Powering Up Zeroth-Order Training via Subspace Gradient Orthogonalization
作者: Yicheng Lang, Changsheng Wang, Yihua Zhang, Mingyi Hong, Zheng Zhang, Wotao Yin, Sijia Liu
分类: cs.LG
发布日期: 2026-02-19
💡 一句话要点
ZO-Muon:基于子空间梯度正交化的零阶优化方法,提升大模型微调效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零阶优化 梯度估计 子空间投影 梯度正交化 大模型微调 Muon优化器 低秩结构
📋 核心要点
- 零阶优化在大型模型微调中面临精度和查询效率的根本矛盾,梯度估计方差大,收敛速度慢。
- 论文提出子空间梯度正交化框架,结合低秩结构投影和Muon风格谱优化,降低方差并提取信息。
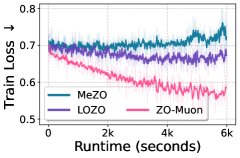
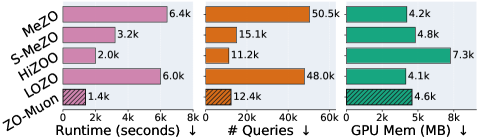
- 实验表明,ZO-Muon在LLM和ViT微调中显著加速收敛,提升精度和查询效率,优于MeZO等基线。
📝 摘要(中文)
本文提出了一种基于子空间梯度正交化的零阶(ZO)优化方法,旨在提高ZO优化在大型模型微调中的效率。ZO优化通过函数评估的有限差分来估计梯度,避免了反向传播,从而节省内存。然而,ZO优化在精度和查询效率之间存在根本矛盾。本文通过统一两个互补原则来显著改进ZO优化:(i)基于投影的子空间视角,通过利用模型更新的内在低秩结构来减少梯度估计方差;(ii)Muon风格的谱优化,应用梯度正交化从噪声ZO梯度中提取信息丰富的谱结构。这些发现构成了一个子空间梯度正交化的统一框架,我们在一种新方法ZO-Muon中实例化该框架,该方法可以自然地解释为ZO设置中的低秩Muon优化器。在大型语言模型(LLM)和视觉Transformer(ViT)上的大量实验表明,ZO-Muon显著加速了收敛,并在精度和查询/运行时效率方面实现了双赢的改进。值得注意的是,与流行的MeZO基线相比,ZO-Muon仅需要24.7%的查询即可达到LLM微调的相同SST-2性能,并在CIFAR-100上的ViT-B微调中将精度提高了25.1%。
🔬 方法详解
问题定义:论文旨在解决零阶优化(ZO)在微调大型模型时效率低下的问题。传统的ZO方法依赖于有限差分来估计梯度,这在参数量巨大的模型中需要大量的函数查询,导致计算成本高昂。此外,由于梯度估计的方差较大,ZO方法的收敛速度通常较慢,难以达到理想的性能。现有方法,如MeZO,虽然在一定程度上提高了效率,但仍然存在改进空间。
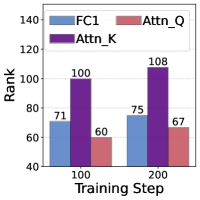
核心思路:论文的核心思路是利用模型更新的内在低秩结构,并结合梯度正交化技术来提高ZO优化的效率和精度。具体来说,论文认为模型参数的更新通常位于一个低维子空间内,因此可以通过投影到该子空间来减少梯度估计的方差。同时,借鉴Muon优化器的思想,通过梯度正交化来提取噪声ZO梯度中的信息丰富的谱结构,从而加速收敛。
技术框架:ZO-Muon方法主要包含以下几个阶段:1) 子空间投影:首先,通过随机采样或历史梯度信息估计模型更新的低维子空间。2) 梯度估计:在子空间内进行ZO梯度估计,降低方差。3) 梯度正交化:应用Muon风格的谱优化,对估计的梯度进行正交化处理,提取信息丰富的谱结构。4) 参数更新:使用正交化后的梯度更新模型参数。
关键创新:论文的关键创新在于将子空间投影和梯度正交化两种技术有机结合,形成一个统一的框架。子空间投影降低了梯度估计的方差,而梯度正交化则提取了噪声梯度中的有用信息。这种结合使得ZO-Muon方法能够在保证精度的同时,显著提高查询效率。与现有方法相比,ZO-Muon方法能够更有效地利用有限的函数查询,从而加速模型微调过程。
关键设计:ZO-Muon的关键设计包括:1) 子空间维度选择:需要根据具体任务和模型选择合适的子空间维度,以平衡方差降低和计算复杂度。2) 梯度正交化参数:Muon风格的谱优化需要设置合适的参数,以控制正交化的强度。3) 步长调整:需要根据梯度估计的质量和模型更新的幅度动态调整步长,以保证收敛的稳定性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ZO-Muon在LLM和ViT微调任务中均取得了显著的性能提升。在LLM微调中,ZO-Muon仅需MeZO 24.7%的查询次数即可达到相同的SST-2性能。在ViT-B微调中,ZO-Muon在CIFAR-100数据集上将精度提高了25.1%。这些结果充分证明了ZO-Muon方法在提高ZO优化效率和精度方面的有效性。
🎯 应用场景
该研究成果可广泛应用于大型语言模型、视觉Transformer等模型的微调任务中,尤其是在计算资源受限或无法进行反向传播的场景下。例如,在边缘设备上部署大型模型时,可以使用ZO-Muon方法进行高效的微调,从而提高模型的性能。此外,该方法还可以应用于黑盒优化、对抗攻击等领域,具有重要的实际价值和广阔的应用前景。
📄 摘要(原文)
Zeroth-order (ZO) optimization provides a gradient-free alternative to first-order (FO) methods by estimating gradients via finite differences of function evaluations, and has recently emerged as a memory-efficient paradigm for fine-tuning large-scale models by avoiding backpropagation. However, ZO optimization has a fundamental tension between accuracy and query efficiency. In this work, we show that ZO optimization can be substantially improved by unifying two complementary principles: (i) a projection-based subspace view that reduces gradient estimation variance by exploiting the intrinsic low-rank structure of model updates, and (ii) Muon-style spectral optimization that applies gradient orthogonalization to extract informative spectral structure from noisy ZO gradients. These findings form a unified framework of subspace gradient orthogonalization, which we instantiate in a new method, ZO-Muon, admitting a natural interpretation as a low-rank Muon optimizer in the ZO setting. Extensive experiments on large language models (LLMs) and vision transformers (ViTs) demonstrate that ZO-Muon significantly accelerates convergence and achieves a win-win improvement in accuracy and query/runtime efficiency. Notably, compared to the popular MeZO baseline, ZO-Muon requires only 24.7% of the queries to reach the same SST-2 performance for LLM fine-tuning, and improves accuracy by 25.1% on ViT-B fine-tuning on CIFAR-100.