A Scalable Approach to Solving Simulation-Based Network Security Games
作者: Michael Lanier, Yevgeniy Vorobeychik
分类: cs.LG, cs.CR
发布日期: 2026-02-18
💡 一句话要点
提出MetaDOAR,通过可扩展的分层策略学习解决大规模网络安全博弈问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 网络安全博弈 多智能体强化学习 分层策略学习 元控制器 Q值缓存
📋 核心要点
- 现有方法难以扩展到大型网络安全博弈,面临计算量大、内存占用高等挑战。
- MetaDOAR采用分层策略学习,通过元控制器选择关键节点,降低搜索空间,提高效率。
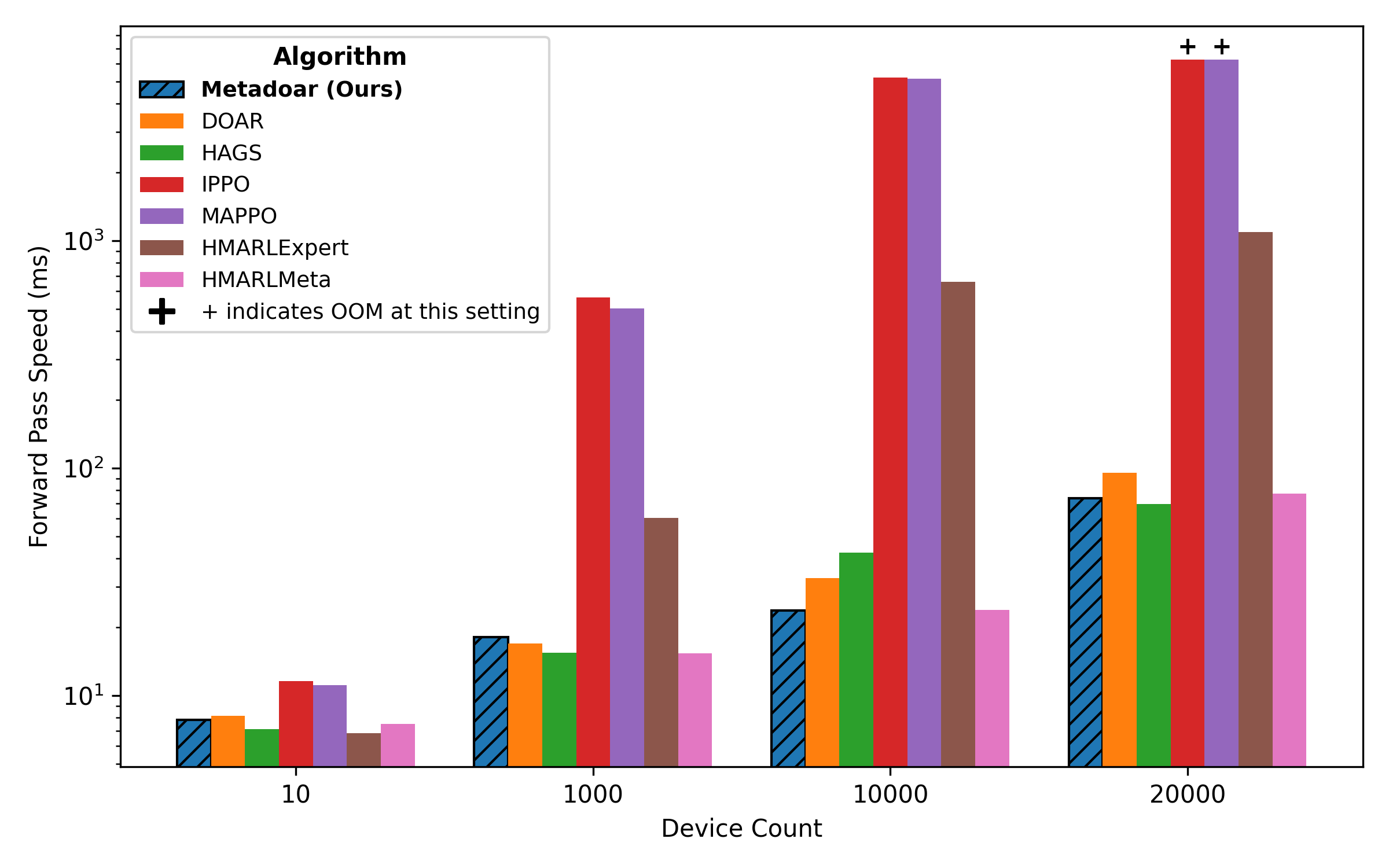
- 实验表明,MetaDOAR在大型网络拓扑上优于现有方法,且内存和训练时间开销可控。
📝 摘要(中文)
本文提出MetaDOAR,一种轻量级的元控制器,它通过学习到的、感知分区的过滤层和Q值缓存来增强Double Oracle / PSRO范式,从而实现对超大型网络环境中可扩展的多智能体强化学习。MetaDOAR从每个节点的结构嵌入中学习一个紧凑的状态投影,以快速评分并选择一小部分设备(top-k分区),一个传统的低级actor在此基础上执行聚焦波束搜索,并利用critic智能体。所选的候选动作通过批处理的critic前向传播进行评估,并存储在LRU缓存中,该缓存由量化的状态投影和本地动作标识符进行键控,从而显著减少冗余的critic计算,同时通过保守的k跳缓存失效来保持决策质量。实验表明,MetaDOAR在大型网络拓扑上获得了比SOTA基线更高的玩家收益,并且在内存使用或训练时间方面没有明显的扩展问题。这项贡献为大规模网络决策问题提供了一条实用且具有理论动机的有效分层策略学习路径。
🔬 方法详解
问题定义:论文旨在解决大规模网络安全博弈中的多智能体强化学习问题。现有方法,如直接应用Double Oracle或PSRO等算法,在面对大型网络时,由于状态空间和动作空间的爆炸式增长,导致计算复杂度过高,难以扩展。此外,频繁的策略评估也带来了巨大的计算负担。
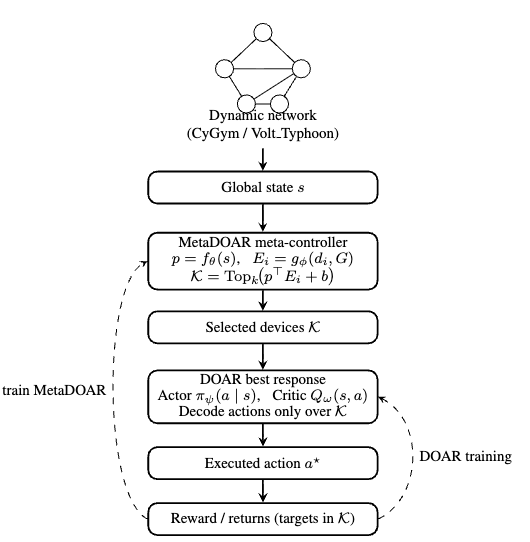
核心思路:MetaDOAR的核心思路是采用分层策略学习,将问题分解为两个层次:元控制器(Meta-Controller)和低级Actor。元控制器负责从全局状态中选择一小部分关键节点(top-k分区),从而显著缩小低级Actor的搜索空间。这种分层结构降低了计算复杂度,提高了学习效率。
技术框架:MetaDOAR的整体框架包含以下几个主要模块:1) 节点结构嵌入:利用图神经网络等技术,将每个节点的状态信息编码为低维向量表示。2) 元控制器:学习一个策略,根据节点嵌入选择top-k个关键节点。3) 低级Actor:在选定的关键节点上执行聚焦波束搜索,生成候选动作。4) Critic智能体:评估候选动作的价值。5) Q值缓存:使用LRU缓存存储已评估的Q值,避免重复计算。
关键创新:MetaDOAR的关键创新在于引入了元控制器和Q值缓存机制。元控制器通过学习到的状态投影,能够快速选择关键节点,从而降低搜索空间。Q值缓存则通过存储已评估的Q值,避免了重复计算,进一步提高了效率。此外,保守的k跳缓存失效机制保证了决策质量。
