2Mamba2Furious: Linear in Complexity, Competitive in Accuracy
作者: Gabriel Mongaras, Eric C. Larson
分类: cs.LG
发布日期: 2026-02-19
💡 一句话要点
提出2Mamba,通过简化和改进Mamba-2,在长文本建模中实现精度与效率的平衡。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 线性注意力 Mamba-2 长文本建模 序列模型 高效计算
📋 核心要点
- 线性注意力模型在效率上优于传统Transformer,但精度通常低于softmax注意力机制。
- 论文通过简化Mamba-2模型,并改进A-mask和隐藏状态阶数,提出了2Mamba模型。
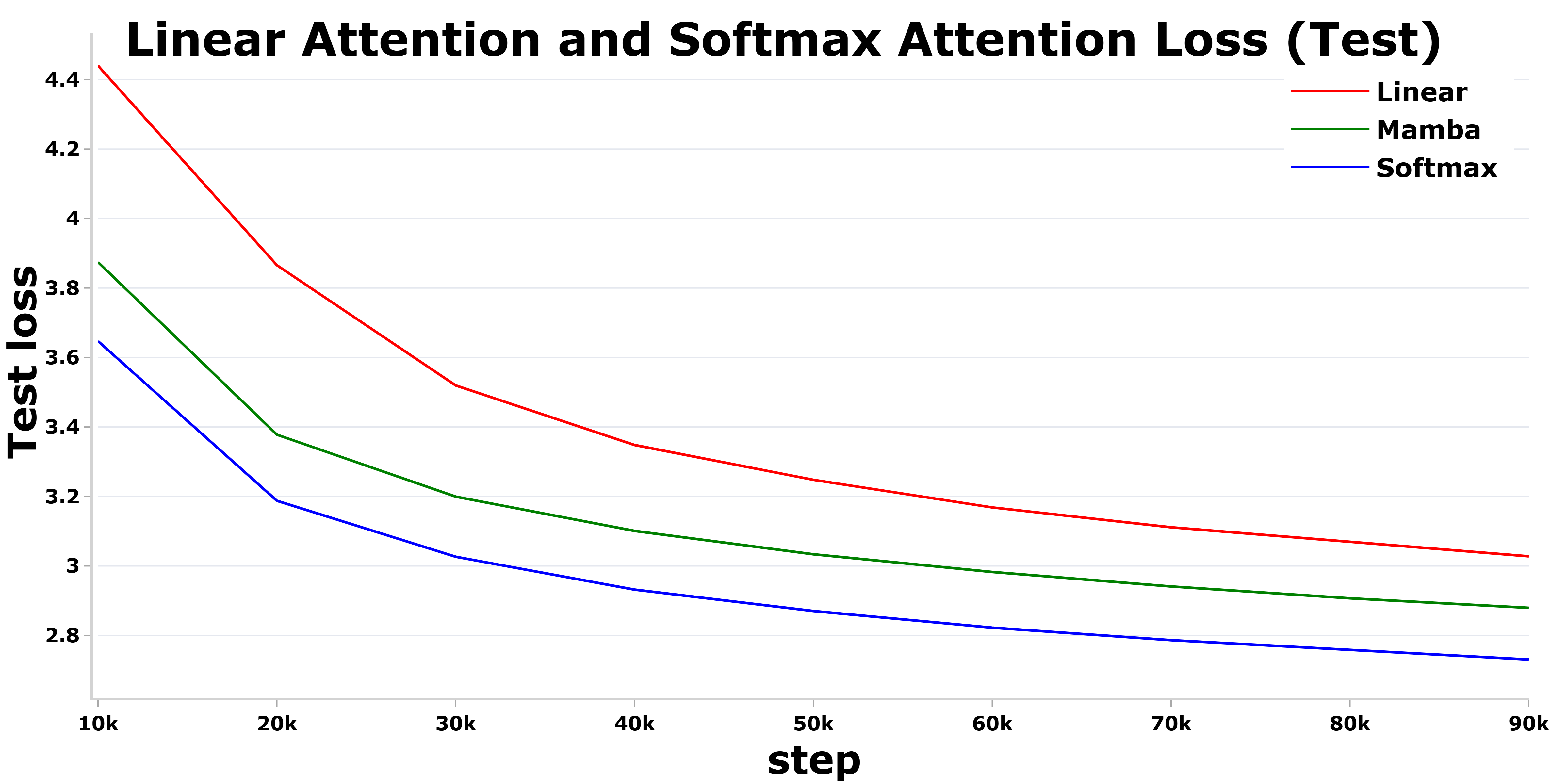
- 实验结果表明,2Mamba在长文本建模中,精度接近softmax注意力,同时保持了较高的内存效率。
📝 摘要(中文)
线性注意力Transformer因其效率而成为softmax注意力的有力替代方案。然而,线性注意力往往表达能力较弱,导致精度低于softmax注意力。为了弥合softmax注意力和线性注意力之间的精度差距,我们对Mamba-2(一种非常强大的线性注意力变体)进行了改进。我们首先将Mamba-2简化为最基本和最重要的组件,评估哪些特定选择使其最准确。从这种简化的Mamba变体(Mamba-2S)出发,我们改进了A-mask并增加了隐藏状态的阶数,从而得到了一种名为2Mamba的方法,该方法几乎与softmax注意力一样准确,但对于长上下文长度而言,内存效率更高。我们还研究了Mamba-2中哪些元素有助于超越softmax注意力的精度。提供了所有实验的代码。
🔬 方法详解
问题定义:论文旨在解决线性注意力模型在长文本建模中精度不足的问题。现有的线性注意力模型虽然计算效率高,但表达能力有限,导致在需要捕捉长距离依赖关系的场景下性能下降。softmax注意力模型虽然精度高,但计算复杂度高,难以处理长文本序列。
核心思路:论文的核心思路是通过简化和改进Mamba-2模型,在精度和效率之间取得平衡。首先,通过消融实验确定Mamba-2中最重要的组件,构建一个简化的Mamba-2S模型。然后,针对Mamba-2S的不足,改进A-mask机制,并增加隐藏状态的阶数,以提升模型的表达能力。
技术框架:2Mamba模型的整体框架基于Mamba-2。首先,对Mamba-2进行简化,得到Mamba-2S。然后,对Mamba-2S进行改进,主要包括两个方面:一是改进A-mask机制,二是增加隐藏状态的阶数。最终得到的2Mamba模型用于长文本建模任务。
关键创新:论文的关键创新在于对Mamba-2的简化和改进。通过消融实验,确定了Mamba-2中最重要的组件,并在此基础上进行了改进。改进A-mask机制和增加隐藏状态的阶数,有效地提升了模型的表达能力,使其在精度上接近softmax注意力模型。
