MIRA: Memory-Integrated Reinforcement Learning Agent with Limited LLM Guidance
作者: Narjes Nourzad, Carlee Joe-Wong
分类: cs.LG, cs.AI
发布日期: 2026-02-20
备注: International Conference on Learning Representations (ICLR'26)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MIRA:一种利用有限LLM指导的记忆集成强化学习Agent,解决稀疏奖励问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 记忆集成 稀疏奖励 效用函数 智能体 策略学习
📋 核心要点
- 传统强化学习在稀疏奖励环境中样本效率低,难以有效探索。
- MIRA通过构建记忆图存储经验和LLM知识,利用效用信号引导策略学习。
- 实验表明,MIRA在稀疏奖励环境中表现优于传统RL,且减少了对LLM的依赖。
📝 摘要(中文)
强化学习(RL)Agent在稀疏或延迟奖励环境中,由于缺乏先验结构,通常面临高样本复杂度的问题。大型语言模型(LLM)可以提供子目标分解、合理的轨迹以及抽象先验,从而促进早期学习。然而,过度依赖LLM监督会带来可扩展性约束,并依赖于潜在的不可靠信号。我们提出了MIRA(Memory-Integrated Reinforcement Learning Agent),它结合了一个结构化的、不断演化的记忆图来指导早期训练。该图存储决策相关的信息,包括轨迹片段和子目标结构,并由Agent的高回报经验和LLM输出构建。这种设计将LLM查询分摊到持久内存中,而不是需要持续的实时监督。从这个记忆图中,我们导出一个效用信号,该信号柔和地调整优势估计,以影响策略更新,而不修改底层奖励函数。随着训练的进行,Agent的策略逐渐超越最初的LLM派生的先验,并且效用项衰减,从而保留了标准收敛保证。我们提供了理论分析,表明基于效用的塑造改进了稀疏奖励环境中的早期学习。在实验上,MIRA优于RL基线,并实现了与依赖频繁LLM监督的方法相当的回报,同时需要显著更少的在线LLM查询。
🔬 方法详解
问题定义:在稀疏或延迟奖励的强化学习环境中,Agent难以探索到有价值的经验,导致学习效率低下。现有方法要么依赖大量样本进行试错,要么过度依赖LLM的实时指导,前者效率低,后者成本高且可能引入噪声。
核心思路:MIRA的核心思路是将LLM提供的先验知识和Agent自身的经验整合到一个结构化的记忆图中,并从中提取效用信号来引导Agent的探索和学习。通过这种方式,MIRA可以在早期学习阶段利用LLM的指导,同时避免过度依赖LLM,并随着Agent自身经验的积累,逐渐超越LLM的先验知识。
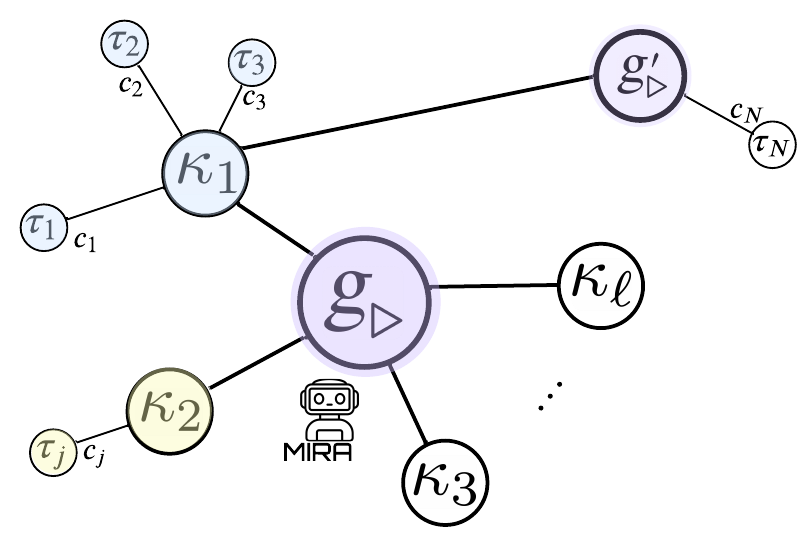
技术框架:MIRA的整体框架包括以下几个主要模块:1) 记忆图构建:利用Agent的经验(轨迹片段、奖励等)和LLM的输出(子目标结构等)构建一个记忆图,节点表示状态或子目标,边表示状态转移或子目标之间的关系。2) 效用信号提取:从记忆图中提取效用信号,该信号反映了状态或子目标的重要性,用于调整优势估计。3) 策略更新:利用强化学习算法(如PPO)更新Agent的策略,同时利用效用信号调整优势估计,引导Agent探索更有价值的状态和行为。4) 记忆图更新:随着Agent经验的积累,不断更新记忆图,包括添加新的节点和边,以及更新节点和边的权重。
关键创新:MIRA的关键创新在于将LLM的知识和Agent自身的经验整合到一个结构化的记忆图中,并利用效用信号来引导策略学习。这种方法既可以利用LLM的先验知识,又可以避免过度依赖LLM,并随着Agent自身经验的积累,逐渐超越LLM的先验知识。与现有方法相比,MIRA在样本效率、成本和鲁棒性方面具有优势。
关键设计:MIRA的关键设计包括:1) 记忆图的结构:记忆图的节点表示状态或子目标,边表示状态转移或子目标之间的关系。节点和边的权重可以根据Agent的经验和LLM的输出进行调整。2) 效用信号的计算:效用信号可以根据记忆图中节点和边的权重进行计算,反映了状态或子目标的重要性。3) 优势估计的调整:利用效用信号调整优势估计,引导Agent探索更有价值的状态和行为。效用信号的影响随着训练的进行逐渐衰减,以保证收敛性。4) LLM查询策略:MIRA采用一种自适应的LLM查询策略,根据Agent的学习进度和环境的复杂性,动态调整LLM查询的频率和内容。