关键设计:MetaDOAR的关键设计包括:1) 节点结构嵌入的具体方法(例如,使用GraphSAGE或GCN)。2) 元控制器的网络结构和损失函数,用于学习选择关键节点的策略。3) 低级Actor的波束搜索算法的具体实现。4) Critic智能体的网络结构和训练方法。5) Q值缓存的大小和替换策略,以及k跳缓存失效的具体实现。
🖼️ 关键图片
📊 实验亮点
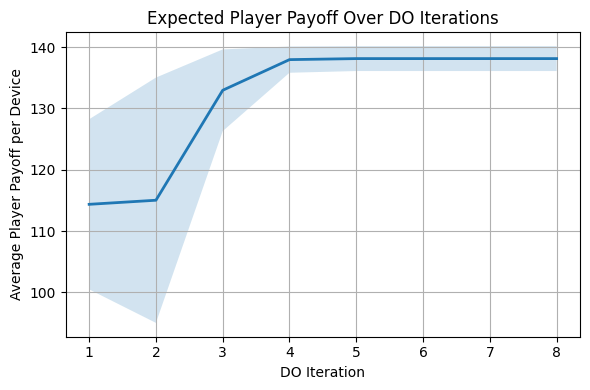
MetaDOAR在大型网络拓扑上取得了显著的性能提升,优于SOTA基线方法。具体而言,MetaDOAR在玩家收益方面获得了更高的回报,并且在内存使用和训练时间方面没有明显的扩展问题。这表明MetaDOAR具有良好的可扩展性和实用性,能够有效解决大规模网络安全博弈问题。
🎯 应用场景
MetaDOAR可应用于各种大规模网络安全博弈场景,例如:网络入侵检测与防御、恶意软件传播控制、僵尸网络对抗等。该方法能够有效提高防御策略的效率和效果,降低网络安全风险,具有重要的实际应用价值和潜力。未来,该方法还可以扩展到其他类型的网络决策问题,例如:交通网络优化、社交网络影响力最大化等。
📄 摘要(原文)
We introduce MetaDOAR, a lightweight meta-controller that augments the Double Oracle / PSRO paradigm with a learned, partition-aware filtering layer and Q-value caching to enable scalable multi-agent reinforcement learning on very large cyber-network environments. MetaDOAR learns a compact state projection from per node structural embeddings to rapidly score and select a small subset of devices (a top-k partition) on which a conventional low-level actor performs focused beam search utilizing a critic agent. Selected candidate actions are evaluated with batched critic forwards and stored in an LRU cache keyed by a quantized state projection and local action identifiers, dramatically reducing redundant critic computation while preserving decision quality via conservative k-hop cache invalidation. Empirically, MetaDOAR attains higher player payoffs than SOTA baselines on large network topologies, without significant scaling issues in terms of memory usage or training time. This contribution provide a practical, theoretically motivated path to efficient hierarchical policy learning for large-scale networked decision problems.