A Systematic Evaluation of Sample-Level Tokenization Strategies for MEG Foundation Models
作者: SungJun Cho, Chetan Gohil, Rukuang Huang, Oiwi Parker Jones, Mark W. Woolrich
分类: cs.LG, cs.AI, q-bio.NC
发布日期: 2026-02-18
备注: 15 pages, 10 figures, 1 table
🔗 代码/项目: GITHUB
💡 一句话要点
系统评估MEG脑电数据样本级Tokenization策略对神经科学大模型的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脑磁图(MEG) Tokenization 神经影像模型 Transformer 自编码器
📋 核心要点
- 神经影像数据基础模型依赖Tokenization,但不同Tokenization策略对模型性能的影响尚不明确。
- 论文系统评估了可学习和非可学习的样本级Tokenization策略,并提出了一种基于自编码器的可学习Tokenizer。
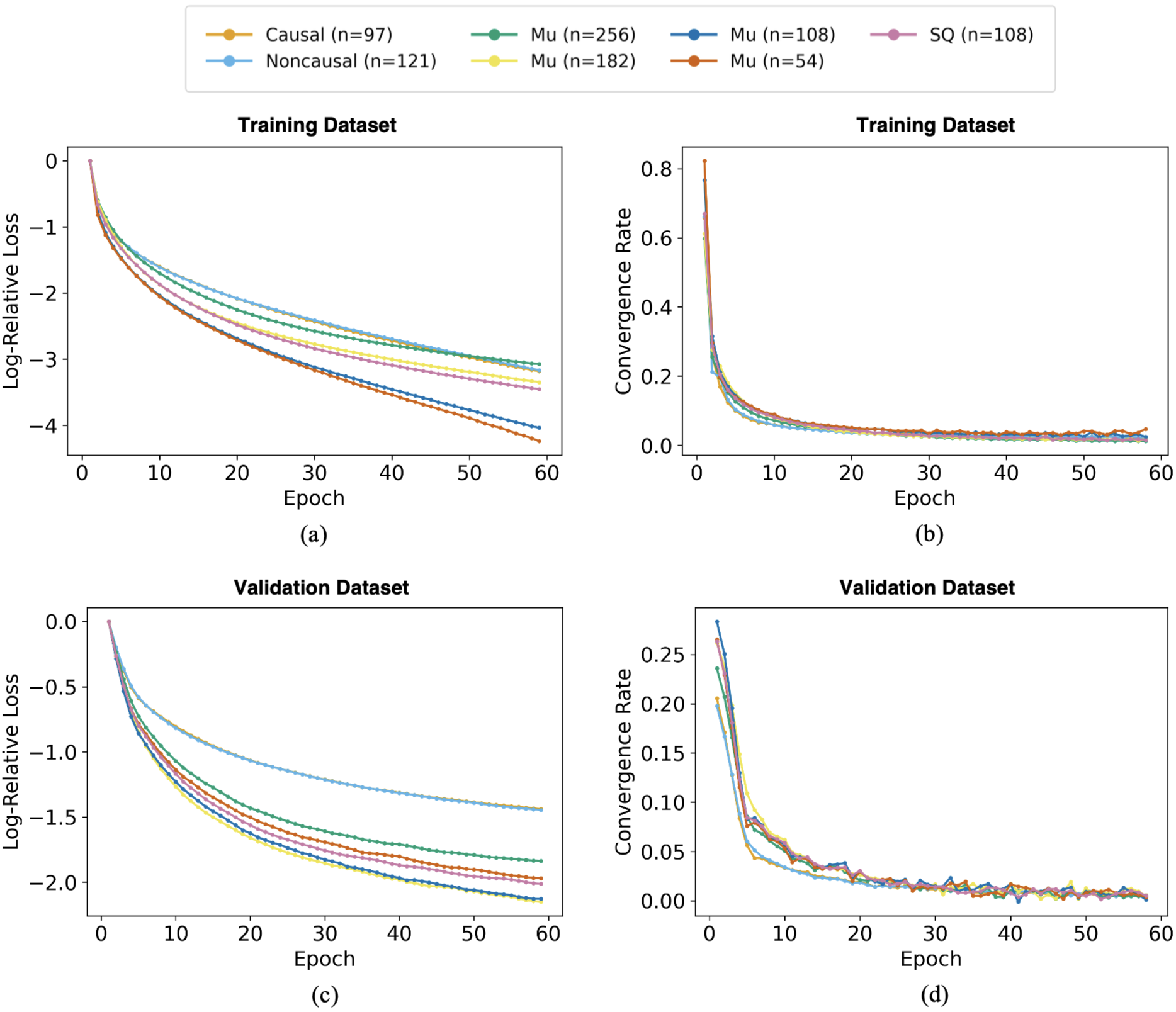
- 实验表明,简单固定的Tokenization策略在MEG数据上能实现高重建精度和可比性能,适用于神经基础模型。
📝 摘要(中文)
自然语言处理的成功激发了人们对神经影像数据大规模基础模型的兴趣。这类模型通常需要对连续神经时间序列数据进行离散化,即“Tokenization”。然而,目前人们对不同Tokenization策略对神经数据的影响知之甚少。本文针对基于Transformer的大型神经影像模型(LNMs)在脑磁图(MEG)数据上的应用,系统地评估了样本级Tokenization策略。我们比较了可学习和非可学习的Tokenizer,考察了它们的信号重建保真度以及它们对后续基础模型性能的影响(Token预测、生成数据的生物合理性、个体特定信息的保留以及下游任务的性能)。对于可学习的Tokenizer,我们引入了一种基于自编码器的新方法。实验在三个公开的MEG数据集上进行,这些数据集涵盖了不同的采集地点、扫描仪和实验范式。结果表明,可学习和非可学习的离散化方案都实现了较高的重建精度,并且在大多数评估标准上都具有广泛的可比性能,这表明简单的固定样本级Tokenization策略可用于神经基础模型的开发。
