Adam Improves Muon: Adaptive Moment Estimation with Orthogonalized Momentum
作者: Minxin Zhang, Yuxuan Liu, Hayden Scheaffer
分类: cs.LG, math.OC
发布日期: 2026-02-19
备注: 39 pages, 6 figures
💡 一句话要点
提出NAMO与NAMO-D优化器,将正交动量与自适应矩估计相结合,提升大语言模型训练效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 优化算法 正交动量 自适应矩估计 大语言模型 GPT-2 随机优化 噪声自适应
📋 核心要点
- 现有优化器在处理大语言模型训练时,难以兼顾确定性优化方向和随机扰动适应性,例如Adam稳定但可能收敛慢,Muon利用正交动量但缺乏噪声自适应。
- 论文提出NAMO和NAMO-D,将正交动量与Adam型噪声自适应相结合。NAMO通过自适应步长缩放正交动量,NAMO-D则使用对角矩阵进行神经元级别的噪声自适应。
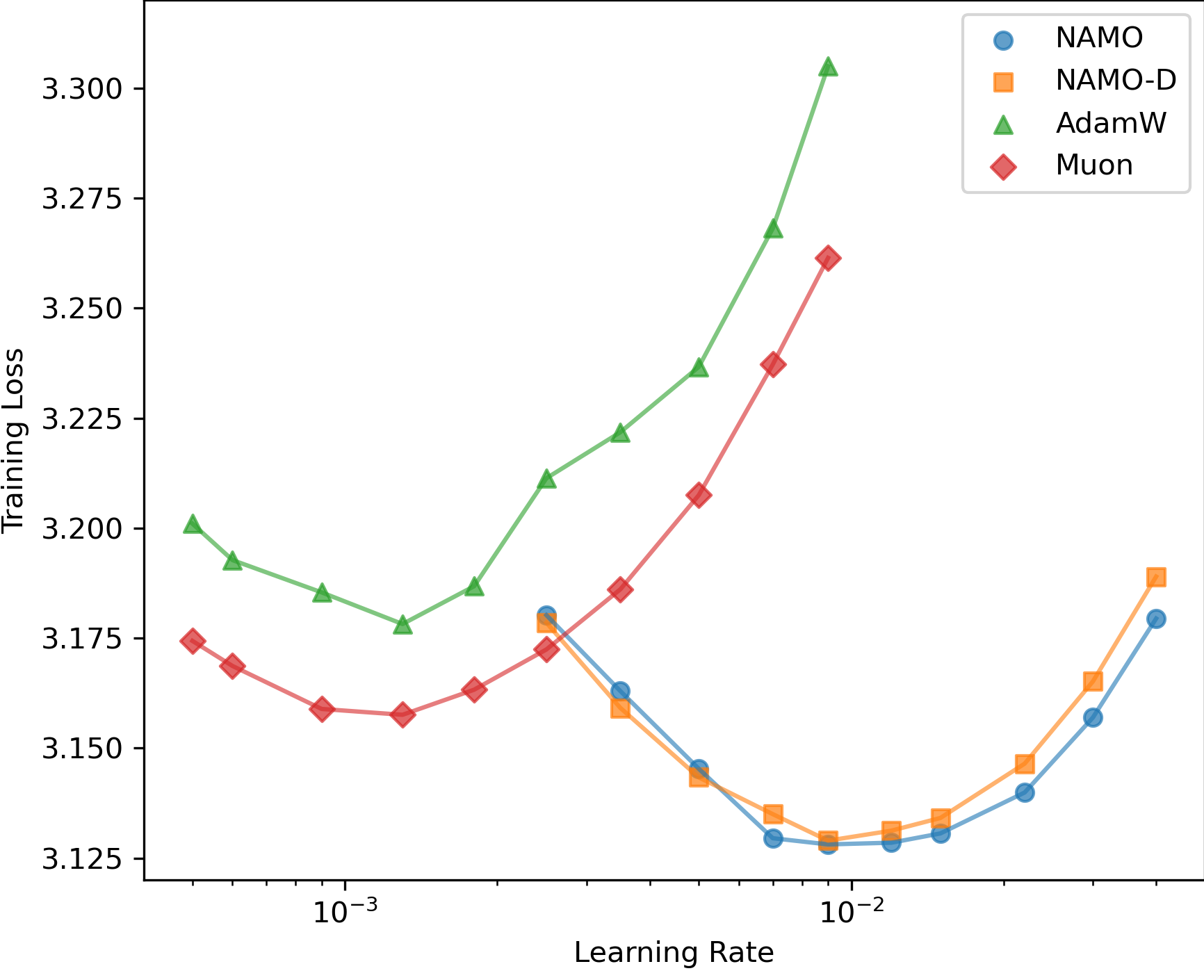
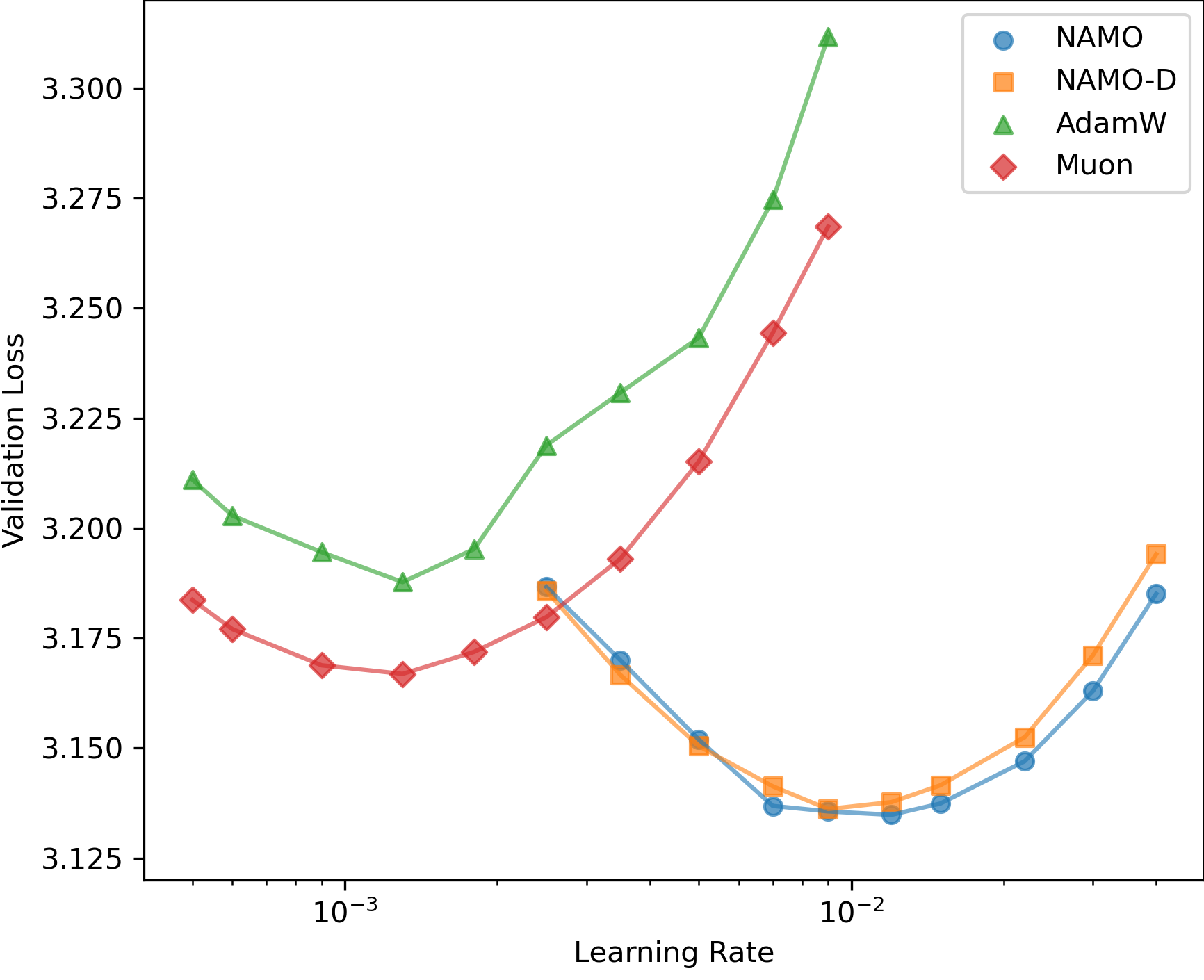
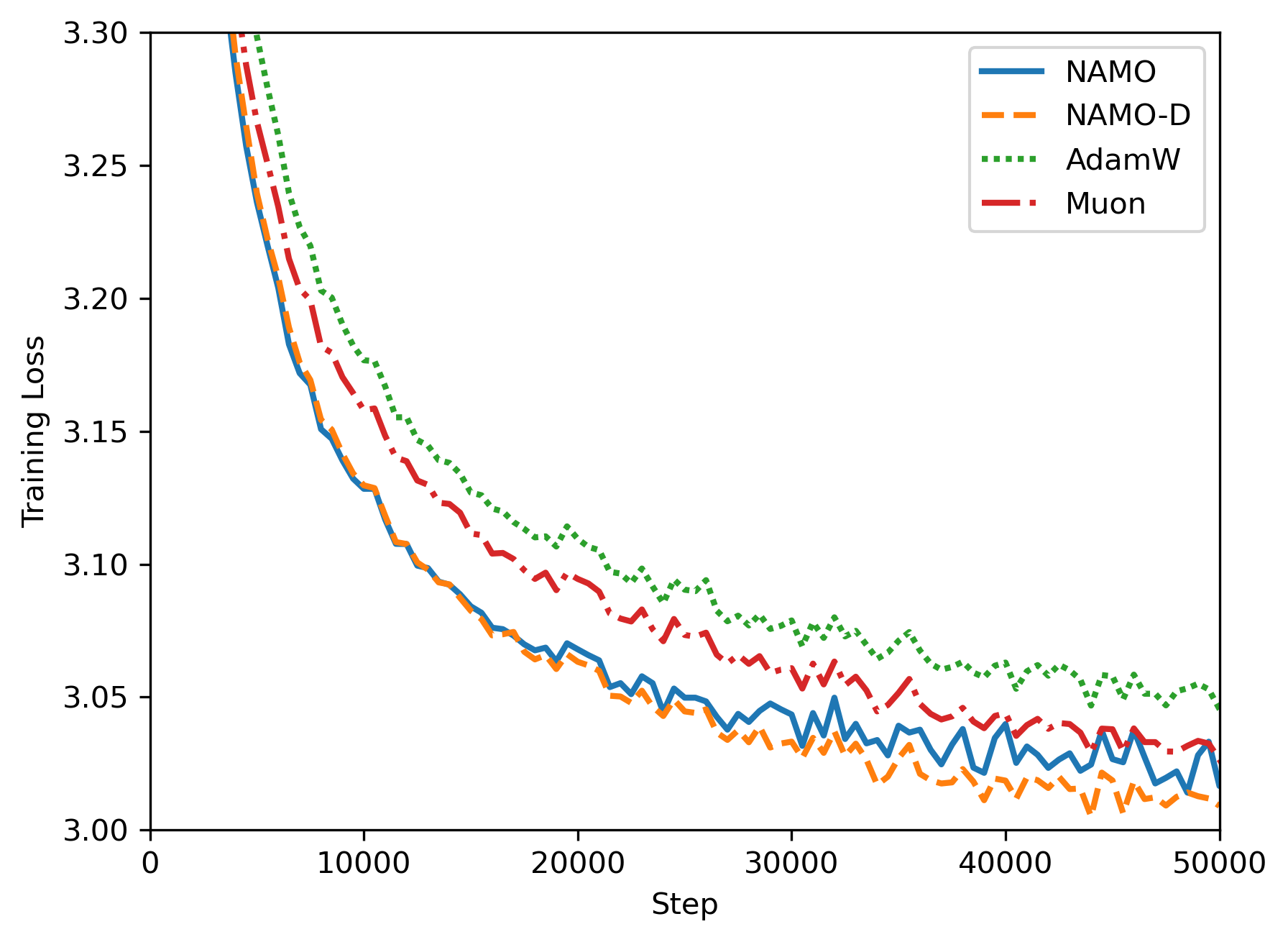
- 实验表明,在GPT-2预训练任务上,NAMO和NAMO-D均优于AdamW和Muon。NAMO-D通过钳制超参数平衡优化方向和噪声适应,获得进一步提升。
📝 摘要(中文)
高效的随机优化通常结合了在确定性环境中表现良好的更新方向和适应随机扰动的机制。Adam使用自适应矩估计来提高稳定性,而Muon通过正交动量利用权重层的矩阵结构,在大语言模型训练中表现出优越的性能。我们提出了一种新的优化器及其对角扩展,NAMO和NAMO-D,首次将正交动量与基于范数的Adam型噪声自适应相结合。NAMO使用单个自适应步长缩放正交动量,在保持正交性的同时改进了Muon,且额外成本可忽略不计。NAMO-D则将正交动量右乘以一个具有钳制条目的对角矩阵。