Reinforcement Learning for Parameterized Quantum State Preparation: A Comparative Study
作者: Gerhard Stenzel, Isabella Debelic, Michael Kölle, Tobias Rohe, Leo Sünkel, Julian Hager, Claudia Linnhoff-Popien
分类: cs.LG, quant-ph
发布日期: 2026-02-18
备注: Extended version of a short paper to be published at ICAART 2026
💡 一句话要点
提出基于强化学习的参数化量子态制备方法以提升量子电路合成效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 量子计算 强化学习 量子电路合成 参数化量子态 PPO A2C 量子信息处理
📋 核心要点
- 现有的量子电路合成方法在处理参数化量子态制备时面临挑战,特别是在选择门类型和旋转角度的效率上。
- 论文提出了一种基于强化学习的单阶段和两阶段训练方法,以优化量子电路的合成过程,提升制备效率。
- 实验结果表明,单阶段PPO策略在成功率上表现优异,尤其在重构计算基态和贝尔态方面,且运行时间更具优势。
📝 摘要(中文)
本研究扩展了定向量子电路合成(DQCS),将强化学习应用于参数化量子态制备,涵盖连续的单量子比特旋转。我们比较了两种训练模式:一种是单阶段代理,联合选择门类型、受影响的量子比特及旋转角度;另一种是两阶段变体,首先提出离散电路,然后使用参数偏移梯度优化旋转角度。通过Gymnasium和PennyLane评估了PPO和A2C在不同量子比特系统上的表现。结果显示,PPO在稳定的超参数下成功重构计算基态和贝尔态,而A2C未能学习有效策略。尽管两阶段方法在准确性上略有提升,但运行时间约为单阶段的三倍,因此推荐在固定计算预算下使用单阶段PPO策略。
🔬 方法详解
问题定义:本研究旨在解决现有量子电路合成方法在参数化量子态制备中的效率问题,尤其是在门选择和旋转角度优化方面的不足。
核心思路:通过引入强化学习,特别是PPO和A2C算法,论文设计了两种训练模式,以优化量子电路的合成过程,提升制备的准确性和效率。
技术框架:整体架构包括两个主要阶段:第一阶段为门选择和量子比特选择,第二阶段为旋转角度的优化。使用Gymnasium和PennyLane作为实验平台,评估不同算法的表现。
关键创新:最重要的创新在于将强化学习应用于量子态制备的参数优化,尤其是通过单阶段和两阶段方法的比较,明确了在特定条件下的最佳策略选择。
关键设计:在单阶段PPO中,学习率设置为约5×10^-4,目标自保真度误差阈值为0.01;而在两阶段方法中,学习率为约10^-4。实验中成功率在83%到99%之间,贝尔态的成功率在61%到77%之间。
🖼️ 关键图片
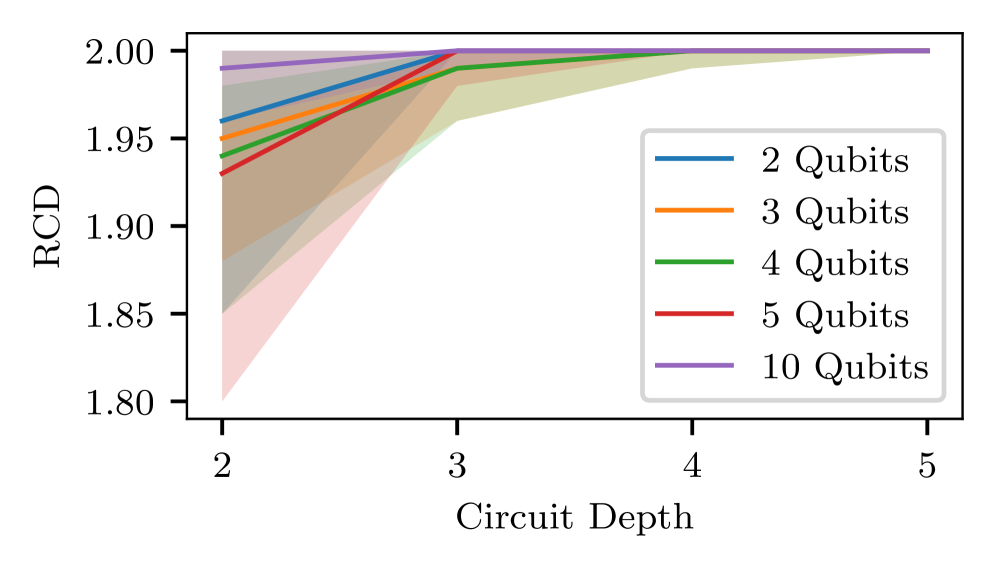
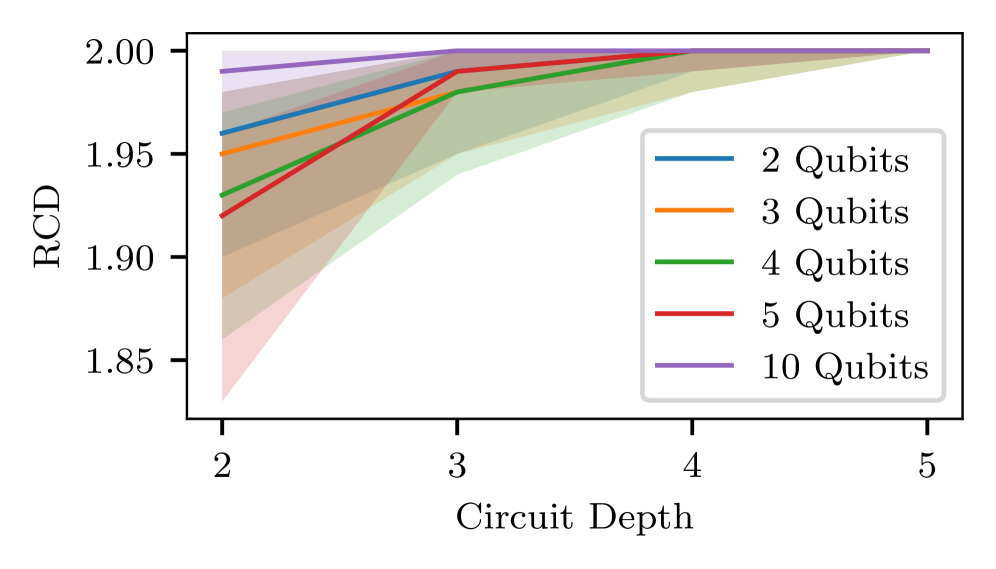
📊 实验亮点
实验结果显示,单阶段PPO策略在重构计算基态的成功率高达99%,而贝尔态的成功率为77%。相比之下,A2C未能有效学习策略。尽管两阶段方法在准确性上略有提升,但其运行时间约为单阶段的三倍,强调了单阶段方法的实用性。
🎯 应用场景
该研究的潜在应用领域包括量子计算、量子通信和量子信息处理等。通过优化量子态制备过程,可以提高量子计算的效率和准确性,推动量子技术的实际应用和发展。未来,随着量子计算机的普及,该方法可能在量子算法设计和量子电路优化中发挥重要作用。
📄 摘要(原文)
