Flow Actor-Critic for Offline Reinforcement Learning
作者: Jongseong Chae, Jongeui Park, Yongjae Shin, Gyeongmin Kim, Seungyul Han, Youngchul Sung
分类: cs.LG, cs.AI
发布日期: 2026-02-20
备注: Accepted to ICLR 2026
💡 一句话要点
提出Flow Actor-Critic,利用流模型解决离线强化学习中复杂数据分布问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 流模型 Actor-Critic Q值估计 策略优化 数据分布 正则化
📋 核心要点
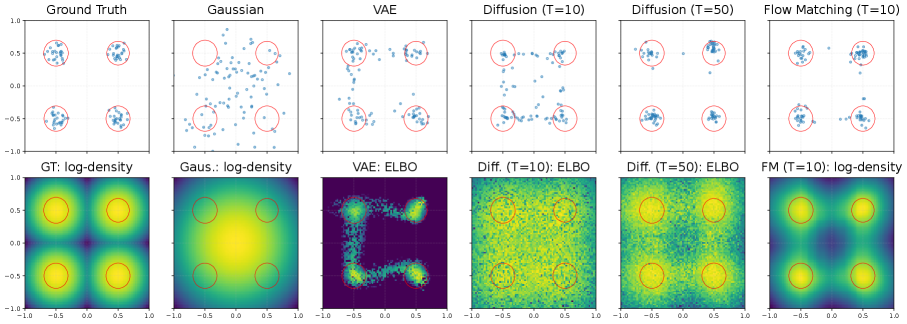
- 离线强化学习数据集通常具有复杂和多模态分布,传统高斯策略难以有效建模。
- Flow Actor-Critic利用流模型同时增强Actor和Critic,提高策略表达能力并防止Q值过估计。
- 实验表明,Flow Actor-Critic在D4RL和OGBench等基准测试中取得了领先的性能。
📝 摘要(中文)
本文提出了一种新的离线强化学习Actor-Critic方法,名为Flow Actor-Critic,该方法基于最新的流策略。针对离线强化学习中数据集分布通常表现出复杂和多模态分布的特性,现有方法难以有效捕捉这些分布(通常使用高斯策略)。Flow Actor-Critic不仅像之前的流策略一样使用流模型作为Actor,还利用富有表达能力的流模型进行保守的Critic学习,以防止在数据外区域出现Q值爆炸。为此,我们提出了一种新的Critic正则化器,该正则化器基于流行为代理模型,该模型是基于流的Actor设计的副产品。通过以这种联合方式利用流模型,我们在包括D4RL和最新的OGBench基准测试在内的离线强化学习测试数据集上实现了新的state-of-the-art性能。
🔬 方法详解
问题定义:离线强化学习面临的一个关键挑战是数据集的复杂性和多模态分布。传统方法通常采用高斯策略,表达能力有限,难以充分捕捉这些复杂的数据分布。此外,在数据外(out-of-distribution)区域,Q值估计容易出现偏差和爆炸,导致策略学习不稳定。
核心思路:Flow Actor-Critic的核心思路是利用流模型(Flow-based Model)强大的表达能力,同时提升Actor和Critic的性能。通过使用流模型作为Actor,可以更好地拟合复杂的数据分布。同时,利用流模型构建保守的Critic,可以有效抑制Q值在数据外区域的过高估计,从而提高学习的稳定性和泛化能力。
技术框架:Flow Actor-Critic包含Actor网络和Critic网络两个主要模块。Actor网络采用流模型,将潜在空间映射到动作空间,从而生成策略。Critic网络也采用流模型,用于估计Q值,并引入一个基于流行为代理模型的正则化项,以约束Q值的范围。训练过程包括Actor的策略优化和Critic的Q值估计,两者相互作用,共同提升性能。
关键创新:Flow Actor-Critic的关键创新在于同时利用流模型增强Actor和Critic。传统的流策略方法通常只关注Actor的表达能力,而忽略了Critic的重要性。Flow Actor-Critic通过引入基于流模型的Critic正则化器,有效抑制了Q值在数据外区域的过估计,从而提高了学习的稳定性和泛化能力。
关键设计:Critic的正则化项是基于流行为代理模型构建的,该模型是Actor网络训练的副产品。正则化项的目标是约束Critic的输出,使其与流行为代理模型的预测结果保持一致,从而防止Q值爆炸。具体的损失函数包括Q值估计的均方误差损失和正则化损失,两者通过一个超参数进行平衡。网络结构方面,Actor和Critic都可以采用不同的流模型架构,例如RealNVP、Glow等。
🖼️ 关键图片


📊 实验亮点
Flow Actor-Critic在D4RL和OGBench等多个离线强化学习基准测试中取得了显著的性能提升。例如,在D4RL的复杂任务中,Flow Actor-Critic的性能超过了现有最佳方法,实现了state-of-the-art的结果。在OGBench的测试中,Flow Actor-Critic也展现出了强大的泛化能力,证明了其在处理复杂数据分布方面的优势。
🎯 应用场景
Flow Actor-Critic可应用于各种离线强化学习场景,例如机器人控制、自动驾驶、推荐系统和金融交易等。在这些场景中,通常存在大量离线数据,但与环境交互的成本很高。Flow Actor-Critic能够有效利用这些离线数据进行策略学习,从而降低对在线交互的需求,加速策略的部署和应用。该方法还有潜力应用于需要处理复杂和多模态数据分布的任务。
📄 摘要(原文)
The dataset distributions in offline reinforcement learning (RL) often exhibit complex and multi-modal distributions, necessitating expressive policies to capture such distributions beyond widely-used Gaussian policies. To handle such complex and multi-modal datasets, in this paper, we propose Flow Actor-Critic, a new actor-critic method for offline RL, based on recent flow policies. The proposed method not only uses the flow model for actor as in previous flow policies but also exploits the expressive flow model for conservative critic acquisition to prevent Q-value explosion in out-of-data regions. To this end, we propose a new form of critic regularizer based on the flow behavior proxy model obtained as a byproduct of flow-based actor design. Leveraging the flow model in this joint way, we achieve new state-of-the-art performance for test datasets of offline RL including the D4RL and recent OGBench benchmarks.