Reverso: Efficient Time Series Foundation Models for Zero-shot Forecasting
作者: Xinghong Fu, Yanhong Li, Georgios Papaioannou, Yoon Kim
分类: cs.LG, cs.AI
发布日期: 2026-02-19
💡 一句话要点
提出Reverso,一种高效时间序列基础模型,用于零样本预测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 基础模型 零样本学习 高效模型 混合模型 长卷积 线性RNN
📋 核心要点
- 现有时间序列基础模型参数量巨大,导致使用效率低且成本高昂,难以实际应用。
- 论文提出一种小型混合模型Reverso,交错长卷积和线性RNN层,在保证性能的同时显著降低模型规模。
- 通过数据增强和推理策略进一步提升Reverso性能,在性能和效率之间取得更好的平衡。
📝 摘要(中文)
学习时间序列基础模型已被证明是跨多个时间序列领域进行零样本时间序列预测的一种有前景的方法。由于扩展是语言和视觉等其他模态中基础模型性能的关键驱动因素,最近关于时间序列基础建模的许多工作都集中在扩展上。这导致了具有数亿参数的时间序列基础模型,虽然性能良好,但在实践中使用效率低下且成本高昂。本文描述了一种简单的配方,用于学习高效的基础模型,用于零样本时间序列预测,其规模要小几个数量级。我们表明,大型Transformer不是必需的:小型混合模型,其交错长卷积和线性RNN层(特别是DeltaNet层)可以匹配基于大型Transformer的模型的性能,同时小一百多倍。我们还描述了几种数据增强和推理策略,可进一步提高性能。这种配方产生了Reverso,这是一系列用于零样本预测的高效时间序列基础模型,可显着推动性能-效率帕累托前沿。
🔬 方法详解
问题定义:论文旨在解决现有时间序列基础模型参数量过大,导致计算成本高昂和部署困难的问题。现有方法过度依赖大型Transformer结构,忽略了模型效率,限制了其在实际场景中的应用。
核心思路:论文的核心思路是利用小型混合模型,结合长卷积和线性RNN的优势,在保证预测性能的同时,显著降低模型参数量。通过精心设计的网络结构和训练策略,实现性能与效率的平衡。
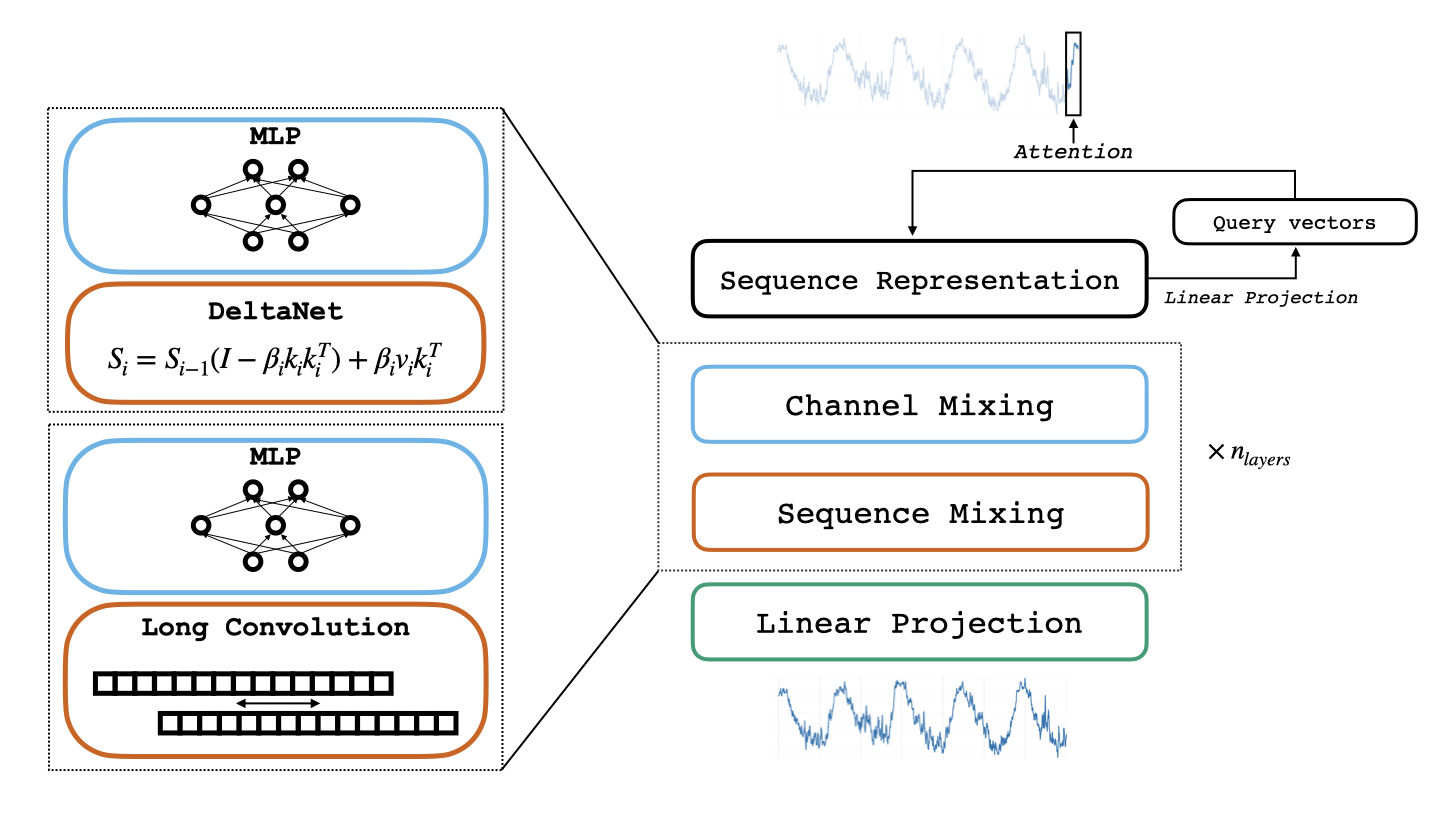
