RLGT: A reinforcement learning framework for extremal graph theory
作者: Ivan Damnjanović, Uroš Milivojević, Irena Đorđević, Dragan Stevanović
分类: cs.LG, math.CO
发布日期: 2026-02-19
💡 一句话要点
提出RLGT框架,系统化图论极值问题,提升强化学习求解效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 图论 极值问题 组合优化 图神经网络
📋 核心要点
- 现有方法在图论极值问题上缺乏通用性,难以处理不同类型的图结构和边着色。
- RLGT框架通过模块化设计和高效的图表示,支持多种图类型和边着色,提升了通用性。
- RLGT框架优化了计算性能,为未来基于强化学习的图论极值问题研究提供了便利。
📝 摘要(中文)
强化学习(RL)是机器学习的一个子领域,专注于开发能够自主学习最优决策策略的模型。最近,Wagner在一篇开创性的论文中展示了如何应用深度交叉熵RL方法来解决图论极值问题,将其重新表述为组合优化问题。随后,许多研究人员对改进和扩展Wagner提出的框架产生了兴趣,从而创建了各种专门用于图论的RL环境。此外,许多图论极值问题通过RL得到了解决。特别地,一些关于图的拉普拉斯谱半径的不等式被驳斥,某些拉姆齐数获得了新的下界,并且对禁止结构为长度为3和4的循环的Turán型极值问题做出了贡献。本文提出了图论强化学习(RLGT),这是一个新颖的RL框架,它系统化了之前的工作,并支持有向和无向图,无论是否带有环,以及任意数量的边颜色。该框架有效地表示图,并通过优化的计算性能和清晰的模块化设计,旨在促进未来基于RL的图论极值研究。
🔬 方法详解
问题定义:论文旨在解决图论极值问题,现有方法通常针对特定问题设计,缺乏通用性,难以处理不同类型的图(有向图、无向图、带环图等)以及不同数量的边颜色。此外,现有方法在计算效率方面可能存在瓶颈,限制了其在更大规模问题上的应用。
核心思路:论文的核心思路是将图论极值问题建模为强化学习任务,通过智能体与环境的交互,学习构造满足特定极值性质的图。通过设计合适的奖励函数,引导智能体探索更优的图结构。框架的核心在于提供一个通用的、高效的强化学习环境,支持多种图类型和边着色,并优化计算性能。
技术框架:RLGT框架包含以下主要模块:1) 图表示模块:用于高效地存储和操作图结构,支持有向图、无向图、带环图等;2) 强化学习环境模块:定义了智能体与图的交互方式,包括状态表示、动作空间和奖励函数;3) 强化学习算法模块:集成了多种强化学习算法,如深度交叉熵方法,用于训练智能体;4) 评估模块:用于评估智能体生成的图的性能,例如,是否满足特定的极值性质。
关键创新:RLGT框架的关键创新在于其通用性和高效性。它通过模块化设计,支持多种图类型和边着色,避免了为每个特定问题设计专门的强化学习环境。此外,框架优化了图表示和计算性能,使其能够处理更大规模的图论极值问题。
关键设计:论文中可能涉及的关键设计包括:1) 图表示方法:例如,使用邻接矩阵或邻接表来存储图结构,并采用稀疏矩阵技术来优化存储空间;2) 奖励函数设计:奖励函数需要能够有效地引导智能体探索更优的图结构,例如,可以根据图的特定性质(如拉普拉斯谱半径、拉姆齐数等)来设计奖励函数;3) 强化学习算法选择:选择合适的强化学习算法对于训练智能体至关重要,例如,可以使用深度交叉熵方法或策略梯度方法。
🖼️ 关键图片
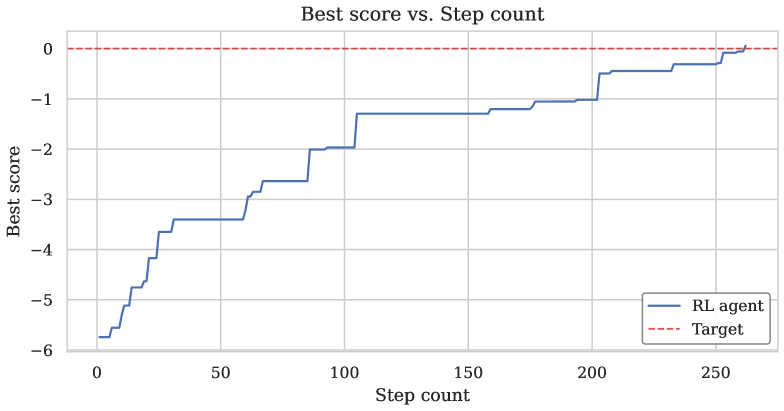
📊 实验亮点
RLGT框架通过系统化图论极值问题,并提供对有向图、无向图以及带环图的支持,在计算性能上进行了优化,为未来的强化学习研究奠定了基础。论文验证了该框架在解决拉普拉斯谱半径不等式、拉姆齐数下界以及Turán型极值问题上的有效性,但具体性能数据和提升幅度未知。
🎯 应用场景
RLGT框架可应用于多个领域,包括通信网络设计、社交网络分析、生物信息学等。通过优化图的结构,可以提高网络的性能、发现隐藏的模式和关系,并解决实际问题。该框架的通用性和高效性使其能够适应不同的应用场景,并为相关领域的研究提供新的思路和方法。
📄 摘要(原文)
Reinforcement learning (RL) is a subfield of machine learning that focuses on developing models that can autonomously learn optimal decision-making strategies over time. In a recent pioneering paper, Wagner demonstrated how the Deep Cross-Entropy RL method can be applied to tackle various problems from extremal graph theory by reformulating them as combinatorial optimization problems. Subsequently, many researchers became interested in refining and extending the framework introduced by Wagner, thereby creating various RL environments specialized for graph theory. Moreover, a number of problems from extremal graph theory were solved through the use of RL. In particular, several inequalities concerning the Laplacian spectral radius of graphs were refuted, new lower bounds were obtained for certain Ramsey numbers, and contributions were made to the Turán-type extremal problem in which the forbidden structures are cycles of length three and four. Here, we present Reinforcement Learning for Graph Theory (RLGT), a novel RL framework that systematizes the previous work and provides support for both undirected and directed graphs, with or without loops, and with an arbitrary number of edge colors. The framework efficiently represents graphs and aims to facilitate future RL-based research in extremal graph theory through optimized computational performance and a clean and modular design.