Action-Graph Policies: Learning Action Co-dependencies in Multi-Agent Reinforcement Learning
作者: Nikunj Gupta, James Zachary Hare, Jesse Milzman, Rajgopal Kannan, Viktor Prasanna
分类: cs.LG
发布日期: 2026-02-19
💡 一句话要点
提出行动图策略以解决多智能体强化学习中的协调问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 协调策略 行动依赖性 决策优化 智能体合作
📋 核心要点
- 现有的多智能体强化学习方法往往忽视了智能体之间的行动依赖性,导致协调性不足。
- 本文提出的行动图策略(AGP)通过构建协调上下文,使智能体能够基于全局行动依赖性来调整决策。
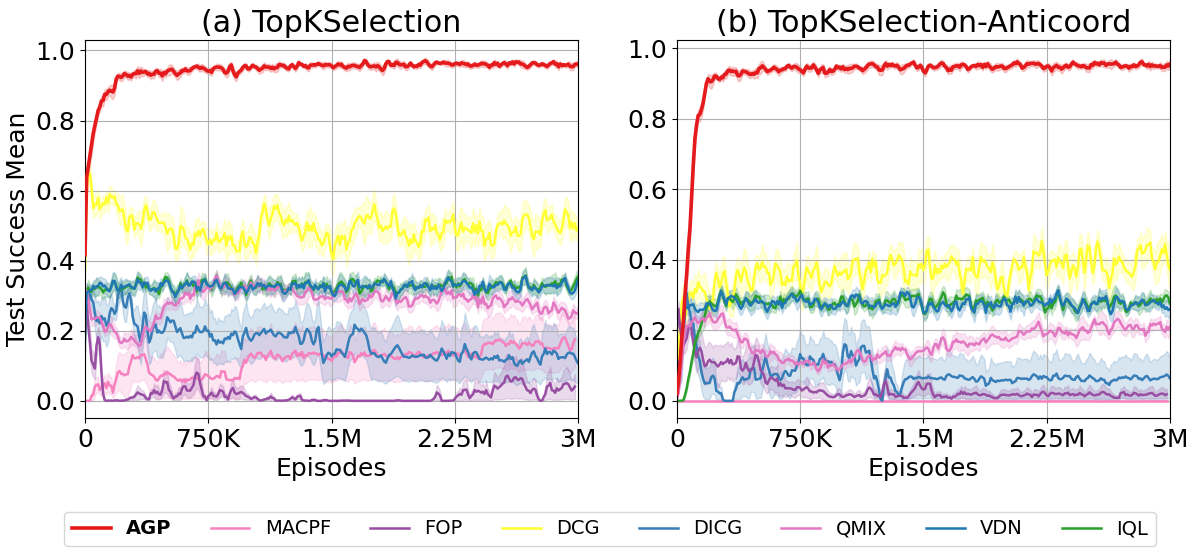
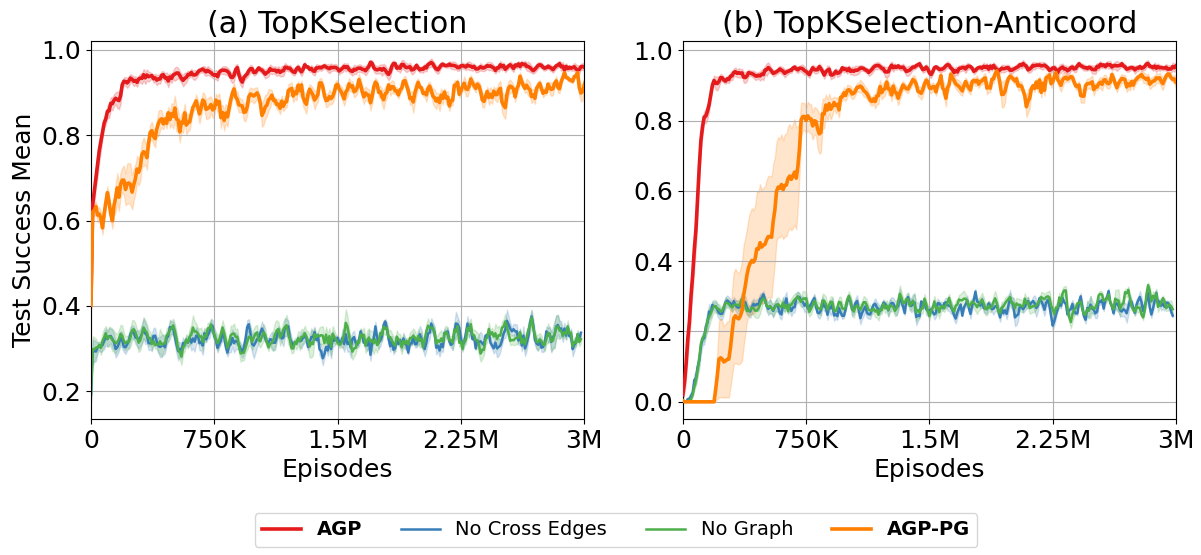
- AGP在经典协调任务中表现优异,成功率达到80-95%,显著高于其他方法的10-25%。
📝 摘要(中文)
协调行动是多智能体强化学习(MARL)中合作的基本形式。成功的去中心化决策不仅依赖于个体的良好行动,还需要选择跨智能体的兼容行动,以同步行为、避免冲突并满足全局约束。本文提出了行动图策略(AGP),该策略建模智能体可用行动选择之间的依赖关系。理论上,我们证明AGP相较于完全独立的策略能够诱导出更具表现力的联合策略,并且能够实现比贪婪执行更优的协调联合行动。实证结果显示,AGP在具有部分可观测性和反协调惩罚的经典协调任务中取得了80-95%的成功率,而其他MARL方法仅达到10-25%。我们进一步展示了AGP在多样化的多智能体环境中始终优于这些基线方法。
🔬 方法详解
问题定义:本文旨在解决多智能体强化学习中智能体之间行动选择的协调问题。现有方法往往缺乏对智能体行动依赖性的建模,导致决策效率低下和协调性不足。
核心思路:论文提出的行动图策略(AGP)通过构建所谓的“协调上下文”,使得智能体能够在决策时考虑其他智能体的行动选择,从而实现更高效的协调。
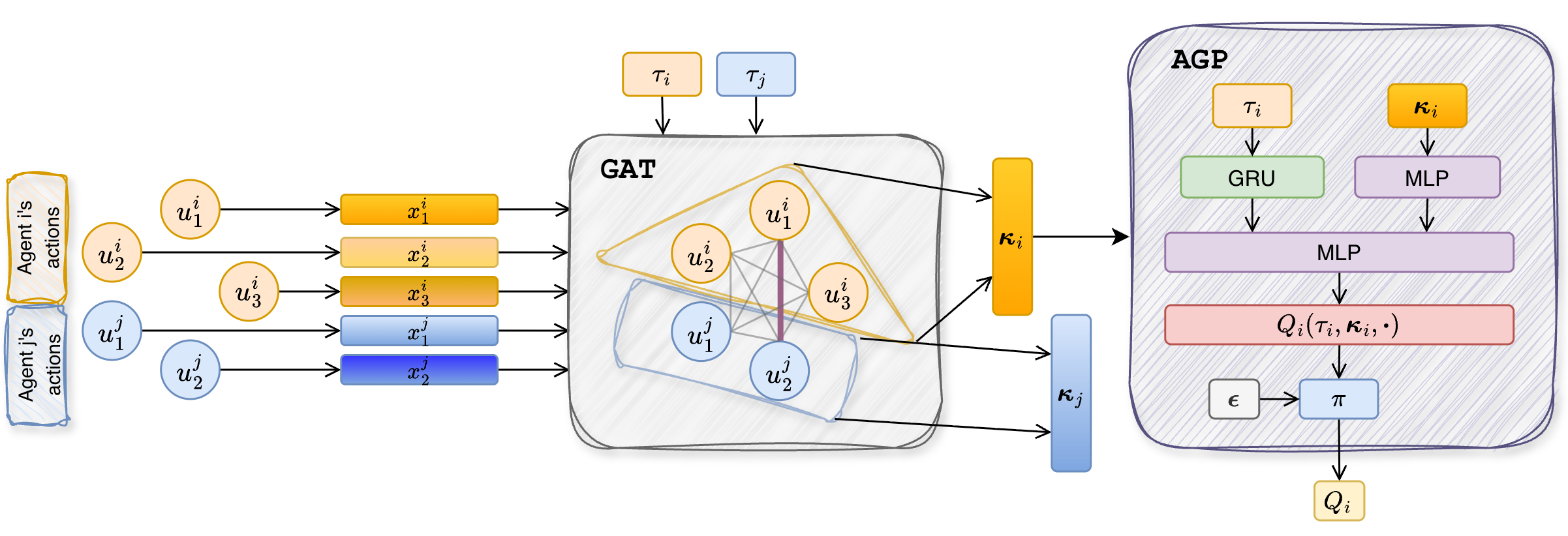
技术框架:AGP的整体架构包括三个主要模块:1)依赖关系建模模块,识别智能体之间的行动依赖;2)协调上下文构建模块,生成基于依赖关系的上下文信息;3)决策模块,利用协调上下文进行智能体的决策。
关键创新:AGP的主要创新在于其能够通过建模智能体之间的行动依赖性,诱导出更具表现力的联合策略。这一方法与传统的完全独立策略相比,能够实现更优的协调行动。
关键设计:在AGP中,关键的参数设置包括协调上下文的构建方式和智能体之间依赖关系的表示。此外,损失函数设计上,AGP引入了全局约束以优化联合行动的选择。
🖼️ 关键图片
📊 实验亮点