这种设计实现了神经元级别的噪声自适应,并与常见的近块对角Hessian结构对齐。在标准假设下,我们建立了两种算法在确定性环境中的最优收敛速度,并表明在随机环境中,它们的收敛保证适应随机梯度的噪声水平。在预训练GPT-2模型的实验表明,与AdamW和Muon基线相比,NAMO和NAMO-D的性能均有所提高,其中NAMO-D通过额外的钳制超参数实现了比NAMO更大的增益,该超参数平衡了保持良好条件更新方向和利用细粒度噪声自适应的竞争目标。
🔬 方法详解
问题定义:论文旨在解决大语言模型训练中,现有优化器无法有效结合正交动量和噪声自适应的问题。Muon优化器利用正交动量加速训练,但在噪声较大的情况下表现不佳。Adam系列优化器虽然稳定,但可能收敛速度较慢,且没有充分利用权重矩阵的结构信息。
核心思路:论文的核心思路是将正交动量与Adam类型的自适应矩估计相结合,从而在保持训练稳定性的同时,利用权重矩阵的结构信息加速收敛。通过自适应地调整正交动量的尺度,可以更好地适应随机梯度带来的噪声,并提高训练效率。
技术框架:论文提出了两种新的优化器:NAMO和NAMO-D。NAMO使用单个自适应步长来缩放正交动量,而NAMO-D则使用一个对角矩阵来对正交动量进行神经元级别的缩放。整体流程如下: 1. 计算梯度。 2. 应用正交动量。 3. 使用Adam类型的自适应矩估计来调整学习率。 4. 更新权重。 NAMO-D在第2步中,使用对角矩阵对正交动量进行缩放。
关键创新:论文的关键创新在于首次将正交动量与基于范数的Adam型噪声自适应相结合。NAMO通过单个自适应步长缩放正交动量,在保持正交性的同时改进了Muon。NAMO-D则通过对角矩阵实现神经元级别的噪声自适应,更精细地控制了每个神经元的更新幅度。
关键设计:NAMO的关键设计在于使用自适应步长来缩放正交动量,该步长基于梯度的二阶矩估计。NAMO-D的关键设计在于使用一个具有钳制条目的对角矩阵来对正交动量进行缩放,钳制操作限制了缩放因子的范围,平衡了保持良好条件更新方向和利用细粒度噪声自适应的竞争目标。此外,论文还推导了两种算法在确定性和随机环境下的收敛性保证。