🖼️ 关键图片

📊 实验亮点
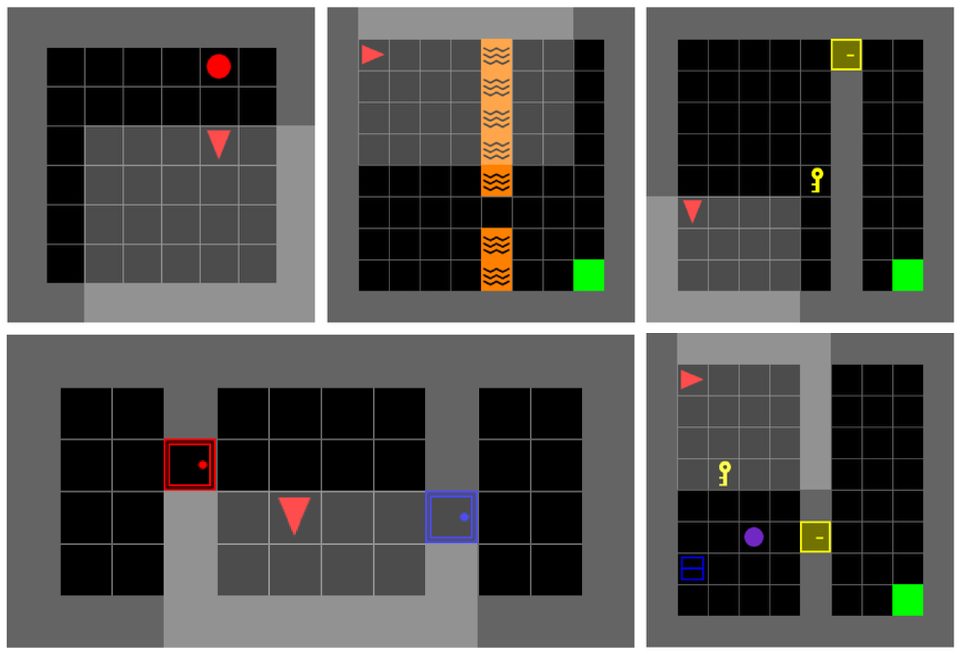
MIRA在多个稀疏奖励环境中进行了实验,结果表明,MIRA优于传统的RL基线,并且能够达到与频繁使用LLM监督的方法相当的性能,同时显著减少了在线LLM查询的数量。具体而言,MIRA在某些任务中可以将LLM查询数量减少50%以上,同时保持甚至提高性能。
🎯 应用场景
MIRA具有广泛的应用前景,尤其适用于奖励稀疏或延迟的强化学习任务,例如机器人导航、游戏AI、自动驾驶等。通过整合LLM的知识和Agent自身的经验,MIRA可以显著提高学习效率,降低训练成本,并提高Agent的鲁棒性。未来,MIRA可以进一步扩展到更复杂的环境和任务中,例如多智能体协作、人机协作等。
📄 摘要(原文)
Reinforcement learning (RL) agents often suffer from high sample complexity in sparse or delayed reward settings due to limited prior structure. Large language models (LLMs) can provide subgoal decompositions, plausible trajectories, and abstract priors that facilitate early learning. However, heavy reliance on LLM supervision introduces scalability constraints and dependence on potentially unreliable signals. We propose MIRA (Memory-Integrated Reinforcement Learning Agent), which incorporates a structured, evolving memory graph to guide early training. The graph stores decision-relevant information, including trajectory segments and subgoal structures, and is constructed from both the agent's high-return experiences and LLM outputs. This design amortizes LLM queries into a persistent memory rather than requiring continuous real-time supervision. From this memory graph, we derive a utility signal that softly adjusts advantage estimation to influence policy updates without modifying the underlying reward function. As training progresses, the agent's policy gradually surpasses the initial LLM-derived priors, and the utility term decays, preserving standard convergence guarantees. We provide theoretical analysis showing that utility-based shaping improves early-stage learning in sparse-reward environments. Empirically, MIRA outperforms RL baselines and achieves returns comparable to approaches that rely on frequent LLM supervision, while requiring substantially fewer online LLM queries. Project webpage: https://narjesno.github.io/MIRA/