实验结果显示,AGP在经典协调任务中取得了80-95%的成功率,而其他多智能体强化学习方法的成功率仅为10-25%。这一显著提升表明AGP在处理部分可观测性和反协调惩罚的任务中具有明显优势。
🎯 应用场景
该研究的潜在应用领域包括多智能体系统中的协作任务,如无人机编队、智能交通系统和机器人团队合作等。通过提升智能体之间的协调能力,AGP能够在复杂环境中实现更高效的合作,具有重要的实际价值和未来影响。
📄 摘要(原文)
Coordinating actions is the most fundamental form of cooperation in multi-agent reinforcement learning (MARL). Successful decentralized decision-making often depends not only on good individual actions, but on selecting compatible actions across agents to synchronize behavior, avoid conflicts, and satisfy global constraints. In this paper, we propose Action Graph Policies (AGP), that model dependencies among agents' available action choices. It constructs, what we call, \textit{coordination contexts}, that enable agents to condition their decisions on global action dependencies. Theoretically, we show that AGPs induce a strictly more expressive joint policy compared to fully independent policies and can realize coordinated joint actions that are provably more optimal than greedy execution even from centralized value-decomposition methods. Empirically, we show that AGP achieves 80-95\% success on canonical coordination tasks with partial observability and anti-coordination penalties, where other MARL methods reach only 10-25\%. We further demonstrate that AGP consistently outperforms these baselines in diverse multi-agent environments.