Vulnerability Analysis of Safe Reinforcement Learning via Inverse Constrained Reinforcement Learning
作者: Jialiang Fan, Shixiong Jiang, Mengyu Liu, Fanxin Kong
分类: cs.LG
发布日期: 2026-02-18
备注: 12 pages, 6 figures, supplementary material included
💡 一句话要点
提出基于逆约束强化学习的安全强化学习策略脆弱性分析框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 安全强化学习 对抗攻击 逆约束强化学习 黑盒攻击 策略脆弱性
📋 核心要点
- 现有安全强化学习方法在对抗扰动下表现脆弱,无法保证真实场景中的安全性。
- 该论文提出一种基于逆约束强化学习的对抗攻击框架,无需访问目标策略梯度即可进行攻击。
- 实验表明,该方法在多个安全强化学习基准测试中有效,验证了其在有限访问权限下的攻击能力。
📝 摘要(中文)
安全强化学习(Safe RL)旨在确保策略性能的同时满足安全约束。然而,现有多数Safe RL方法假设环境是良性的,使其容易受到真实环境中常见的对抗扰动的影响。此外,现有的基于梯度的对抗攻击通常需要访问策略的梯度信息,这在实际场景中往往是不切实际的。为了解决这些挑战,我们提出了一个对抗攻击框架,以揭示Safe RL策略的脆弱性。通过使用专家演示和黑盒环境交互,我们的框架学习一个约束模型和一个代理(学习者)策略,从而能够在不需要受害者策略的内部梯度或真实安全约束的情况下进行基于梯度的攻击优化。我们进一步提供了理论分析,建立了可行性并推导了扰动界限。在多个Safe RL基准上的实验证明了我们的方法在有限特权访问下的有效性。
🔬 方法详解
问题定义:论文旨在解决安全强化学习策略在对抗环境下的脆弱性问题。现有方法通常假设环境是良性的,忽略了真实世界中常见的对抗扰动。此外,许多攻击方法需要访问目标策略的梯度信息,这在黑盒场景下是不可行的。因此,如何在有限的访问权限下评估和攻击安全强化学习策略是一个关键问题。
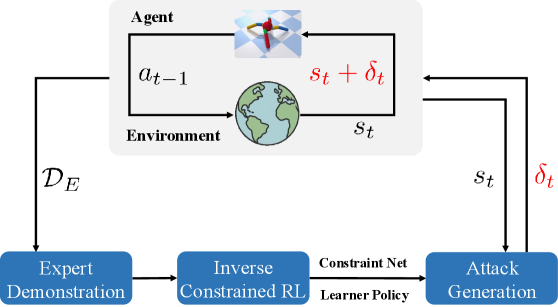
核心思路:论文的核心思路是利用逆约束强化学习(Inverse Constrained Reinforcement Learning, ICRL)的思想,通过专家演示和环境交互学习一个约束模型和一个代理策略。该代理策略模仿目标策略的行为,并学习其隐含的安全约束。然后,利用代理策略的梯度信息进行对抗攻击,从而绕过对目标策略梯度的直接访问需求。
技术框架:该框架主要包含以下几个模块:1) 数据收集:通过与环境交互和专家演示收集数据。2) 约束模型学习:利用收集到的数据,通过ICRL学习一个约束模型,该模型用于预测状态的安全程度。3) 代理策略学习:使用强化学习算法训练一个代理策略,使其模仿目标策略的行为,并满足学习到的约束。4) 对抗攻击优化:基于代理策略的梯度信息,生成对抗扰动,以最大化目标策略的违反约束程度。
关键创新:该论文的关键创新在于提出了一种基于逆约束强化学习的黑盒对抗攻击方法。与传统的白盒攻击方法相比,该方法不需要访问目标策略的梯度信息,更符合实际应用场景。此外,通过学习约束模型,可以有效地估计状态的安全程度,从而指导对抗扰动的生成。
关键设计:在约束模型学习方面,可以使用各种分类或回归模型来预测状态的安全程度。在代理策略学习方面,可以使用各种强化学习算法,如TRPO、PPO等。对抗攻击优化可以使用基于梯度的优化算法,如PGD等。关键参数包括约束模型的容量、代理策略的学习率、对抗扰动的幅度等。损失函数通常包括策略模仿损失和约束违反损失。
🖼️ 关键图片
📊 实验亮点
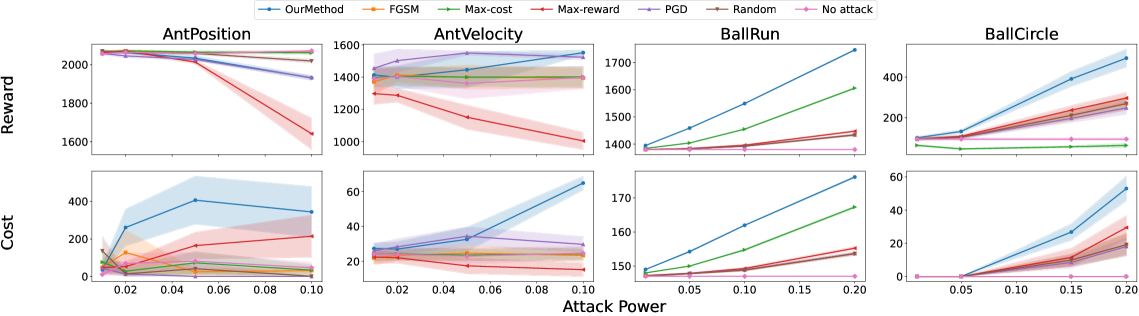
实验结果表明,该方法在多个Safe RL基准测试中能够有效地攻击目标策略,使其违反安全约束。与不进行对抗攻击的基线相比,该方法显著增加了策略违反约束的频率,验证了其在有限访问权限下的攻击能力。
🎯 应用场景
该研究成果可应用于评估和提高安全强化学习系统在自动驾驶、机器人控制等领域的鲁棒性。通过对抗攻击,可以发现安全策略的潜在漏洞,并针对性地进行改进,从而提升系统在复杂和不确定环境中的安全性。
📄 摘要(原文)
Safe reinforcement learning (Safe RL) aims to ensure policy performance while satisfying safety constraints. However, most existing Safe RL methods assume benign environments, making them vulnerable to adversarial perturbations commonly encountered in real-world settings. In addition, existing gradient-based adversarial attacks typically require access to the policy's gradient information, which is often impractical in real-world scenarios. To address these challenges, we propose an adversarial attack framework to reveal vulnerabilities of Safe RL policies. Using expert demonstrations and black-box environment interaction, our framework learns a constraint model and a surrogate (learner) policy, enabling gradient-based attack optimization without requiring the victim policy's internal gradients or the ground-truth safety constraints. We further provide theoretical analysis establishing feasibility and deriving perturbation bounds. Experiments on multiple Safe RL benchmarks demonstrate the effectiveness of our approach under limited privileged access.