Continual-NExT: A Unified Comprehension And Generation Continual Learning Framework
作者: Jingyang Qiao, Zhizhong Zhang, Xin Tan, Jingyu Gong, Yanyun Qu, Yuan Xie
分类: cs.LG
发布日期: 2026-02-20
💡 一句话要点
提出Continual-NExT框架,解决多模态大语言模型持续学习难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 多模态大语言模型 知识迁移 灾难性遗忘 LoRA MAGE Continual-NExT
📋 核心要点
- 双重多模态大语言模型在持续学习中面临灾难性遗忘、幻觉和跨模态知识迁移失败等挑战。
- 提出MAGE方法,通过混合和聚合通用LoRA和专家LoRA,促进跨模态知识迁移并减轻遗忘。
- 实验结果表明,MAGE方法在持续学习任务中优于其他方法,达到state-of-the-art性能。
📝 摘要(中文)
本文提出了Continual-NExT,一个面向双重多模态大语言模型(Dual-to-Dual MLLMs)的持续学习框架,并设计了相应的评估指标。双重多模态大语言模型能够通过文本和图像模态实现统一的多模态理解和生成。尽管展现出强大的瞬时学习和泛化能力,但MLLMs在终身学习方面仍然存在不足,严重影响了其在动态真实世界场景中的持续适应性。除了传统的灾难性遗忘,MLLMs还面临幻觉、不遵循指令以及跨模态知识迁移失败等挑战。为了提升MLLMs的持续学习能力,本文提出了一种高效的MAGE(General LoRA和Expert LoRA的混合与聚合)方法,以促进跨模态知识迁移并减轻遗忘。大量实验表明,MAGE优于其他持续学习方法,并取得了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决双重多模态大语言模型(Dual-to-Dual MLLMs)在持续学习过程中遇到的问题。现有方法在适应新任务时,容易遗忘先前学习的知识(灾难性遗忘),并且可能出现幻觉、不遵循指令以及跨模态知识迁移失败等问题。这些问题限制了MLLMs在动态真实世界场景中的应用。
核心思路:论文的核心思路是通过一种高效的参数调整方法,在学习新任务的同时,保留并迁移先前学习的知识。具体而言,论文提出了MAGE(Mixture and Aggregation of General LoRA and Expert LoRA)方法,该方法结合了通用LoRA和专家LoRA的优点,以实现更好的知识迁移和遗忘缓解。通用LoRA负责捕获通用知识,而专家LoRA则专注于特定任务的知识。
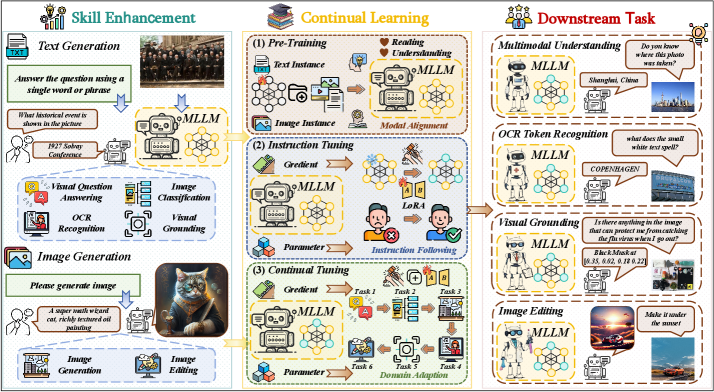
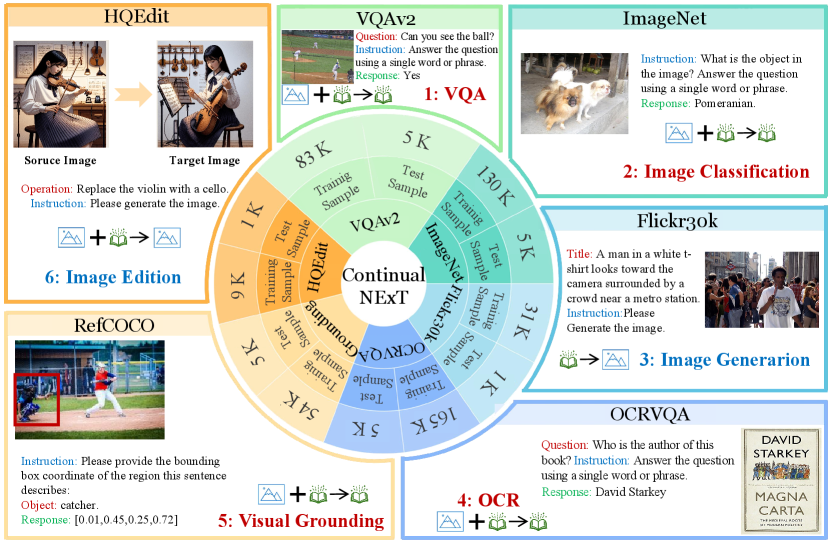
技术框架:Continual-NExT框架包含以下几个主要组成部分:首先,使用一系列持续学习任务对MLLM进行训练。其次,在训练过程中,使用MAGE方法对模型参数进行调整。最后,使用专门设计的评估指标来评估模型在持续学习任务上的性能。MAGE方法是该框架的核心,它通过混合和聚合通用LoRA和专家LoRA来更新模型参数。
关键创新:MAGE方法是论文的关键创新点。与传统的持续学习方法相比,MAGE方法能够更有效地促进跨模态知识迁移,并减轻灾难性遗忘。其本质区别在于,MAGE方法同时利用了通用知识和特定任务知识,从而在学习新任务的同时,更好地保留了先前学习的知识。此外,Continual-NExT框架本身也是一个创新,它为双重多模态大语言模型的持续学习提供了一个标准化的评估平台。
关键设计:MAGE方法的关键设计包括:1) 使用LoRA(Low-Rank Adaptation)来减少需要训练的参数量,从而提高训练效率。2) 使用通用LoRA来捕获通用知识,并使用专家LoRA来捕获特定任务的知识。3) 使用混合和聚合机制来结合通用LoRA和专家LoRA的输出,从而实现更好的知识迁移和遗忘缓解。具体的混合和聚合权重可以通过学习得到,也可以手动设置。损失函数的设计需要考虑新任务的性能以及对先前任务的遗忘程度。
