FLoRG: Federated Fine-tuning with Low-rank Gram Matrices and Procrustes Alignment
作者: Chuiyang Meng, Ming Tang, Vincent W. S. Wong
分类: cs.LG, cs.AI
发布日期: 2026-02-19
💡 一句话要点
FLoRG:基于低秩Gram矩阵和Procrustes对齐的联邦微调方法,解决分解漂移问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 参数高效微调 低秩适应 Gram矩阵 Procrustes对齐 大型语言模型 分解漂移
📋 核心要点
- 现有联邦学习中基于LoRA的微调方法,分别聚合低秩矩阵或进行矩阵分解时,会引入误差和分解漂移,影响模型性能。
- FLoRG通过聚合单一低秩矩阵的Gram矩阵,避免了聚合误差,并利用Procrustes对齐减少连续轮次间的分解漂移,保证更新一致性。
- 实验证明,FLoRG在多个LLM微调任务中,显著提升了下游任务的准确性,并大幅降低了通信开销,优于现有方法。
📝 摘要(中文)
本文提出FLoRG,一种联邦微调框架,旨在解决在联邦学习中对大型语言模型(LLM)进行参数高效微调时遇到的挑战。现有方法如LoRA在联邦场景下,由于分别聚合低秩矩阵或进行矩阵分解时存在误差和分解漂移。FLoRG采用单一低秩矩阵进行微调,并聚合其Gram矩阵(列向量内积矩阵),消除了聚合误差,降低了通信开销。通过引入Procrustes对齐方法,FLoRG最小化了连续微调轮次之间的分解漂移,保证更新的一致性。理论分析表明,Procrustes对齐能收紧收敛界。实验结果表明,在多个LLM微调基准测试中,FLoRG优于五种最先进的基线方案,并在下游任务准确性方面表现出色,同时可将通信开销降低高达2041倍。
🔬 方法详解
问题定义:在联邦学习场景下,如何高效且准确地对大型语言模型进行微调是一个关键问题。现有的基于LoRA的联邦微调方法,由于需要聚合两个独立的低秩矩阵,或者在服务器端进行矩阵分解以恢复低秩因子,会引入聚合误差和分解漂移,导致模型性能下降,同时增加通信开销。
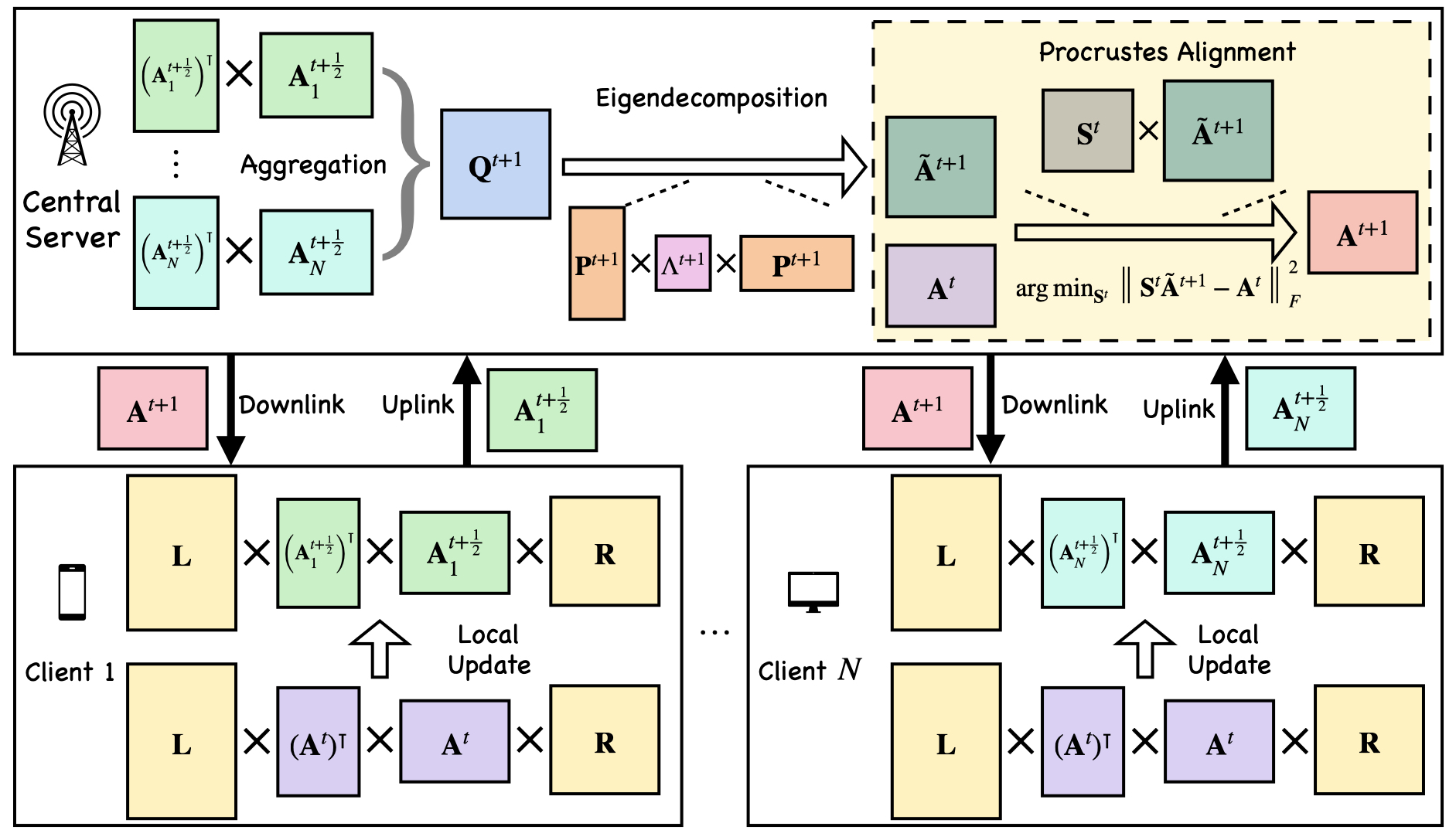
核心思路:FLoRG的核心思路是使用单个低秩矩阵进行微调,并聚合其Gram矩阵。Gram矩阵包含了低秩矩阵列向量之间的内积信息,避免了直接聚合低秩矩阵带来的误差。同时,通过在服务器端对分解后的矩阵进行Procrustes对齐,减少了连续微调轮次之间的分解漂移,保证了模型更新的一致性。
技术框架:FLoRG的整体框架包括以下几个主要步骤:1) 客户端使用单个低秩矩阵进行本地微调;2) 客户端将低秩矩阵的Gram矩阵上传到服务器;3) 服务器聚合来自各个客户端的Gram矩阵;4) 服务器对聚合后的Gram矩阵进行矩阵分解,得到低秩矩阵;5) 服务器使用Procrustes对齐方法,将当前轮次的低秩矩阵与上一轮次的低秩矩阵进行对齐,减少分解漂移;6) 服务器将对齐后的低秩矩阵发送给客户端,进行下一轮的微调。
关键创新:FLoRG最重要的技术创新点在于:1) 使用Gram矩阵进行聚合,避免了直接聚合低秩矩阵带来的误差;2) 引入Procrustes对齐方法,减少了连续微调轮次之间的分解漂移。与现有方法相比,FLoRG能够更准确地聚合来自不同客户端的模型更新,并保证模型更新的一致性,从而提高模型性能。
关键设计:FLoRG的关键设计包括:1) 低秩矩阵的秩的选择:需要根据具体的任务和模型大小进行调整,以平衡模型性能和通信开销;2) Procrustes对齐的实现:可以使用奇异值分解(SVD)等方法来实现Procrustes对齐,以找到两个矩阵之间的最优旋转变换;3) 聚合策略的选择:可以使用平均聚合等方法来聚合来自不同客户端的Gram矩阵。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FLoRG在多个LLM微调基准测试中,显著优于五种最先进的基线方案。例如,在某些任务上,FLoRG的下游任务准确性提升了多个百分点。更重要的是,FLoRG能够将通信开销降低高达2041倍,这使得在资源受限的联邦学习环境中进行大规模模型微调成为可能。