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在GPT-2预训练任务上,NAMO和NAMO-D均优于AdamW和Muon。具体来说,NAMO在性能上略优于Muon,而NAMO-D通过额外的钳制超参数实现了比NAMO更大的增益。这些结果表明,将正交动量与自适应矩估计相结合可以有效地提高大语言模型的训练效果。
🎯 应用场景
该研究成果可应用于各种需要训练大规模神经网络的任务,尤其是在自然语言处理领域,例如预训练大型语言模型、微调模型以适应特定任务等。通过提高训练效率和模型性能,可以降低训练成本,并提升模型的泛化能力和实际应用效果。该方法也有潜力应用于其他领域,如计算机视觉和语音识别。
📄 摘要(原文)
Efficient stochastic optimization typically integrates an update direction that performs well in the deterministic regime with a mechanism adapting to stochastic perturbations. While Adam uses adaptive moment estimates to promote stability, Muon utilizes the weight layers' matrix structure via orthogonalized momentum, showing superior performance in large language model training. We propose a new optimizer and a diagonal extension, NAMO and NAMO-D, providing the first principled integration of orthogonalized momentum with norm-based Adam-type noise adaptation. NAMO scales orthogonalized momentum using a single adaptive stepsize, preserving orthogonality while improving upon Muon at negligible additional cost. NAMO-D instead right-multiplies orthogonalized momentum by a diagonal matrix with clamped entries. This design enables neuron-wise noise adaptation and aligns with the common near block-diagonal Hessian structure. Under standard assumptions, we establish optimal convergence rates for both algorithms in the deterministic setting and show that, in the stochastic setting, their convergence guarantees adapt to the noise level of stochastic gradients. Experiments on pretraining GPT-2 models demonstrate improved performance of both NAMO and NAMO-D compared to the AdamW and Muon baselines, with NAMO-D achieving further gains over NAMO via an additional clamping hyperparameter that balances the competing goals of maintaining a well-conditioned update direction and leveraging fine-grained noise adaptation.