MeGU: Machine-Guided Unlearning with Target Feature Disentanglement
作者: Haoyu Wang, Zhuo Huang, Xiaolong Wang, Bo Han, Zhiwei Lin, Tongliang Liu
分类: cs.LG
发布日期: 2026-02-19
💡 一句话要点
提出MeGU,通过目标特征解耦实现机器引导的有效率的机器学习遗忘
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器学习遗忘 数据隐私 特征解耦 多模态学习 大语言模型 概念感知 模型安全
📋 核心要点
- 现有机器学习遗忘方法在消除目标数据影响和保持模型效用之间存在权衡,难以兼顾。
- MeGU通过多模态大语言模型引导的概念感知重对齐,实现选择性遗忘,解耦目标特征。
- 实验表明,MeGU能有效缓解遗忘不足和过度遗忘问题,在遗忘性能和模型效用上取得平衡。
📝 摘要(中文)
对训练数据隐私日益增长的担忧,使得“被遗忘权”成为一项关键需求,从而提高了对有效机器学习遗忘的需求。然而,现有的遗忘方法通常面临一个根本性的权衡:激进地消除目标数据的影响通常会降低模型在保留数据上的效用,而保守的策略则会完整地保留残余的目标信息。本文分析了模型预训练期间学习到的内在表示属性,证明了语义类概念在特征模式层面是纠缠的,共享相关特征,同时保留概念特定的判别成分。这种纠缠从根本上限制了现有遗忘范式的有效性。受此启发,我们提出了一种机器引导的遗忘(MeGU)框架,该框架通过概念感知的重新对齐来引导遗忘。具体来说,利用多模态大型语言模型(MLLM)通过分配语义上有意义的扰动标签来显式地确定目标样本的重新对齐方向。为了提高效率,MLLM估计的类间概念相似性被编码成一个轻量级的转移矩阵。此外,MeGU引入了一个正负特征噪声对,以显式地解耦目标概念的影响。在微调期间,负噪声抑制特定于目标的特征模式,而正噪声增强剩余的相关特征,并将它们与扰动概念对齐。这种协调设计能够选择性地破坏特定于目标的表示,同时保留共享的语义结构。因此,MeGU实现了可控和选择性的遗忘,有效地缓解了遗忘不足和过度遗忘。
🔬 方法详解
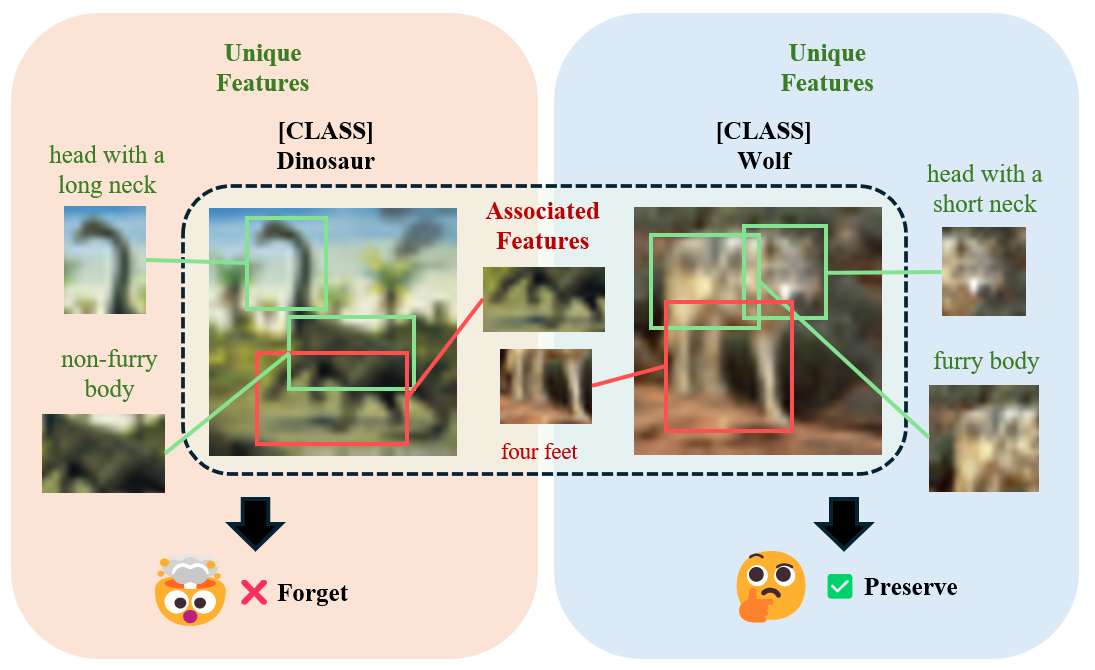
问题定义:机器学习遗忘旨在从已训练的模型中移除特定训练数据的影响,同时尽可能保留模型在剩余数据上的性能。现有方法要么过度遗忘,导致模型在保留数据上的性能下降;要么遗忘不足,目标数据的信息仍然存在于模型中。根本原因是模型学习到的特征表示中,不同类别的信息相互纠缠,难以精确移除目标类别的影响。
核心思路:MeGU的核心思路是利用多模态大语言模型(MLLM)的语义理解能力,指导模型进行概念感知的特征重对齐。通过MLLM为目标样本分配语义相关的扰动标签,并设计正负噪声对来解耦目标概念的影响,从而实现更精确的遗忘。
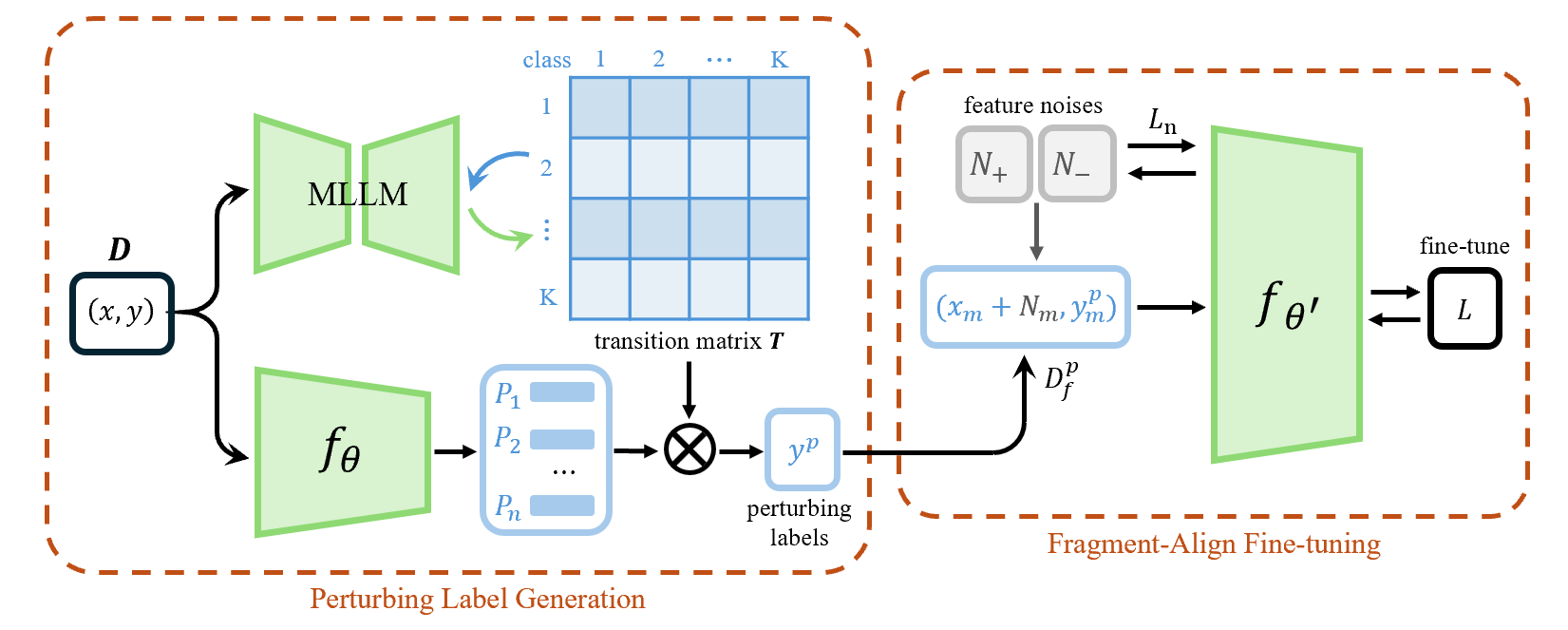