We extend directed quantum circuit synthesis (DQCS) with reinforcement learning from purely discrete gate selection to parameterized quantum state preparation with continuous single-qubit rotations (R_x), (R_y), and (R_z). We compare two training regimes: a one-stage agent that jointly selects the gate type, the affected qubit(s), and the rotation angle; and a two-stage variant that first proposes a discrete circuit and subsequently optimizes the rotation angles with Adam using parameter-shift gradients. Using Gymnasium and PennyLane, we evaluate Proximal Policy Optimization (PPO) and Advantage Actor--Critic (A2C) on systems comprising two to ten qubits and on targets of increasing complexity with (λ) ranging from one to five. Whereas A2C does not learn effective policies in this setting, PPO succeeds under stable hyperparameters (one-stage: learning rate approximately (5\times10^{-4}) with a self-fidelity-error threshold of 0.01; two-stage: learning rate approximately (10^{-4})). Both approaches reliably reconstruct computational basis states (between 83\% and 99\% success) and Bell states (between 61\% and 77\% success). However, scalability saturates for (λ) of approximately three to four and does not extend to ten-qubit targets even at (λ=2). The two-stage method offers only marginal accuracy gains while requiring around three times the runtime. For practicality under a fixed compute budget, we therefore recommend the one-stage PPO policy, provide explicit synthesized circuits, and contrast with a classical variational baseline to outline avenues for improved scalability.