技术框架:Reverso模型采用混合架构,主要包含以下模块:1) 长卷积层:用于捕捉时间序列的局部依赖关系;2) DeltaNet层:一种线性RNN层,用于捕捉时间序列的长期依赖关系;3) 数据增强模块:用于扩充训练数据,提高模型的泛化能力;4) 推理模块:采用特定的推理策略,进一步提升预测精度。整体流程为:输入时间序列数据,经过长卷积层和DeltaNet层提取特征,然后进行预测。
关键创新:论文的关键创新在于提出了一种高效的混合模型架构,该架构能够在参数量远小于Transformer模型的情况下,达到甚至超过其预测性能。DeltaNet层的引入是另一个创新点,它能够有效地捕捉时间序列的长期依赖关系,而无需像Transformer那样进行全局注意力计算。
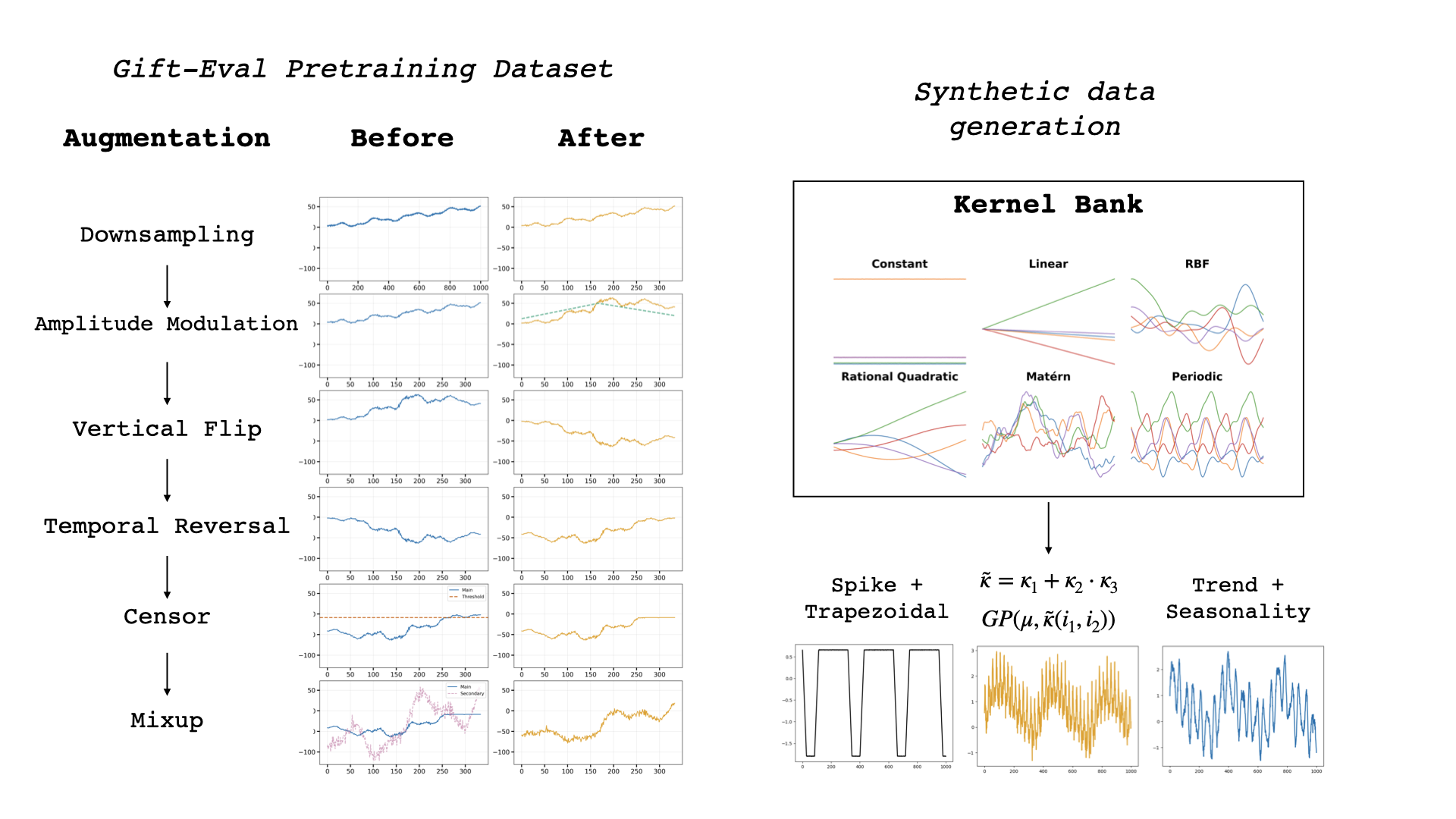
关键设计:Reverso的关键设计包括:1) 长卷积层的卷积核大小和步长;2) DeltaNet层的隐藏单元数量和激活函数;3) 数据增强策略,例如时间扭曲、幅度缩放等;4) 推理策略,例如模型集成、滑动窗口预测等。损失函数采用常用的均方误差或平均绝对误差。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Reverso在多个时间序列数据集上取得了与大型Transformer模型相当甚至更好的性能,同时模型参数量减少了两个数量级以上。例如,在M4数据集上,Reverso的预测精度与Transformer模型相当,但参数量仅为其1/100。此外,数据增强和推理策略也显著提升了Reverso的性能。
🎯 应用场景
Reverso可广泛应用于各种时间序列预测场景,如金融市场预测、能源消耗预测、供应链管理、医疗健康监测等。其高效的特性使其更易于部署在资源受限的设备上,例如嵌入式系统和移动设备。未来,Reverso有望成为时间序列分析领域的重要工具,推动相关技术的发展。
📄 摘要(原文)
Learning time series foundation models has been shown to be a promising approach for zero-shot time series forecasting across diverse time series domains. Insofar as scaling has been a critical driver of performance of foundation models in other modalities such as language and vision, much recent work on time series foundation modeling has focused on scaling. This has resulted in time series foundation models with hundreds of millions of parameters that are, while performant, inefficient and expensive to use in practice. This paper describes a simple recipe for learning efficient foundation models for zero-shot time series forecasting that are orders of magnitude smaller. We show that large-scale transformers are not necessary: small hybrid models that interleave long convolution and linear RNN layers (in particular DeltaNet layers) can match the performance of larger transformer-based models while being more than a hundred times smaller. We also describe several data augmentation and inference strategies that further improve performance. This recipe results in Reverso, a family of efficient time series foundation models for zero-shot forecasting that significantly push the performance-efficiency Pareto frontier.