Retrospective In-Context Learning for Temporal Credit Assignment with Large Language Models
作者: Wen-Tse Chen, Jiayu Chen, Fahim Tajwar, Hao Zhu, Xintong Duan, Ruslan Salakhutdinov, Jeff Schneider
分类: cs.LG
发布日期: 2026-02-19
备注: Accepted to NeurIPS 2025
💡 一句话要点
提出基于大语言模型的回顾性上下文学习,解决强化学习中的时序信用分配问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 时序信用分配 大语言模型 上下文学习 样本效率
📋 核心要点
- 传统强化学习中,稀疏奖励下的时序信用分配问题,通常依赖于学习任务特定的价值函数,存在样本效率低和泛化性差的挑战。
- 论文提出回顾性上下文学习(RICL),利用大语言模型(LLM)的预训练知识,将稀疏奖励转化为密集的优势函数,从而进行有效的信用分配。
- 实验表明,RICL能准确估计优势函数,有效识别关键状态,RICOL在BabyAI环境中实现了与传统强化学习算法相当的性能,但样本效率显著提高。
📝 摘要(中文)
在训练自进化智能体时,如何从自采样数据和稀疏环境反馈中学习仍然是一个根本性的挑战。时序信用分配通过将稀疏反馈转化为密集的监督信号来缓解这个问题。然而,先前的方法通常依赖于学习特定于任务的价值函数来进行信用分配,这导致样本效率低下和泛化能力有限。本文提出利用大型语言模型(LLM)中的预训练知识,通过回顾性上下文学习(RICL)将稀疏奖励转化为密集的训练信号(即优势函数)。此外,还提出了一个在线学习框架RICOL,该框架基于RICL的信用分配结果迭代地改进策略。实验结果表明,RICL可以用有限的样本准确地估计优势函数,并有效地识别环境中用于时序信用分配的关键状态。在四个BabyAI场景中的扩展评估表明,RICOL实现了与传统在线强化学习算法相当的收敛性能,但样本效率显著提高。研究结果突出了利用LLM进行时序信用分配的潜力,为更高效和更具泛化性的强化学习范式铺平了道路。
🔬 方法详解
问题定义:论文旨在解决强化学习中,尤其是在稀疏奖励环境下,时序信用分配的难题。现有方法主要依赖于学习特定任务的价值函数,这需要大量的样本进行训练,导致样本效率低下,并且学到的价值函数难以泛化到新的任务或环境。
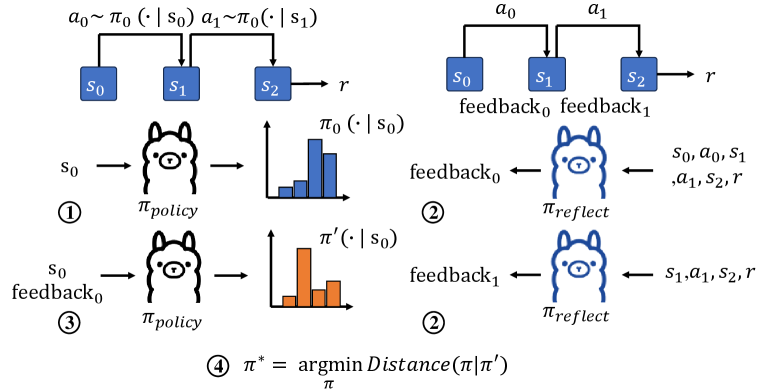
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大预训练知识,通过上下文学习的方式,将稀疏的奖励信号转化为密集的优势函数估计。具体来说,通过构建包含状态、动作和奖励的历史轨迹作为LLM的输入上下文,LLM可以根据其预训练的知识,推断出每个状态-动作对的优势,从而实现时序信用分配。
技术框架:论文提出了一个名为RICOL(Retrospective In-Context Online Learning)的在线学习框架。该框架包含两个主要阶段:1) 回顾性上下文学习(RICL):利用LLM对历史经验进行回顾,估计每个状态-动作对的优势函数。2) 在线策略优化:基于RICL估计的优势函数,使用标准的强化学习算法(如PPO)来更新策略。RICOL框架迭代地进行RICL和策略优化,从而不断提升智能体的性能。
关键创新:论文最重要的技术创新点在于将大型语言模型引入到时序信用分配问题中。与传统方法不同,RICL不需要学习特定任务的价值函数,而是直接利用LLM的预训练知识来估计优势函数。这种方法具有更高的样本效率和更好的泛化能力。此外,RICL通过回顾历史经验,可以更好地理解环境的动态特性,从而更准确地进行信用分配。
关键设计:在RICL中,关键的设计包括:1) 如何构建LLM的输入上下文,包括状态、动作、奖励等信息的表示方式。2) 如何选择合适的LLM,以及如何对LLM进行微调或提示工程,以使其更好地适应强化学习任务。3) 如何将LLM估计的优势函数与传统的强化学习算法相结合,以实现有效的策略优化。论文中使用了Transformer架构的LLM,并采用了一种基于提示的上下文学习方法,将历史轨迹转化为LLM可以理解的自然语言描述。
🖼️ 关键图片
📊 实验亮点
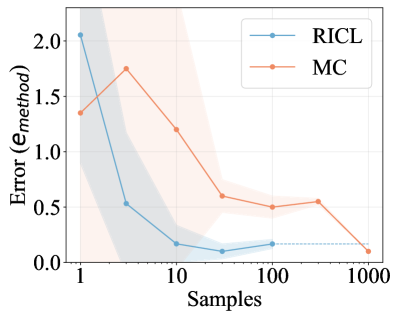
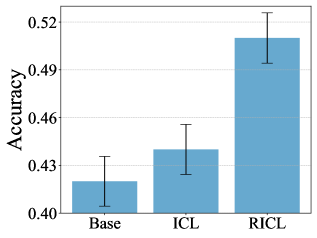
实验结果表明,RICL能够用有限的样本准确地估计优势函数,并有效识别环境中的关键状态。在BabyAI环境中,RICOL实现了与传统在线强化学习算法(如PPO)相当的收敛性能,但样本效率显著提高。具体来说,RICOL在某些任务上达到了与PPO相当的性能,但使用的样本数量减少了50%以上。
🎯 应用场景
该研究成果可应用于各种需要从稀疏奖励中学习的强化学习任务,例如机器人控制、游戏AI、自动驾驶等。通过利用大型语言模型的知识,可以显著提高强化学习的样本效率和泛化能力,从而降低训练成本,加速智能体的开发和部署。未来,该方法有望扩展到更复杂的任务和环境,实现更智能、更自主的智能体。
📄 摘要(原文)
Learning from self-sampled data and sparse environmental feedback remains a fundamental challenge in training self-evolving agents. Temporal credit assignment mitigates this issue by transforming sparse feedback into dense supervision signals. However, previous approaches typically depend on learning task-specific value functions for credit assignment, which suffer from poor sample efficiency and limited generalization. In this work, we propose to leverage pretrained knowledge from large language models (LLMs) to transform sparse rewards into dense training signals (i.e., the advantage function) through retrospective in-context learning (RICL). We further propose an online learning framework, RICOL, which iteratively refines the policy based on the credit assignment results from RICL. We empirically demonstrate that RICL can accurately estimate the advantage function with limited samples and effectively identify critical states in the environment for temporal credit assignment. Extended evaluation on four BabyAI scenarios show that RICOL achieves comparable convergent performance with traditional online RL algorithms with significantly higher sample efficiency. Our findings highlight the potential of leveraging LLMs for temporal credit assignment, paving the way for more sample-efficient and generalizable RL paradigms.