🔬 方法详解
问题定义:论文旨在解决神经影像数据(特别是MEG数据)在应用于大型神经影像模型(LNMs)时,如何选择合适的Tokenization策略的问题。现有方法缺乏对不同Tokenization策略的系统性评估,导致无法确定哪种策略最适合神经数据,从而影响了基础模型的性能。
核心思路:论文的核心思路是通过对比可学习和非可学习的Tokenization策略,并从信号重建保真度、Token预测、生物合理性、个体信息保留和下游任务性能等多个维度进行评估,从而确定适用于神经影像数据基础模型的Tokenization方法。论文认为,通过系统性的实验评估,可以找到既能保证数据质量又能有效支持模型训练的Tokenization策略。
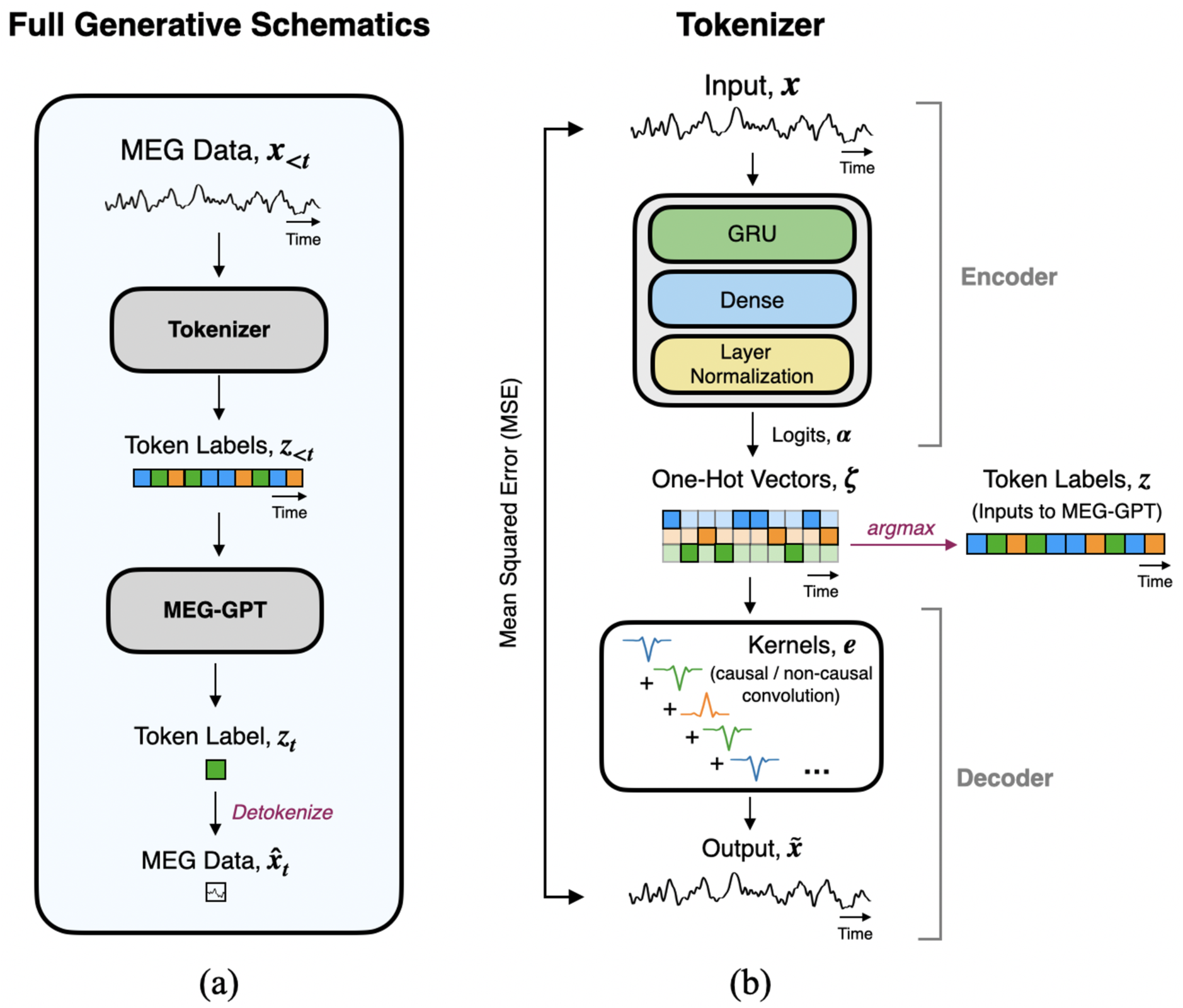
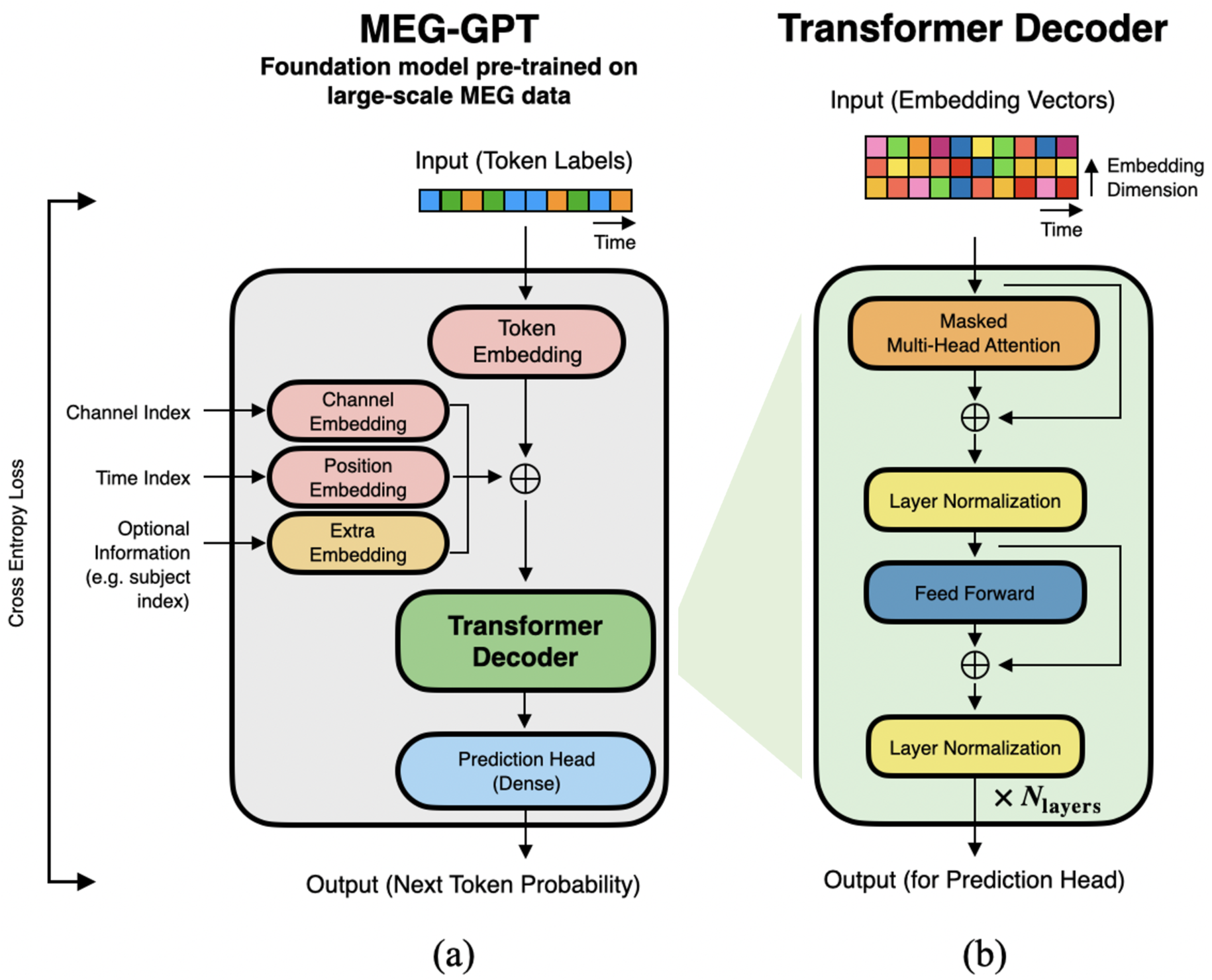
技术框架:论文的整体框架包括以下几个主要步骤:1) 选择或设计Tokenization方法(包括可学习和非可学习的);2) 使用Tokenization方法将MEG数据转换为Token序列;3) 使用Token序列训练或评估大型神经影像模型(LNMs);4) 从多个维度(如信号重建保真度、Token预测准确率、生成数据的生物合理性等)评估模型性能;5) 对比不同Tokenization方法在各个评估指标上的表现,从而得出结论。对于可学习的Tokenizer,论文提出了一种基于自编码器的方法。
关键创新:论文的关键创新在于:1) 对比了多种Tokenization策略在神经影像数据上的表现,填补了该领域的空白;2) 提出了一种基于自编码器的可学习Tokenizer,为神经影像数据的Tokenization提供了一种新的选择;3) 从多个维度对Tokenization策略进行了系统性的评估,为选择合适的Tokenization方法提供了全面的参考。
