SMAC: Score-Matched Actor-Critics for Robust Offline-to-Online Transfer
作者: Nathan S. de Lara, Florian Shkurti
分类: cs.LG, cs.AI
发布日期: 2026-02-19
💡 一句话要点
SMAC:通过分数匹配的Actor-Critic方法实现鲁棒的离线到在线迁移
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 在线微调 Actor-Critic 分数匹配 策略迁移
📋 核心要点
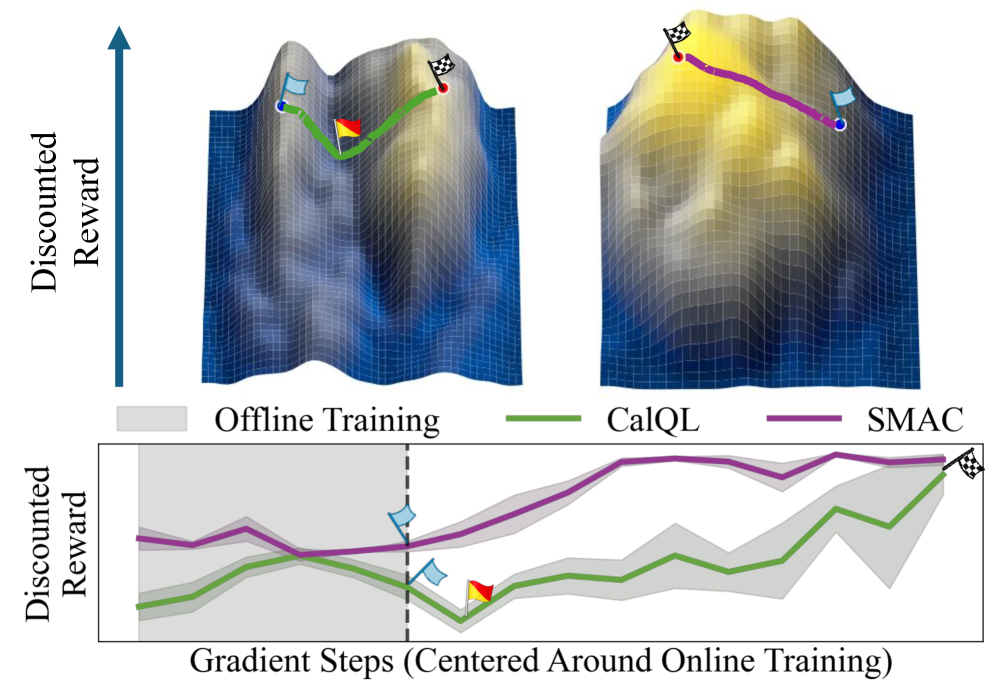
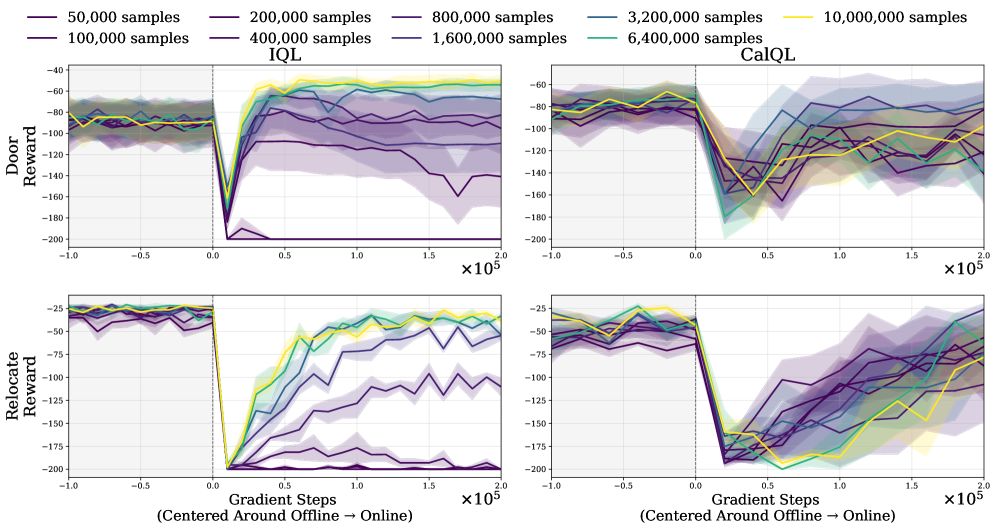
- 现有离线RL算法微调时性能骤降,原因是离线和在线最优策略间存在低性能区域。
- SMAC通过正则化Q函数,使其满足策略分数与Q函数动作梯度之间的一阶导数相等,从而避免性能下降。
- 实验表明SMAC在D4RL任务中实现了平滑迁移,并显著降低了遗憾值,性能优于基线方法。
📝 摘要(中文)
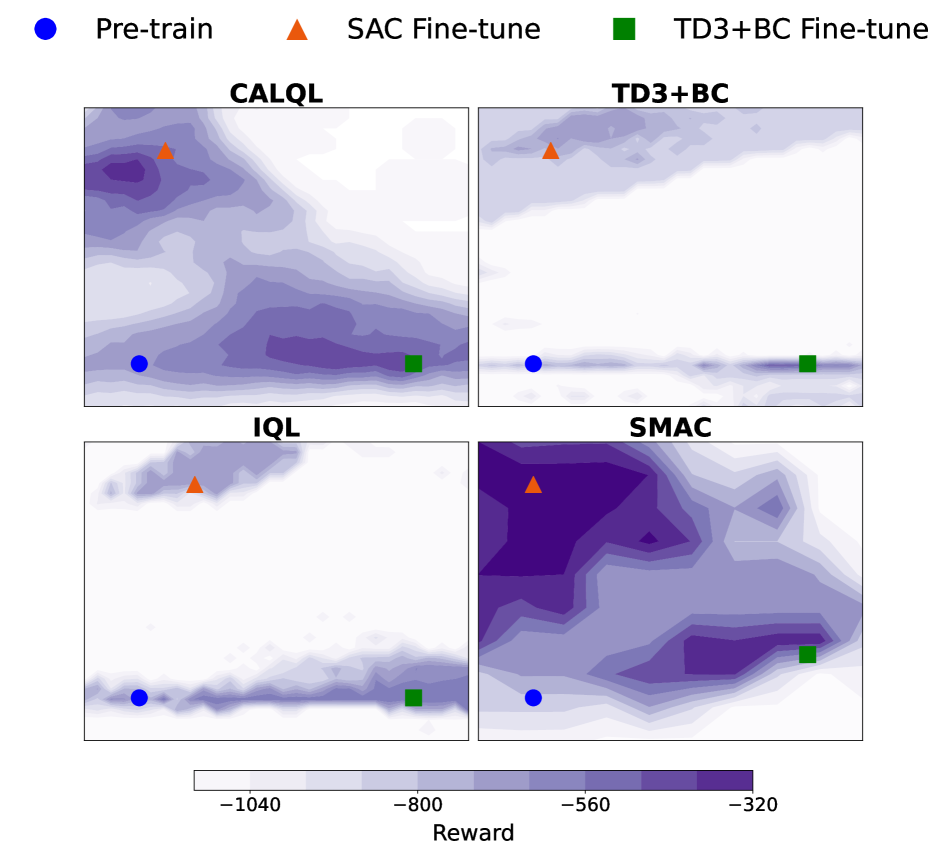
现代离线强化学习(RL)方法能够找到高性能的actor-critic模型,然而,使用基于价值的RL算法在线微调这些actor-critic模型通常会导致性能立即下降。我们提供的证据与以下假设一致:在损失 landscape 中,先前算法的离线最大值和在线最大值被低性能的“山谷”分隔开,而基于梯度的微调会穿过这些山谷。基于此,我们提出了一种名为分数匹配Actor-Critic (SMAC)的离线RL方法,旨在学习能够无缝过渡到在线价值RL算法的actor-critic模型,且性能不会下降。SMAC通过在离线阶段正则化Q函数,使其满足策略分数与Q函数动作梯度之间的一阶导数相等,从而避免了离线和在线最大值之间的山谷。实验结果表明,SMAC收敛到离线最大值,这些最大值通过一阶优化找到的单调递增奖励路径连接到更好的在线最大值。在6/6个D4RL任务中,SMAC实现了到Soft Actor-Critic和TD3的平滑迁移。在4/6个环境中,它比最佳基线减少了34-58%的遗憾。
🔬 方法详解
问题定义:现有离线强化学习算法训练得到的actor-critic模型,在直接进行在线微调时,往往会遇到性能急剧下降的问题。这是因为离线训练的最优解和在线训练的最优解在损失函数空间中被低性能的区域(“山谷”)分隔开,传统的基于梯度的优化方法容易陷入这些“山谷”,导致性能下降。因此,如何实现离线到在线的平滑迁移是一个关键问题。
