Operationalising the Superficial Alignment Hypothesis via Task Complexity
作者: Tomás Vergara-Browne, Darshan Patil, Ivan Titov, Siva Reddy, Tiago Pimentel, Marius Mosbach
分类: cs.LG
发布日期: 2026-02-17
💡 一句话要点
通过任务复杂度量化,揭示大语言模型中的表层对齐假设
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表层对齐假设 任务复杂度 大型语言模型 预训练 后训练
📋 核心要点
- 现有研究对表层对齐假设缺乏精确定义,导致对其理解存在分歧,难以有效验证和应用。
- 论文提出“任务复杂度”这一新指标,定义为达到目标性能的最短程序长度,以此量化表层对齐假设。
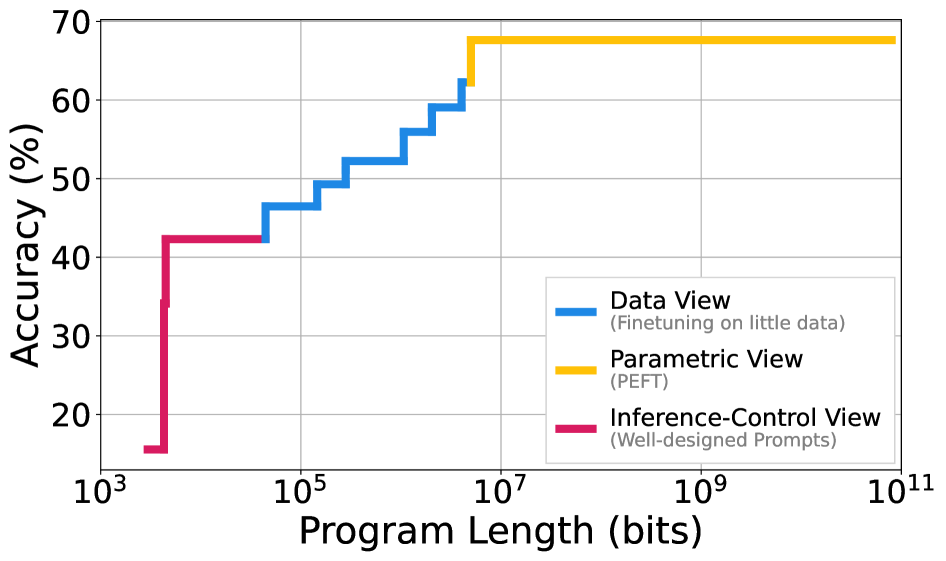
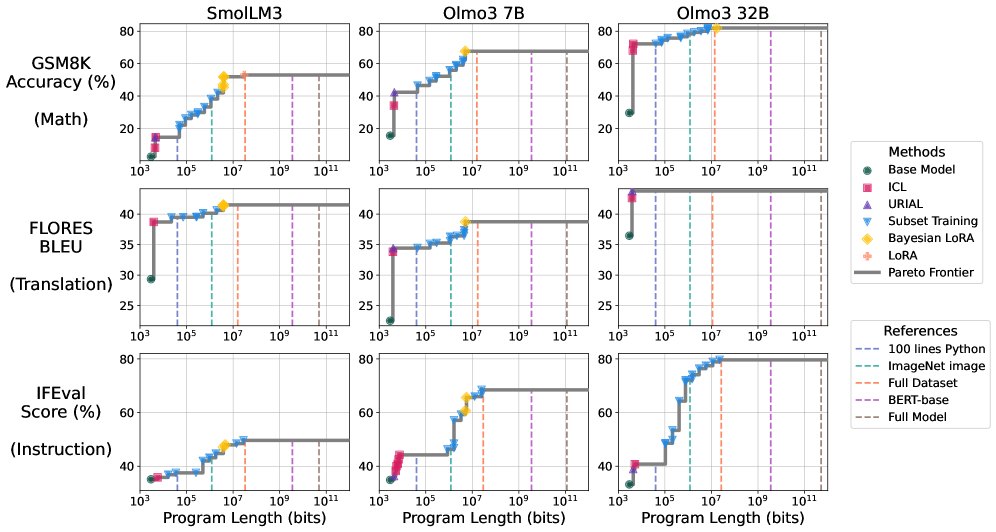
- 实验表明,预训练显著降低了数学推理、机器翻译和指令跟随等任务的复杂度,后训练进一步降低复杂度数量级。
📝 摘要(中文)
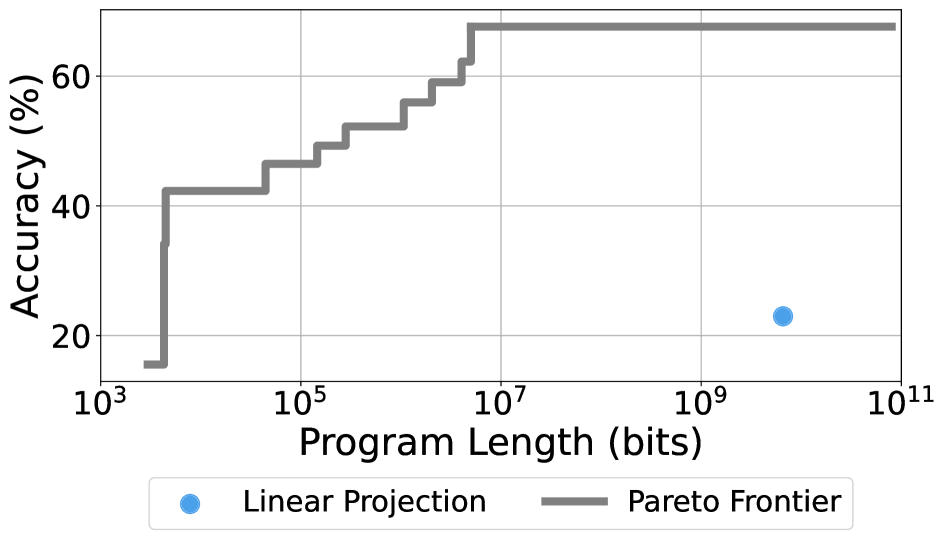
表层对齐假设(SAH)认为,大型语言模型的大部分知识是在预训练阶段学习的,而后训练只是将这些知识呈现出来。然而,SAH缺乏精确的定义,导致了(i)支持它的不同且看似正交的论点,以及(ii)对其的重要批评。我们提出了一种新的度量标准,称为任务复杂度:在任务上达到目标性能的最短程序的长度。在这个框架中,SAH简单地声称,预训练模型大大降低了在许多任务上实现高性能的复杂度。我们的定义统一了先前支持SAH的论点,将其解释为寻找这种短程序的各种策略。在实验中,我们估计了数学推理、机器翻译和指令遵循的任务复杂度;然后表明,当以预训练模型为条件时,这些复杂度可以非常低。此外,我们发现预训练能够访问我们任务中的强大性能,但可能需要千兆字节长度的程序才能访问它们。另一方面,后训练将达到相同性能的复杂度降低了几个数量级。总的来说,我们的结果表明,任务适应通常只需要非常少的信息——通常只有几千字节。
🔬 方法详解
问题定义:论文旨在解决如何量化和验证大型语言模型中的表层对齐假设(SAH)的问题。现有的SAH相关研究缺乏统一的度量标准,导致对SAH的理解和验证存在困难,无法有效指导模型训练和应用。现有方法难以准确评估预训练和后训练阶段对模型性能的贡献。
核心思路:论文的核心思路是将SAH与程序长度联系起来,认为预训练模型通过学习大量知识,使得后续任务只需要很短的程序就能达到高性能。因此,任务复杂度被定义为达到目标性能所需的最短程序长度,以此来量化SAH。通过比较预训练和后训练阶段的任务复杂度,可以评估SAH的有效性。
技术框架:论文的技术框架主要包括以下几个步骤:1) 定义任务复杂度:将任务复杂度定义为达到目标性能的最短程序长度。2) 选择任务:选择数学推理、机器翻译和指令跟随等任务进行实验。3) 估计任务复杂度:使用不同的方法估计在预训练和后训练阶段的任务复杂度。4) 分析结果:比较不同阶段的任务复杂度,验证SAH。
关键创新:论文最重要的技术创新点在于提出了“任务复杂度”这一新的度量标准,将SAH与程序长度联系起来,为量化和验证SAH提供了一种新的视角。与现有方法相比,该方法更加客观和可量化,能够更准确地评估预训练和后训练阶段对模型性能的贡献。