关键设计:关于A-mask的改进细节和隐藏状态阶数的具体数值在论文中未明确给出,属于未知信息。论文提供了实验代码,可能包含这些细节。损失函数和网络结构等其他技术细节也未在摘要中提及,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文提出的2Mamba模型在长文本建模任务中取得了显著的性能提升。具体的数据和对比基线未在摘要中给出,需要查阅论文全文才能获取。摘要中提到2Mamba模型在精度上接近softmax注意力模型,同时保持了较高的内存效率,这表明该模型在精度和效率之间取得了较好的平衡。
🎯 应用场景
该研究成果可应用于各种需要处理长文本序列的场景,例如自然语言处理中的机器翻译、文本摘要、对话生成等。2Mamba模型在保证精度的同时,具有较高的内存效率,使其能够处理更长的文本序列,从而提升相关应用的性能。该研究也为未来线性注意力模型的设计提供了新的思路。
📄 摘要(原文)
Linear attention transformers have become a strong alternative to softmax attention due to their efficiency. However, linear attention tends to be less expressive and results in reduced accuracy compared to softmax attention. To bridge the accuracy gap between softmax attention and linear attention, we manipulate Mamba-2, a very strong linear attention variant. We first simplify Mamba-2 down to its most fundamental and important components, evaluating which specific choices make it most accurate. From this simplified Mamba variant (Mamba-2S), we improve the A-mask and increase the order of the hidden state, resulting in a method, which we call 2Mamba, that is nearly as accurate as softmax attention, yet much more memory efficient for long context lengths. We also investigate elements to Mamba-2 that help surpass softmax attention accuracy. Code is provided for all our experiments