Graphon Mean-Field Subsampling for Cooperative Heterogeneous Multi-Agent Reinforcement Learning
作者: Emile Anand, Richard Hoffmann, Sarah Liaw, Adam Wierman
分类: cs.LG, cs.AI, cs.MA
发布日期: 2026-02-18
备注: 43 pages, 5 figures, 1 table
💡 一句话要点
提出GMFS框架以解决异质多智能体强化学习中的协调问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 图均值场 异质性 机器人协调 样本复杂度 策略学习 子采样
📋 核心要点
- 现有的多智能体强化学习方法在处理大量智能体时面临联合状态-动作空间指数级增长的问题,导致计算复杂度高。
- 本文提出的GMFS框架通过根据智能体间的交互强度对子采样,能够有效近似异质智能体的图权重均值场,降低计算负担。
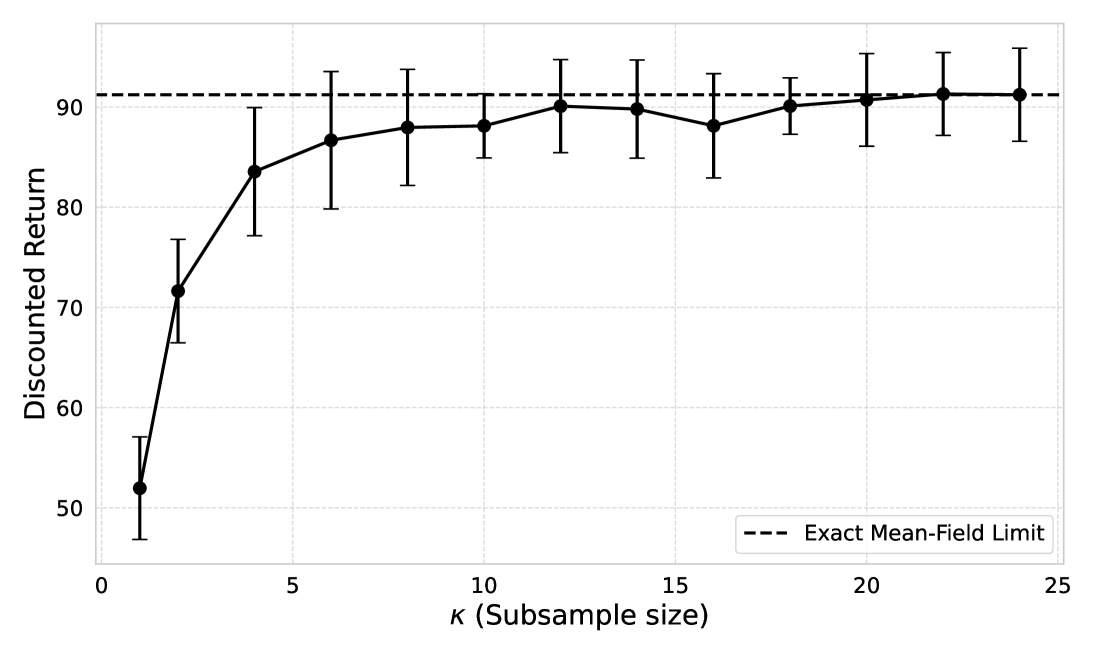
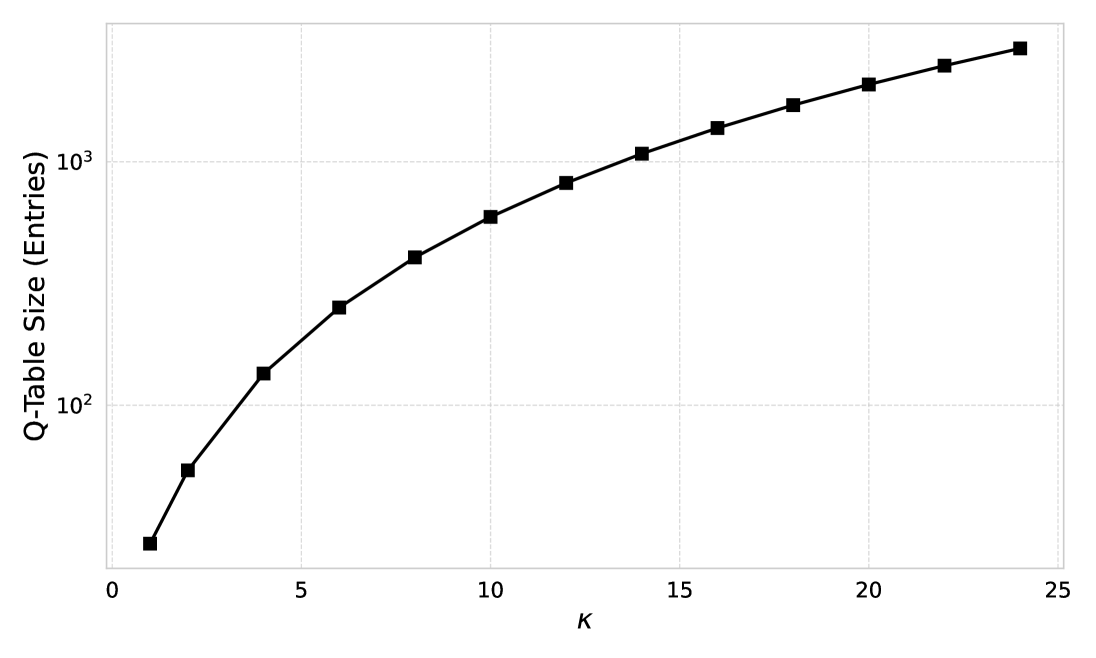
- 实验结果表明,GMFS在机器人协调任务中表现出近乎最优的性能,样本复杂度为多项式级别,最优性差距显著降低。
📝 摘要(中文)
协调大量相互作用的智能体是多智能体强化学习(MARL)中的核心挑战,尤其是当智能体数量增加时,联合状态-动作空间的规模呈指数级增长。均值场方法通过聚合智能体交互来缓解这一负担,但这些方法假设交互是同质的。最近的基于图的框架能够捕捉异质性,但在智能体数量增加时计算成本较高。因此,本文提出了GMFS(图均值场子采样)框架,旨在实现可扩展的合作MARL,处理异质智能体交互。通过根据交互强度对子采样κ个智能体,我们近似图权重均值场,并学习具有样本复杂度为多项式的策略,最优性差距为O(1/√κ)。我们通过机器人协调的数值仿真验证了我们的理论,显示GMFS实现了近乎最优的性能。
🔬 方法详解
问题定义:本文旨在解决多智能体强化学习中,随着智能体数量增加而导致的联合状态-动作空间指数级增长的问题。现有均值场方法假设智能体间的交互是同质的,无法有效处理异质性,且计算成本高昂。
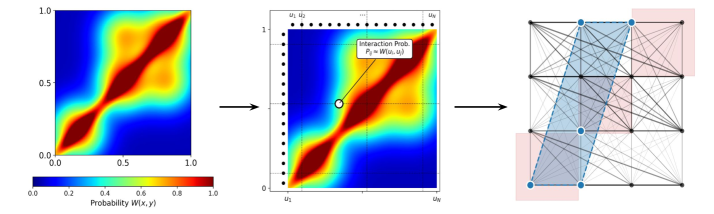
核心思路:GMFS框架的核心思路是通过根据交互强度对子采样智能体,从而近似图权重均值场。这种设计使得在处理异质智能体交互时,能够显著降低计算复杂度,同时保持策略学习的有效性。
技术框架:GMFS的整体架构包括两个主要模块:首先是根据智能体间的交互强度进行子采样,其次是利用子采样的智能体进行策略学习。通过这种方式,框架能够在保持性能的同时,减少所需的计算资源。
关键创新:GMFS的主要创新在于其能够处理异质智能体交互的同时,保持较低的样本复杂度和最优性差距。这与传统均值场方法的同质假设形成鲜明对比,提供了更灵活的解决方案。
