Memory-Based Advantage Shaping for LLM-Guided Reinforcement Learning
作者: Narjes Nourzad, Carlee Joe-Wong
分类: cs.LG, cs.AI
发布日期: 2026-02-20
备注: Association for the Advancement of Artificial Intelligence (AAAI)
💡 一句话要点
提出基于记忆的优势塑造方法,提升LLM引导强化学习的样本效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 优势塑造 记忆图 样本效率
📋 核心要点
- 传统强化学习在稀疏奖励环境中面临样本效率低的挑战,需要大量交互才能学习。
- 论文提出构建记忆图,利用LLM引导和智能体自身经验,从中提取效用函数来塑造优势函数。
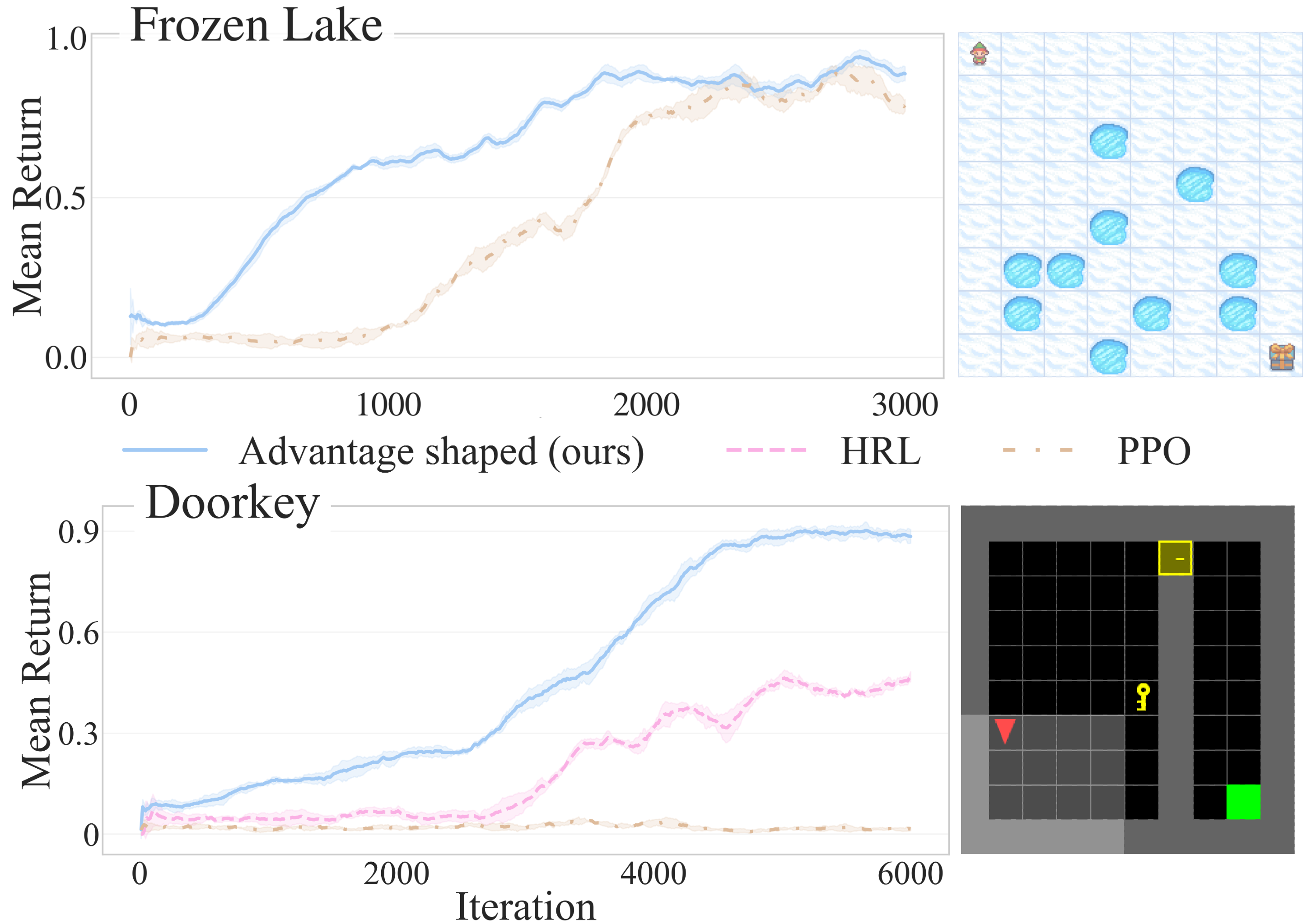
- 实验结果表明,该方法在基准环境中提高了样本效率和早期学习速度,最终性能与频繁使用LLM的方法相当。
📝 摘要(中文)
在奖励稀疏或延迟的环境中,强化学习(RL)由于学习所需的大量交互而导致样本复杂度高。为了解决这个问题,研究者开始利用大型语言模型(LLM)进行子目标发现和轨迹引导。虽然LLM可以支持探索,但频繁依赖LLM调用会引发关于可扩展性和可靠性的担忧。本文通过构建一个记忆图来解决这些挑战,该记忆图编码了来自LLM引导和智能体自身成功轨迹的子目标和轨迹。从这个图中,我们推导出一个效用函数,用于评估智能体的轨迹与先前成功策略的对齐程度。该效用函数塑造优势函数,为评论家提供额外的指导,而不改变奖励。我们的方法主要依赖于离线输入和偶尔的在线查询,避免了对连续LLM监督的依赖。在基准环境中的初步实验表明,与基线RL方法相比,样本效率得到提高,早期学习速度更快,并且最终回报与需要频繁LLM交互的方法相当。
🔬 方法详解
问题定义:强化学习在稀疏奖励或延迟奖励环境中,由于探索空间巨大,智能体难以找到有效策略,导致样本效率低下。现有方法依赖频繁的LLM调用来指导探索,但存在可扩展性和可靠性问题,同时增加了计算成本。
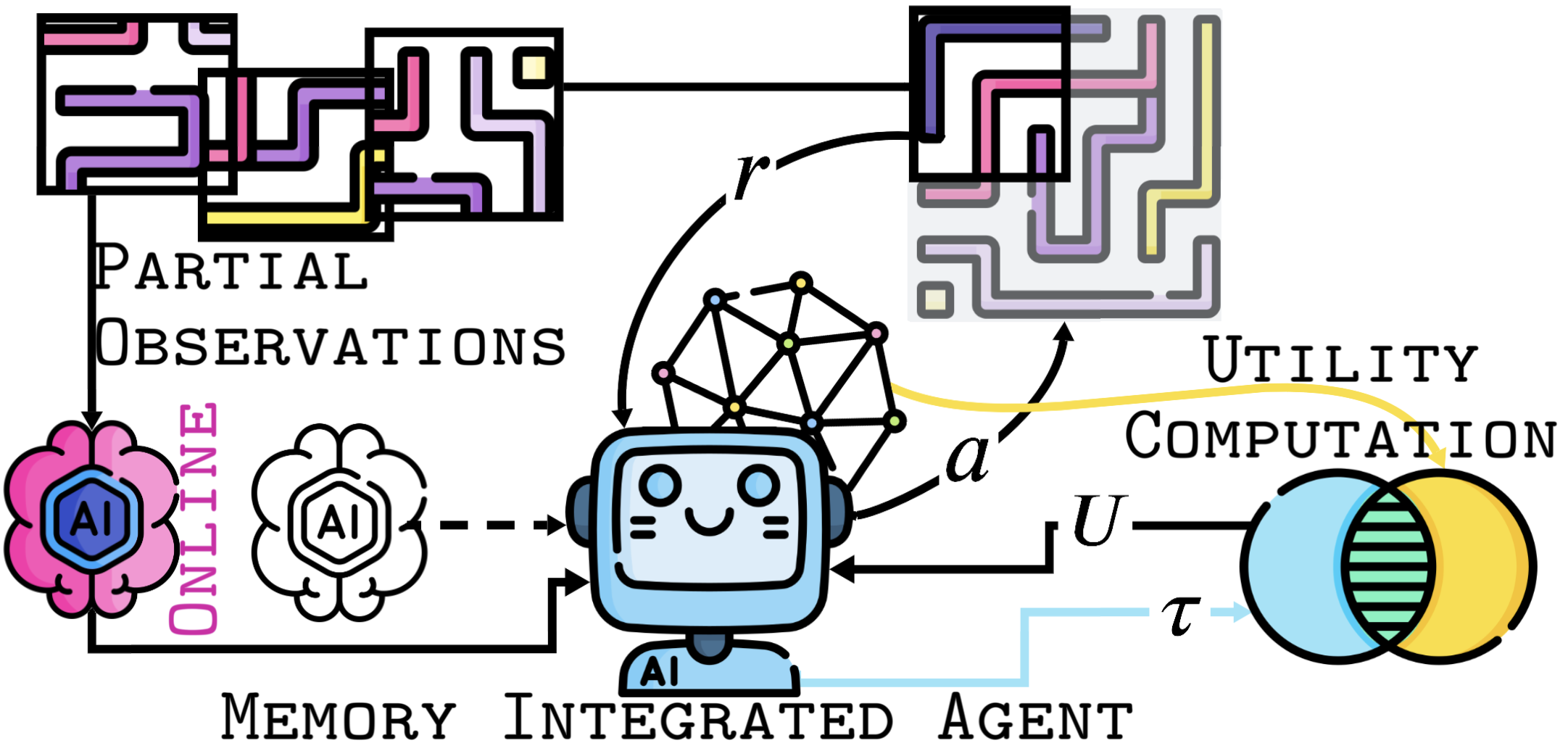