🎯 应用场景
FLoRG可应用于各种需要联邦学习的场景,例如医疗健康、金融风控、自动驾驶等。在这些场景中,数据分布在不同的客户端,且数据隐私非常重要。FLoRG可以在保护数据隐私的前提下,高效地对大型语言模型进行微调,从而提升模型在各个客户端上的性能,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Parameter-efficient fine-tuning techniques such as low-rank adaptation (LoRA) enable large language models (LLMs) to adapt to downstream tasks efficiently. Federated learning (FL) further facilitates this process by enabling collaborative fine-tuning across distributed clients without sharing private data. However, the use of two separate low-rank matrices in LoRA for federated fine-tuning introduces two types of challenges. The first challenge arises from the error induced by separately aggregating those two low-rank matrices. The second challenge occurs even when the product of two low-rank matrices is aggregated. The server needs to recover factors via matrix decomposition, which is non-unique and can introduce decomposition drift. To tackle the aforementioned challenges, we propose FLoRG, a federated fine-tuning framework which employs a single low-rank matrix for fine-tuning and aggregates its Gram matrix (i.e., the matrix of inner products of its column vectors), eliminating the aggregation error while also reducing the communication overhead. FLoRG minimizes the decomposition drift by introducing a Procrustes alignment approach which aligns the decomposed matrix between consecutive fine-tuning rounds for consistent updates. We theoretically analyze the convergence of FLoRG and prove that adopting the Procrustes alignment results in a tighter convergence bound. Experimental results across multiple LLM fine-tuning benchmarks demonstrate that FLoRG outperforms five state-of-the-art baseline schemes in the downstream task accuracy and can reduce the communication overhead by up to 2041$\times$.