VP-VAE: Rethinking Vector Quantization via Adaptive Vector Perturbation
作者: Linwei Zhai, Han Ding, Mingzhi Lin, Cui Zhao, Fei Wang, Ge Wang, Wang Zhi, Wei Xi
分类: cs.LG, cs.AI
发布日期: 2026-02-19
💡 一句话要点
VP-VAE:通过自适应向量扰动改进向量量化变分自编码器
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 向量量化 变分自编码器 生成模型 离散表示 自适应扰动
📋 核心要点
- VQ-VAE训练不稳定,易出现码本崩溃,原因是表征学习与码本优化耦合。
- VP-VAE通过引入自适应向量扰动,将表征学习与离散化解耦,无需显式码本。
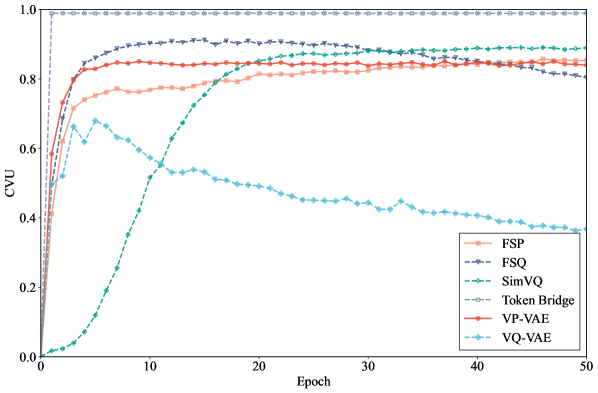
- 实验表明,VP-VAE和FSP提高了重建质量,平衡了token使用,避免了训练不稳定。
📝 摘要(中文)
向量量化变分自编码器(VQ-VAEs)是现代生成建模的基础,但由于表征学习和离散码本优化之间固有的耦合,它们经常遭受训练不稳定和“码本崩溃”的困扰。本文提出了VP-VAE(向量扰动VAE),这是一种新颖的范例,通过消除训练期间对显式码本的需求,将表征学习与离散化解耦。我们的关键见解是,从神经网络的角度来看,执行量化主要表现为在潜在空间中注入结构化扰动。因此,VP-VAE用通过Metropolis-Hastings采样生成的、分布一致且尺度自适应的潜在扰动来代替不可微的量化器。这种设计能够在没有码本的情况下实现稳定的训练,同时使模型对推理时的量化误差具有鲁棒性。此外,在近似均匀潜在变量的假设下,我们推导出了FSP(有限标量扰动),它是VP-VAE的一个轻量级变体,为FSQ风格的固定量化器提供了统一的理论解释和实际改进。在图像和音频基准上的大量实验表明,VP-VAE和FSP提高了重建保真度,并实现了更平衡的token使用,同时避免了耦合码本训练固有的不稳定性。
🔬 方法详解
问题定义:VQ-VAE在生成建模中至关重要,但其训练过程容易出现不稳定性和码本崩溃。这是由于表征学习和离散码本优化紧密耦合导致的。现有的VQ-VAE方法需要维护一个显式的码本,并在训练过程中不断更新码本,这使得训练过程复杂且不稳定。
核心思路:VP-VAE的核心思想是将量化过程视为在潜在空间中注入结构化的扰动。通过模拟这种扰动,可以避免使用显式的码本,从而将表征学习与离散化过程解耦。这种解耦可以提高训练的稳定性,并使模型对量化误差更加鲁棒。
技术框架:VP-VAE的整体框架仍然是一个变分自编码器(VAE),但其关键区别在于量化过程的处理方式。传统的VQ-VAE使用一个离散的码本进行量化,而VP-VAE则使用一个连续的扰动分布来模拟量化过程。具体来说,VP-VAE使用Metropolis-Hastings采样来生成分布一致且尺度自适应的潜在扰动。编码器将输入映射到潜在空间,然后将扰动添加到潜在变量中,解码器则从扰动后的潜在变量重建输入。
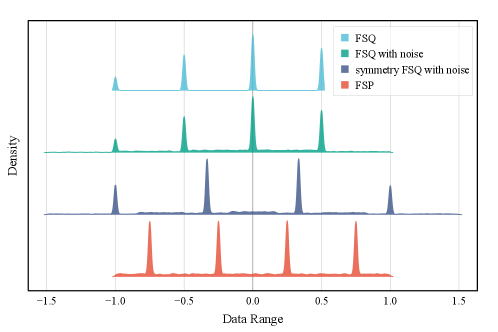
关键创新:VP-VAE最重要的创新在于它避免了使用显式的码本,而是通过模拟量化过程中的扰动来实现离散化。这种方法将表征学习与离散化解耦,从而提高了训练的稳定性。此外,VP-VAE还提出了FSP(有限标量扰动),它是VP-VAE的一个轻量级变体,为FSQ风格的固定量化器提供了统一的理论解释和实际改进。
关键设计:VP-VAE的关键设计包括:1) 使用Metropolis-Hastings采样生成分布一致的扰动;2) 使用尺度自适应的扰动,以便更好地适应不同的潜在变量;3) 引入FSP作为VP-VAE的轻量级变体,简化计算并提高效率。损失函数包括重建损失和正则化项,用于约束潜在空间的分布。网络结构采用标准的VAE结构,可以根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,VP-VAE在图像和音频基准测试中均取得了显著的性能提升。与传统的VQ-VAE相比,VP-VAE提高了重建保真度,并实现了更平衡的token使用。例如,在图像生成任务中,VP-VAE的FID得分优于VQ-VAE,并且避免了码本崩溃的问题。此外,FSP作为VP-VAE的轻量级变体,也取得了与VP-VAE相近的性能,同时计算效率更高。
🎯 应用场景
VP-VAE在图像和音频生成领域具有广泛的应用前景。它可以用于生成高质量的图像和音频样本,也可以用于图像和音频的压缩和编码。此外,VP-VAE还可以应用于其他需要离散表示的领域,例如自然语言处理和强化学习。该研究的实际价值在于提高了生成模型的训练稳定性和生成质量,未来可能推动生成模型在更多领域的应用。
📄 摘要(原文)
Vector Quantized Variational Autoencoders (VQ-VAEs) are fundamental to modern generative modeling, yet they often suffer from training instability and "codebook collapse" due to the inherent coupling of representation learning and discrete codebook optimization. In this paper, we propose VP-VAE (Vector Perturbation VAE), a novel paradigm that decouples representation learning from discretization by eliminating the need for an explicit codebook during training. Our key insight is that, from the neural network's viewpoint, performing quantization primarily manifests as injecting a structured perturbation in latent space. Accordingly, VP-VAE replaces the non-differentiable quantizer with distribution-consistent and scale-adaptive latent perturbations generated via Metropolis--Hastings sampling. This design enables stable training without a codebook while making the model robust to inference-time quantization error. Moreover, under the assumption of approximately uniform latent variables, we derive FSP (Finite Scalar Perturbation), a lightweight variant of VP-VAE that provides a unified theoretical explanation and a practical improvement for FSQ-style fixed quantizers. Extensive experiments on image and audio benchmarks demonstrate that VP-VAE and FSP improve reconstruction fidelity and achieve substantially more balanced token usage, while avoiding the instability inherent to coupled codebook training.