🖼️ 关键图片
📊 实验亮点
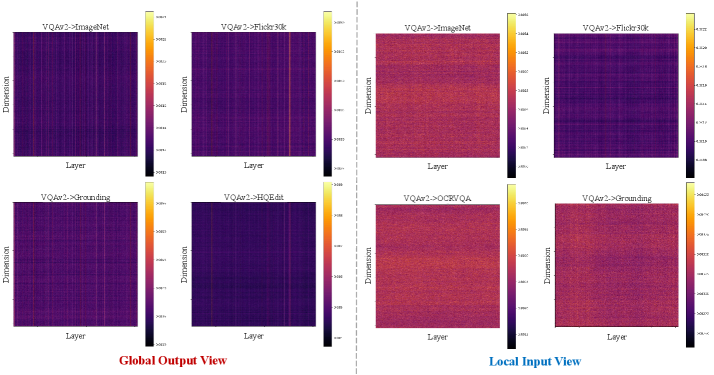
实验结果表明,MAGE方法在Continual-NExT框架下,显著优于其他持续学习方法,并在多个持续学习任务上取得了state-of-the-art的性能。具体的性能提升数据在论文中给出,表明MAGE方法能够有效地缓解灾难性遗忘,并促进跨模态知识迁移。
🎯 应用场景
该研究成果可应用于需要持续学习和适应新知识的多模态人工智能系统,例如智能助手、自动驾驶、医疗诊断等领域。通过提升模型在动态环境中的适应能力,可以提高系统的可靠性和实用性,并降低维护成本。未来,该研究可以进一步扩展到更多模态和更复杂的任务。
📄 摘要(原文)
Dual-to-Dual MLLMs refer to Multimodal Large Language Models, which can enable unified multimodal comprehension and generation through text and image modalities. Although exhibiting strong instantaneous learning and generalization capabilities, Dual-to-Dual MLLMs still remain deficient in lifelong evolution, significantly affecting continual adaptation to dynamic real-world scenarios. One of the challenges is that learning new tasks inevitably destroys the learned knowledge. Beyond traditional catastrophic forgetting, Dual-to-Dual MLLMs face other challenges, including hallucination, instruction unfollowing, and failures in cross-modal knowledge transfer. However, no standardized continual learning framework for Dual-to-Dual MLLMs has been established yet, leaving these challenges unexplored. Thus, in this paper, we establish Continual-NExT, a continual learning framework for Dual-to-Dual MLLMs with deliberately-architected evaluation metrics. To improve the continual learning capability of Dual-to-Dual MLLMs, we propose an efficient MAGE (Mixture and Aggregation of General LoRA and Expert LoRA) method to further facilitate knowledge transfer across modalities and mitigate forgetting. Extensive experiments demonstrate that MAGE outperforms other continual learning methods and achieves state-of-the-art performance.