关键设计:论文的关键设计包括:1) 选择了具有代表性的可学习和非可学习Tokenization方法;2) 使用了多个公开的MEG数据集,保证了实验结果的泛化性;3) 从多个维度评估了模型性能,保证了评估的全面性;4) 对于基于自编码器的可学习Tokenizer,设计了合适的网络结构和损失函数,以保证其能够有效地学习到神经数据的特征。
🖼️ 关键图片
📊 实验亮点
实验结果表明,无论是可学习还是非可学习的Tokenization策略,都能实现较高的信号重建精度,并且在大多数评估指标上表现相当。这表明,对于MEG数据,简单的固定样本级Tokenization策略可能足以支持神经基础模型的开发,无需过度追求复杂的学习型Tokenization方法。具体性能数据未知,论文侧重于策略对比而非绝对性能。
🎯 应用场景
该研究成果可应用于脑疾病诊断、脑机接口、认知神经科学等领域。通过选择合适的Tokenization策略,可以提高神经影像数据基础模型的性能,从而更准确地解码大脑活动,为相关应用提供更可靠的技术支持。未来,该研究可以扩展到其他类型的神经影像数据,如脑电图(EEG)和功能磁共振成像(fMRI)。
📄 摘要(原文)
Recent success in natural language processing has motivated growing interest in large-scale foundation models for neuroimaging data. Such models often require discretization of continuous neural time series data, a process referred to as 'tokenization'. However, the impact of different tokenization strategies for neural data is currently poorly understood. In this work, we present a systematic evaluation of sample-level tokenization strategies for transformer-based large neuroimaging models (LNMs) applied to magnetoencephalography (MEG) data. We compare learnable and non-learnable tokenizers by examining their signal reconstruction fidelity and their impact on subsequent foundation modeling performance (token prediction, biological plausibility of generated data, preservation of subject-specific information, and performance on downstream tasks). For the learnable tokenizer, we introduce a novel approach based on an autoencoder. Experiments were conducted on three publicly available MEG datasets spanning different acquisition sites, scanners, and experimental paradigms. Our results show that both learnable and non-learnable discretization schemes achieve high reconstruction accuracy and broadly comparable performance across most evaluation criteria, suggesting that simple fixed sample-level tokenization strategies can be used in the development of neural foundation models. The code is available at https://github.com/OHBA-analysis/Cho2026_Tokenizer.