核心思路:SMAC的核心思路是通过正则化Q函数,使得离线训练得到的Q函数能够更好地适应在线环境。具体来说,SMAC强制Q函数的动作梯度与策略的score function相匹配。这意味着SMAC试图学习一个Q函数,其梯度指向更有希望改进策略的方向,从而避免陷入离线和在线最优解之间的低性能区域。
技术框架:SMAC算法主要包含离线训练和在线微调两个阶段。在离线训练阶段,SMAC使用离线数据集训练actor和critic网络,同时引入一个正则化项,该正则化项惩罚Q函数的动作梯度与策略的score function之间的差异。在线微调阶段,可以使用任何基于价值的RL算法(如SAC或TD3)对actor-critic网络进行微调。整体流程是先通过离线数据学习一个较好的初始化策略和Q函数,然后通过在线交互进一步优化。
关键创新:SMAC最关键的创新在于引入了score matching的思想,通过正则化Q函数的动作梯度,使其与策略的score function对齐。这种方法有效地避免了离线和在线训练之间的“山谷”,从而实现了平滑的迁移。与传统的离线RL方法相比,SMAC更加关注离线策略和在线策略之间的一致性,从而提高了在线微调的效率和稳定性。
关键设计:SMAC的关键设计在于正则化项的构建。正则化项的目标是最小化Q函数的动作梯度与策略的score function之间的差异。具体来说,可以使用均方误差(MSE)作为正则化损失函数,即:L_reg = E[(∇_a Q(s, a) - ∇_a log π(a|s))^2]。此外,还需要仔细调整正则化系数,以平衡离线性能和在线迁移性能。网络结构方面,可以使用常见的actor-critic网络结构,如多层感知机(MLP)或卷积神经网络(CNN)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SMAC在D4RL benchmark的多个任务中实现了显著的性能提升。例如,在部分环境中,SMAC比最佳基线减少了34-58%的遗憾值。此外,SMAC还实现了到Soft Actor-Critic和TD3的平滑迁移,表明其具有良好的泛化能力和适应性。
🎯 应用场景
SMAC算法在机器人控制、自动驾驶、游戏AI等领域具有广泛的应用前景。它可以利用离线数据预训练一个较好的策略,然后通过在线微调快速适应新的环境和任务。这种方法可以显著降低训练成本,提高学习效率,并增强策略的鲁棒性。
📄 摘要(原文)
Modern offline Reinforcement Learning (RL) methods find performant actor-critics, however, fine-tuning these actor-critics online with value-based RL algorithms typically causes immediate drops in performance. We provide evidence consistent with the hypothesis that, in the loss landscape, offline maxima for prior algorithms and online maxima are separated by low-performance valleys that gradient-based fine-tuning traverses. Following this, we present Score Matched Actor-Critic (SMAC), an offline RL method designed to learn actor-critics that transition to online value-based RL algorithms with no drop in performance. SMAC avoids valleys between offline and online maxima by regularizing the Q-function during the offline phase to respect a first-order derivative equality between the score of the policy and action-gradient of the Q-function. We experimentally demonstrate that SMAC converges to offline maxima that are connected to better online maxima via paths with monotonically increasing reward found by first-order optimization. SMAC achieves smooth transfer to Soft Actor-Critic and TD3 in 6/6 D4RL tasks. In 4/6 environments, it reduces regret by 34-58% over the best baseline.