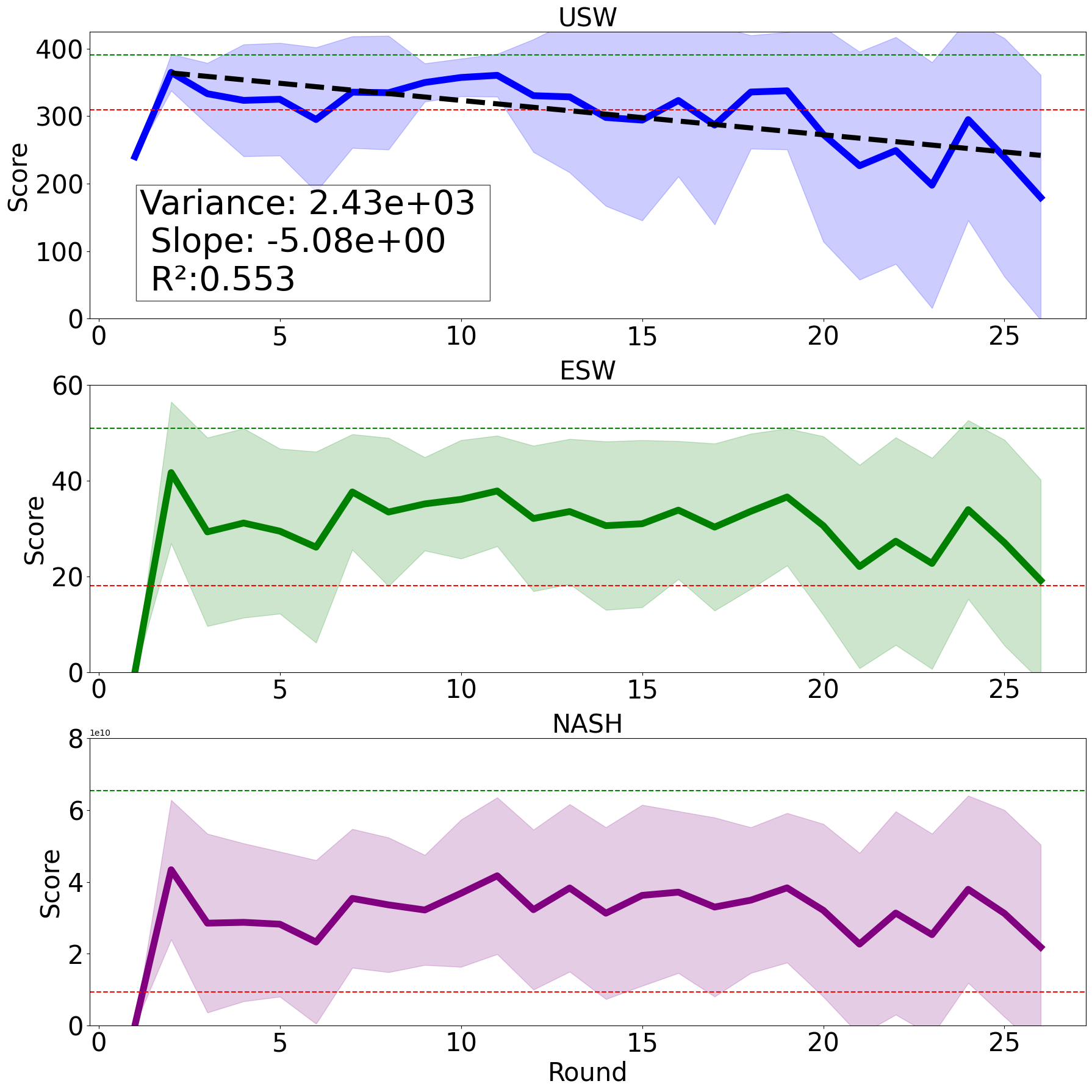
- 发现基准测试存在模型比较模糊、信息泄露检测不足等问题,强调上下文重要性。
📝 摘要(中文)
大型语言模型(LLMs)在多智能体谈判任务中展现出巨大潜力,但由于缺乏稳健和通用的基准,该领域的评估仍然具有挑战性。Abdelnabi等人(2024)提出了一个基于可评分博弈的谈判基准,旨在为LLMs开发一个高度复杂和真实的评估框架。本文研究了该基准中声明的可重复性,并更深入地理解其可用性和泛化性。我们复制了原始实验并在其他模型上进行了测试,并引入了额外的指标来验证谈判质量和评估的均匀性。我们的研究结果表明,虽然该基准确实很复杂,但模型比较是模糊的,这引发了对其客观性的质疑。此外,我们发现了实验设置中的局限性,特别是在信息泄露检测和消融研究的彻底性方面。通过检查和分析更广泛的模型在该基准的扩展版本上的行为,我们揭示了为潜在用户提供额外背景信息的见解。我们的结果强调了上下文在模型比较评估中的重要性。
🔬 方法详解
问题定义:论文旨在评估和改进用于评估大型语言模型(LLMs)在谈判任务中表现的基准测试。现有基准测试的痛点在于缺乏稳健性和通用性,导致模型之间的比较不够客观,并且可能存在信息泄露等问题。Abdelnabi等人的Scoreable Games基准旨在解决这些问题,但本文对其可重复性和客观性提出了质疑。
核心思路:论文的核心思路是通过复现和扩展现有的Scoreable Games基准测试,来更深入地分析LLMs在谈判任务中的表现。通过在更多模型上进行实验,并引入新的评估指标,来验证基准测试的有效性和公平性。同时,关注实验设置中的潜在问题,如信息泄露和消融研究的彻底性。
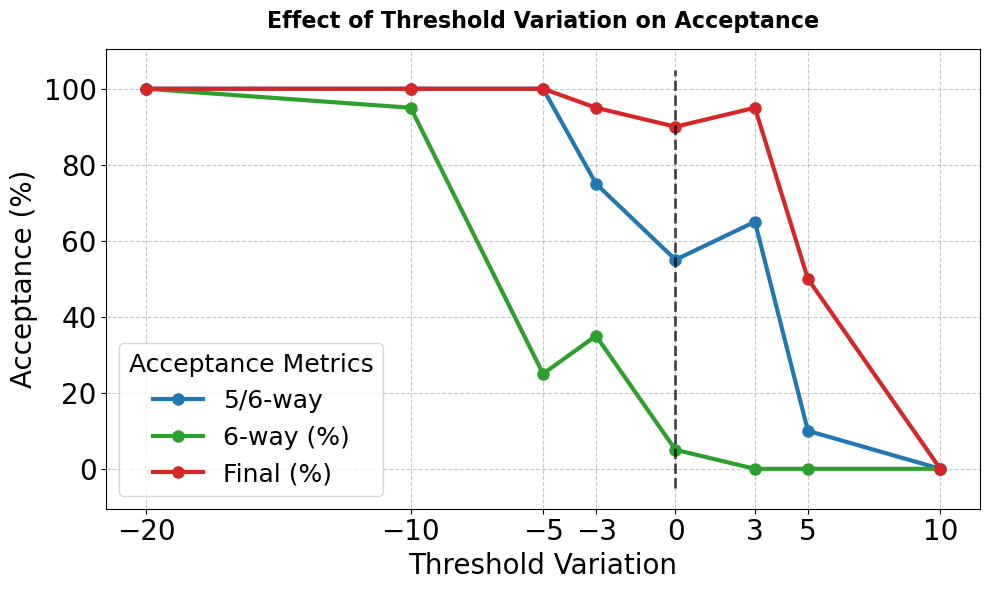
技术框架:论文主要采用实验研究的方法。首先,复现Abdelnabi等人的原始实验,并在其他LLMs上进行测试。然后,引入额外的评估指标,例如谈判质量和评估的均匀性,来更全面地评估模型的表现。此外,还对实验设置进行分析,以检测潜在的信息泄露问题。最后,通过消融研究来评估不同因素对模型性能的影响。
关键创新:论文的关键创新在于对现有LLM谈判基准测试的深入分析和改进。通过复现和扩展实验,揭示了基准测试中存在的潜在问题,例如模型比较的模糊性和信息泄露的可能性。同时,引入了新的评估指标,提高了评估的全面性和客观性。这些发现为未来LLM谈判基准测试的设计提供了重要的参考。
关键设计:论文的关键设计包括:1) 选择合适的LLMs进行实验,覆盖不同架构和规模的模型;2) 设计新的评估指标,例如谈判质量和评估的均匀性;3) 分析实验设置,检测潜在的信息泄露问题;4) 进行消融研究,评估不同因素对模型性能的影响。具体的参数设置和网络结构取决于所使用的LLMs,论文重点在于基准测试的评估和改进,而非特定模型的优化。
🖼️ 关键图片

📊 实验亮点
论文通过复现和扩展Scoreable Games基准测试,发现现有基准在模型比较上存在模糊性,并揭示了信息泄露的可能性。通过引入新的评估指标,例如谈判质量和评估的均匀性,更全面地评估了LLM的谈判能力。实验结果表明,上下文在模型比较评估中起着重要作用。
🎯 应用场景
该研究成果可应用于开发更可靠、更公平的LLM评估基准,推动多智能体谈判、自动化协商等领域的发展。通过更准确地评估LLM的谈判能力,可以更好地将其应用于商务谈判、客户服务、智能助理等场景,提升效率和用户体验。
📄 摘要(原文)
Large Language Models (LLMs) demonstrate significant potential in multi-agent negotiation tasks, yet evaluation in this domain remains challenging due to a lack of robust and generalizable benchmarks. Abdelnabi et al. (2024) introduce a negotiation benchmark based on Scoreable Games, with the aim of developing a highly complex and realistic evaluation framework for LLMs. Our work investigates the reproducibility of claims in their benchmark, and provides a deeper understanding of its usability and generalizability. We replicate the original experiments on additional models, and introduce additional metrics to verify negotiation quality and evenness of evaluation. Our findings reveal that while the benchmark is indeed complex, model comparison is ambiguous, raising questions about its objectivity. Furthermore, we identify limitations in the experimental setup, particularly in information leakage detection and thoroughness of the ablation study. By examining and analyzing the behavior of a wider range of models on an extended version of the benchmark, we reveal insights that provide additional context to potential users. Our results highlight the importance of context in model-comparative evaluations.