技术框架:MeGU框架主要包含以下几个阶段:1) MLLM引导的扰动标签生成:使用MLLM为目标样本生成语义相关的扰动标签,这些标签代表了与目标类别相似但不同的概念。2) 类间概念相似性编码:利用MLLM估计类间概念的相似性,并将其编码为一个轻量级的转移矩阵,用于指导特征重对齐。3) 正负特征噪声注入:为目标样本注入正负特征噪声对,负噪声用于抑制特定于目标类别的特征模式,正噪声用于增强剩余的相关特征,并将它们与扰动概念对齐。4) 微调:使用带有扰动标签和噪声的样本对模型进行微调,以实现目标数据的遗忘和模型效用的保持。
关键创新:MeGU的关键创新在于:1) 概念感知的遗忘引导:利用MLLM的语义理解能力,为遗忘过程提供更精确的指导,避免了盲目地删除目标数据的影响。2) 正负特征噪声对的设计:通过正负噪声的协同作用,实现了目标特征的解耦和重对齐,从而更有效地移除目标数据的影响,同时保留模型的泛化能力。
关键设计:1) MLLM的选择:论文选择了具有强大语义理解能力的MLLM,例如CLIP,用于生成扰动标签和估计类间相似性。2) 噪声的生成方式:正负噪声通过对目标样本的特征进行扰动生成,扰动的大小和方向由MLLM提供的语义信息指导。3) 损失函数的设计:损失函数包含遗忘损失和保留损失,遗忘损失鼓励模型忘记目标数据,保留损失鼓励模型保持在保留数据上的性能。
🖼️ 关键图片
📊 实验亮点
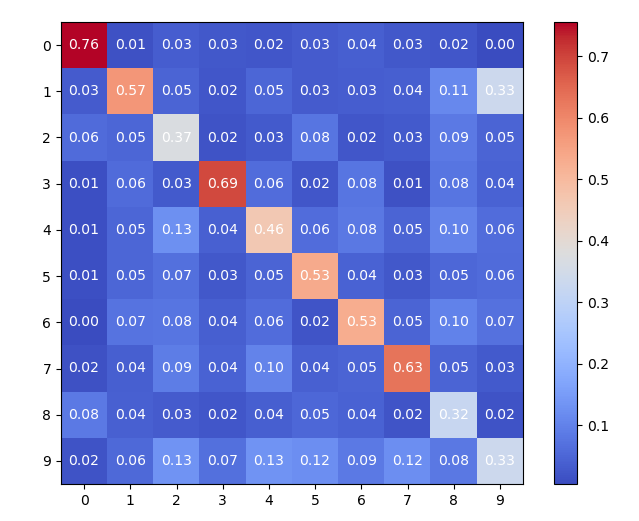
实验结果表明,MeGU在多个数据集上都取得了显著的遗忘效果,同时保持了模型在保留数据上的高性能。例如,在CIFAR-10数据集上,MeGU在遗忘目标类别后,模型在剩余类别上的准确率仅下降了不到1%,显著优于其他基线方法。此外,MeGU还表现出良好的泛化能力,在不同的模型架构和数据集上都能有效工作。
🎯 应用场景
MeGU可应用于各种需要保护用户数据隐私的场景,例如联邦学习、个性化推荐和安全AI。通过选择性地遗忘用户数据,MeGU可以在保护用户隐私的同时,保持模型的整体性能。此外,MeGU还可以用于修复模型中的偏见或漏洞,提高模型的安全性和可靠性。
📄 摘要(原文)
The growing concern over training data privacy has elevated the "Right to be Forgotten" into a critical requirement, thereby raising the demand for effective Machine Unlearning. However, existing unlearning approaches commonly suffer from a fundamental trade-off: aggressively erasing the influence of target data often degrades model utility on retained data, while conservative strategies leave residual target information intact. In this work, the intrinsic representation properties learned during model pretraining are analyzed. It is demonstrated that semantic class concepts are entangled at the feature-pattern level, sharing associated features while preserving concept-specific discriminative components. This entanglement fundamentally limits the effectiveness of existing unlearning paradigms. Motivated by this insight, we propose Machine-Guided Unlearning (MeGU), a novel framework that guides unlearning through concept-aware re-alignment. Specifically, Multi-modal Large Language Models (MLLMs) are leveraged to explicitly determine re-alignment directions for target samples by assigning semantically meaningful perturbing labels. To improve efficiency, inter-class conceptual similarities estimated by the MLLM are encoded into a lightweight transition matrix. Furthermore, MeGU introduces a positive-negative feature noise pair to explicitly disentangle target concept influence. During finetuning, the negative noise suppresses target-specific feature patterns, while the positive noise reinforces remaining associated features and aligns them with perturbing concepts. This coordinated design enables selective disruption of target-specific representations while preserving shared semantic structures. As a result, MeGU enables controlled and selective forgetting, effectively mitigating both under-unlearning and over-unlearning.