HiPER: Hierarchical Reinforcement Learning with Explicit Credit Assignment for Large Language Model Agents
作者: Jiangweizhi Peng, Yuanxin Liu, Ruida Zhou, Charles Fleming, Zhaoran Wang, Alfredo Garcia, Mingyi Hong
分类: cs.LG, cs.AI
发布日期: 2026-02-18
💡 一句话要点
HiPER:通过显式信用分配的分层强化学习提升LLM Agent性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分层强化学习 LLM Agent 信用分配 长时程决策 多轮交互
📋 核心要点
- 现有强化学习方法在训练LLM Agent进行长时程决策时,面临稀疏奖励和延迟反馈带来的信用分配难题。
- HiPER框架通过分层规划-执行模式,将策略分解为高层规划和低层执行,显式地进行时间抽象。
- HiPER在ALFWorld和WebShop等基准测试中取得了显著的性能提升,尤其在长时程任务中表现突出。
📝 摘要(中文)
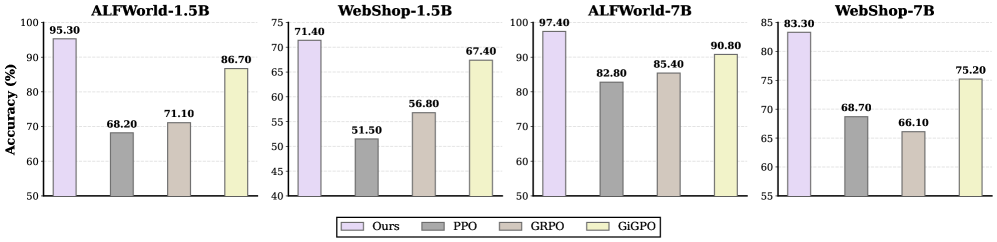
本文提出HiPER,一种新颖的分层计划-执行强化学习框架,它显式地分离了高层规划和低层执行。HiPER将策略分解为提出子目标的高层规划器和在多个动作步骤中执行子目标的低层执行器。为了使优化与这种结构对齐,引入了一种称为分层优势估计(HAE)的关键技术,该技术在规划和执行层面仔细地分配信用。通过聚合每个子目标执行过程中的回报,并协调两个层面的更新,HAE提供了一个无偏的梯度估计器,并证明了与扁平广义优势估计相比,方差更小。实验表明,HiPER在具有挑战性的交互式基准测试中取得了最先进的性能,在使用Qwen2.5-7B-Instruct时,在ALFWorld上达到了97.4%的成功率,在WebShop上达到了83.3%的成功率(比最佳现有方法分别提高了+6.6%和+8.3%),尤其是在需要多个依赖子任务的长时程任务上获得了很大的提升。这些结果突出了显式分层分解对于多轮LLM Agent的可扩展强化学习训练的重要性。
🔬 方法详解
问题定义:论文旨在解决LLM Agent在多轮交互决策任务中,由于长时程、稀疏奖励和延迟反馈导致的信用分配问题。现有的强化学习方法通常采用扁平策略,难以在整个轨迹上有效地传播信用,导致优化不稳定和信用分配效率低下。
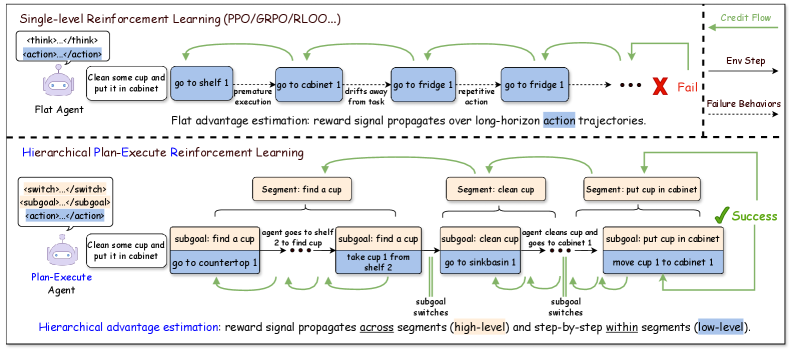
核心思路:论文的核心思路是将策略分解为高层规划和低层执行两个层次。高层规划器负责提出子目标,低层执行器负责在多个动作步骤中完成这些子目标。通过这种分层结构,可以显式地进行时间抽象,从而更容易进行信用分配和策略优化。
技术框架:HiPER框架包含两个主要模块:高层规划器和低层执行器。高层规划器接收环境状态作为输入,输出子目标。低层执行器接收环境状态和子目标作为输入,输出动作。整个框架通过强化学习进行训练,目标是最大化累积奖励。关键在于分层优势估计(HAE),用于在规划和执行层面进行信用分配。
关键创新:最重要的技术创新点是分层优势估计(HAE)。HAE通过聚合每个子目标执行过程中的回报,并协调两个层面的更新,提供了一个无偏的梯度估计器,并降低了方差。与传统的扁平优势估计相比,HAE能够更准确地评估规划和执行的贡献,从而实现更有效的信用分配。
关键设计:HAE的关键设计在于如何计算高层和低层的优势函数。高层优势函数评估规划的子目标的价值,而低层优势函数评估执行动作的价值。这两个优势函数通过时间差分学习进行估计,并用于更新高层规划器和低层执行器的策略。论文还详细描述了如何选择合适的奖励函数和探索策略,以提高训练效率和性能。
🖼️ 关键图片
📊 实验亮点
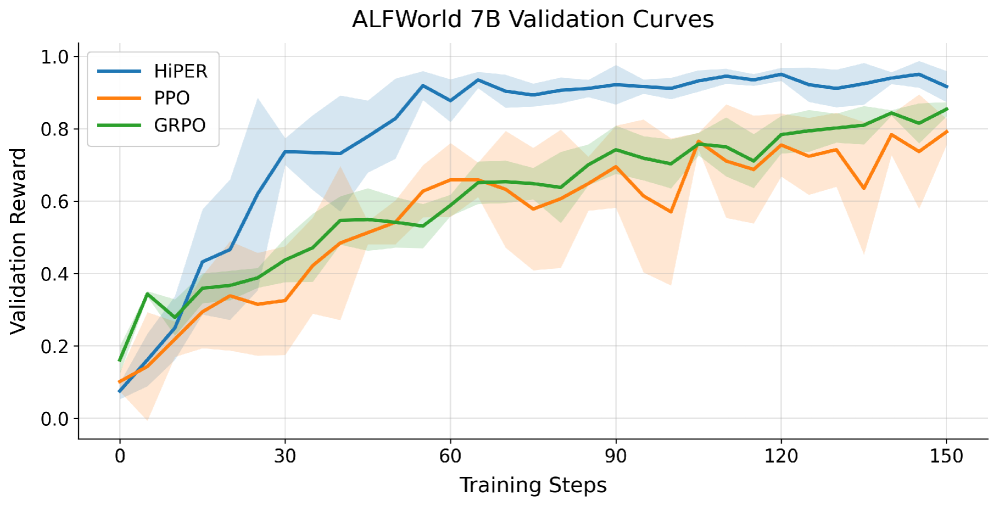
HiPER在ALFWorld和WebShop等具有挑战性的交互式基准测试中取得了显著的性能提升。具体来说,在使用Qwen2.5-7B-Instruct时,HiPER在ALFWorld上达到了97.4%的成功率,在WebShop上达到了83.3%的成功率,分别比最佳现有方法提高了+6.6%和+8.3%。尤其是在需要多个依赖子任务的长时程任务上,HiPER的优势更加明显。
🎯 应用场景