核心思路:核心思想是构建一个记忆图,该图存储了来自LLM引导和智能体自身成功经验的子目标和轨迹。利用这个记忆图,可以评估当前轨迹与历史成功轨迹的相似度,并以此塑造优势函数,从而引导智能体学习,同时减少对在线LLM调用的依赖。
技术框架:该方法包含以下几个主要阶段:1) 离线阶段:利用LLM生成初始的子目标和轨迹,并存储到记忆图中。2) 在线学习阶段:智能体与环境交互,并将成功轨迹添加到记忆图中。3) 优势塑造阶段:利用记忆图中的信息,计算一个效用函数,该函数评估当前轨迹与记忆图中成功轨迹的相似度。4) 策略优化阶段:利用塑造后的优势函数,更新智能体的策略。
关键创新:关键创新在于利用记忆图来存储和利用历史经验,从而在不依赖频繁在线LLM调用的情况下,有效地指导智能体的探索。与直接使用LLM生成动作或奖励的方法不同,该方法通过塑造优势函数来间接影响策略学习,避免了对LLM的过度依赖。
关键设计:记忆图的构建方式,效用函数的具体形式,以及优势函数塑造的策略是关键设计。例如,效用函数可以基于轨迹之间的距离或相似度来定义。优势函数的塑造可以通过加权的方式将效用函数与原始优势函数结合起来。具体的参数设置需要根据不同的环境进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在基准环境中实现了更高的样本效率和更快的早期学习速度。与基线RL方法相比,该方法能够更快地找到有效的策略。此外,该方法最终的回报与需要频繁LLM交互的方法相当,但显著降低了对在线LLM调用的依赖,提高了可扩展性和可靠性。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、自动驾驶等需要智能体在复杂环境中进行探索和学习的领域。通过利用LLM的知识和智能体自身的经验,可以显著提高学习效率,降低对人工干预的依赖,并最终实现更智能、更自主的智能体。
📄 摘要(原文)
In environments with sparse or delayed rewards, reinforcement learning (RL) incurs high sample complexity due to the large number of interactions needed for learning. This limitation has motivated the use of large language models (LLMs) for subgoal discovery and trajectory guidance. While LLMs can support exploration, frequent reliance on LLM calls raises concerns about scalability and reliability. We address these challenges by constructing a memory graph that encodes subgoals and trajectories from both LLM guidance and the agent's own successful rollouts. From this graph, we derive a utility function that evaluates how closely the agent's trajectories align with prior successful strategies. This utility shapes the advantage function, providing the critic with additional guidance without altering the reward. Our method relies primarily on offline input and only occasional online queries, avoiding dependence on continuous LLM supervision. Preliminary experiments in benchmark environments show improved sample efficiency and faster early learning compared to baseline RL methods, with final returns comparable to methods that require frequent LLM interaction.