关键设计:论文的关键设计包括:1) 使用不同的方法估计任务复杂度,例如使用不同的优化算法和模型架构。2) 选择不同的任务进行实验,以验证该方法的泛化能力。3) 详细分析实验结果,探讨预训练和后训练阶段对模型性能的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,预训练能够显著降低数学推理、机器翻译和指令跟随等任务的复杂度,使得模型能够以较短的程序达到高性能。后训练进一步降低了复杂度,有时甚至降低了几个数量级。例如,在某些任务上,达到相同性能所需的程序长度从千兆字节级别降低到几千字节级别。
🎯 应用场景
该研究成果可应用于指导大型语言模型的预训练和后训练策略,优化模型训练过程,提高模型在各种任务上的性能。通过量化任务复杂度,可以更好地理解模型的学习过程,并为模型压缩、知识蒸馏等技术提供理论基础。此外,该研究还可以应用于评估不同预训练模型的质量和适用性。
📄 摘要(原文)
The superficial alignment hypothesis (SAH) posits that large language models learn most of their knowledge during pre-training, and that post-training merely surfaces this knowledge. The SAH, however, lacks a precise definition, which has led to (i) different and seemingly orthogonal arguments supporting it, and (ii) important critiques to it. We propose a new metric called task complexity: the length of the shortest program that achieves a target performance on a task. In this framework, the SAH simply claims that pre-trained models drastically reduce the complexity of achieving high performance on many tasks. Our definition unifies prior arguments supporting the SAH, interpreting them as different strategies to find such short programs. Experimentally, we estimate the task complexity of mathematical reasoning, machine translation, and instruction following; we then show that these complexities can be remarkably low when conditioned on a pre-trained model. Further, we find that pre-training enables access to strong performances on our tasks, but it can require programs of gigabytes of length to access them. Post-training, on the other hand, collapses the complexity of reaching this same performance by several orders of magnitude. Overall, our results highlight that task adaptation often requires surprisingly little information -- often just a few kilobytes.