HiPER框架可应用于各种需要LLM Agent进行多轮交互决策的任务,例如:智能家居控制、任务导向对话、游戏AI、机器人导航等。该研究有助于提升LLM Agent在复杂环境中的自主性和决策能力,使其能够更好地完成长时程、高难度的任务,具有广泛的应用前景。
📄 摘要(原文)
Training LLMs as interactive agents for multi-turn decision-making remains challenging, particularly in long-horizon tasks with sparse and delayed rewards, where agents must execute extended sequences of actions before receiving meaningful feedback. Most existing reinforcement learning (RL) approaches model LLM agents as flat policies operating at a single time scale, selecting one action at each turn. In sparse-reward settings, such flat policies must propagate credit across the entire trajectory without explicit temporal abstraction, which often leads to unstable optimization and inefficient credit assignment. We propose HiPER, a novel Hierarchical Plan-Execute RL framework that explicitly separates high-level planning from low-level execution. HiPER factorizes the policy into a high-level planner that proposes subgoals and a low-level executor that carries them out over multiple action steps. To align optimization with this structure, we introduce a key technique called hierarchical advantage estimation (HAE), which carefully assigns credit at both the planning and execution levels. By aggregating returns over the execution of each subgoal and coordinating updates across the two levels, HAE provides an unbiased gradient estimator and provably reduces variance compared to flat generalized advantage estimation. Empirically, HiPER achieves state-of-the-art performance on challenging interactive benchmarks, reaching 97.4\% success on ALFWorld and 83.3\% on WebShop with Qwen2.5-7B-Instruct (+6.6\% and +8.3\% over the best prior method), with especially large gains on long-horizon tasks requiring multiple dependent subtasks. These results highlight the importance of explicit hierarchical decomposition for scalable RL training of multi-turn LLM agents.