关键设计:在设计上,GMFS通过设置交互强度的阈值来选择子样本智能体,并采用多项式复杂度的策略学习算法。损失函数设计上,确保了在学习过程中能够有效捕捉到异质性特征。
🖼️ 关键图片
📊 实验亮点
实验结果显示,GMFS在机器人协调任务中实现了近乎最优的性能,样本复杂度为多项式级别,最优性差距为O(1/√κ),相较于传统方法显著提升了效率和效果。
🎯 应用场景
该研究的潜在应用领域包括机器人协调、智能交通系统和多无人机协作等场景。通过有效处理异质智能体的交互,GMFS框架能够在实际应用中提高系统的协调性和效率,具有重要的实际价值和未来影响。
📄 摘要(原文)
Coordinating large populations of interacting agents is a central challenge in multi-agent reinforcement learning (MARL), where the size of the joint state-action space scales exponentially with the number of agents. Mean-field methods alleviate this burden by aggregating agent interactions, but these approaches assume homogeneous interactions. Recent graphon-based frameworks capture heterogeneity, but are computationally expensive as the number of agents grows. Therefore, we introduce $\texttt{GMFS}$, a $\textbf{G}$raphon $\textbf{M}$ean-$\textbf{F}$ield $\textbf{S}$ubsampling framework for scalable cooperative MARL with heterogeneous agent interactions. By subsampling $κ$ agents according to interaction strength, we approximate the graphon-weighted mean-field and learn a policy with sample complexity $\mathrm{poly}(κ)$ and optimality gap $O(1/\sqrtκ)$. We verify our theory with numerical simulations in robotic coordination, showing that $\texttt{GMFS}$ achieves near-optimal performance.