Solving Parameter-Robust Avoid Problems with Unknown Feasibility using Reinforcement Learning
作者: Oswin So, Eric Yang Yu, Songyuan Zhang, Matthew Cleaveland, Mitchell Black, Chuchu Fan
分类: cs.LG, cs.RO, math.OC
发布日期: 2026-02-17
备注: ICLR 2026. The project page can be found at https://oswinso.xyz/fge
💡 一句话要点
提出可行性引导探索(FGE)算法,解决参数鲁棒避障问题中未知可行域的挑战。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 鲁棒控制 避障 可达性分析 可行性探索
📋 核心要点
- 传统强化学习在可达性问题中存在不匹配,难以保证在所有安全状态下的鲁棒性。
- 论文提出可行性引导探索(FGE)算法,同时探索可行初始条件并学习安全策略。
- 实验表明,FGE在复杂任务中显著提升了策略的覆盖率,优于现有方法。
📝 摘要(中文)
深度强化学习(RL)在解决高维控制问题上取得了显著成果,但将其应用于可达性问题时存在根本性不匹配:可达性旨在最大化系统保持无限期安全的起始状态集合,而RL优化的是用户指定分布上的期望回报。这种不匹配可能导致策略在低概率状态下表现不佳,而这些状态仍然在安全集合内。一个自然的替代方案是将问题构建为初始条件集合上的鲁棒优化,这些初始条件指定了初始状态、动力学和安全集合,但该问题是否有解取决于指定集合的可行性,而这是先验未知的。我们提出可行性引导探索(FGE),该方法同时识别可行初始条件的子集(在该子集下存在安全策略),并学习策略以解决该初始条件集合上的可达性问题。实验结果表明,在MuJoCo模拟器和具有像素观测的Kinetix模拟器中的各种任务中,FGE学习到的策略比现有最佳方法在具有挑战性的初始条件下覆盖率高出50%以上。
🔬 方法详解
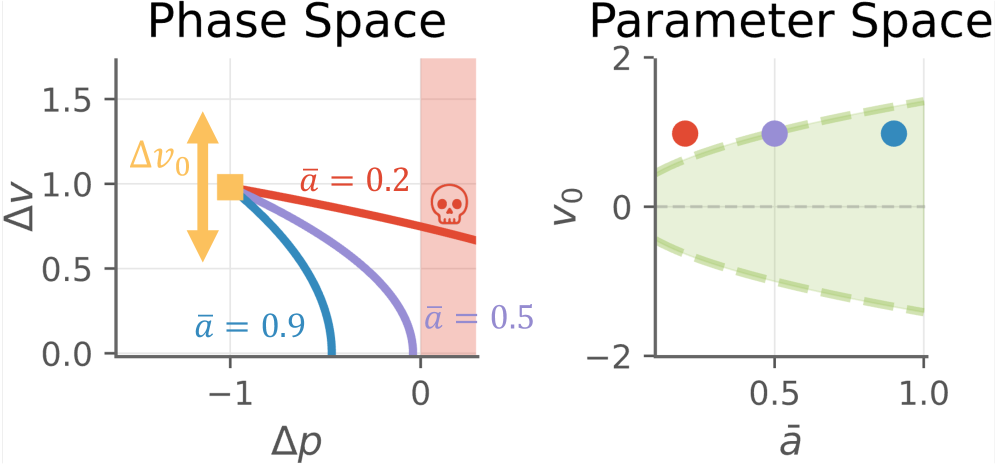
问题定义:论文旨在解决参数鲁棒避障问题,其中初始状态、动力学和安全集合存在不确定性,且问题的可行性(即是否存在安全策略)是未知的。现有方法通常假设可行域已知,或者难以在低概率但重要的状态下保证策略的鲁棒性。
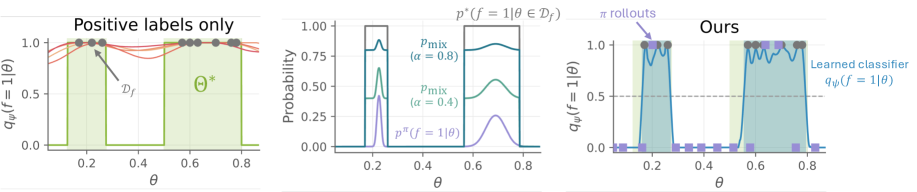
核心思路:FGE的核心思想是同时进行可行域的探索和策略的学习。它通过引导探索,优先探索那些更有可能存在安全策略的初始条件,从而避免在不可行区域浪费计算资源。同时,它学习一个策略,使得系统能够从这些可行初始条件出发,安全地到达目标区域。
技术框架:FGE算法包含两个主要部分:可行性评估和策略学习。可行性评估模块负责判断当前初始条件是否可能存在安全策略,并给出探索方向的建议。策略学习模块则利用强化学习算法,学习从可行初始条件出发的安全策略。这两个模块相互作用,共同优化,最终找到一个可行初始条件集合以及相应的安全策略。
关键创新:FGE的关键创新在于将可行性探索和策略学习结合起来,形成一个闭环的优化过程。传统方法通常将这两个步骤分开处理,或者假设可行域已知。FGE通过同时探索可行域和学习策略,能够更有效地解决参数鲁棒避障问题,尤其是在可行域未知的情况下。
关键设计:FGE算法中,可行性评估模块可以使用多种方法实现,例如基于模型的预测或者基于样本的评估。策略学习模块可以使用各种强化学习算法,例如TRPO、PPO等。论文中具体使用了哪种强化学习算法未知。损失函数的设计需要同时考虑策略的安全性(避免碰撞)和效率(尽快到达目标)。具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FGE算法在MuJoCo和Kinetix模拟器中的多个任务上,相比现有最佳方法,策略的覆盖率提升了50%以上。这表明FGE算法在解决参数鲁棒避障问题上具有显著的优势,尤其是在具有挑战性的初始条件下。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、航空航天等领域,解决在复杂、不确定环境下安全可靠地控制系统的问题。例如,在自动驾驶中,可以利用FGE算法学习在各种交通状况和车辆参数下的安全驾驶策略。在机器人导航中,可以帮助机器人在未知环境中安全地避开障碍物。
📄 摘要(原文)
Recent advances in deep reinforcement learning (RL) have achieved strong results on high-dimensional control tasks, but applying RL to reachability problems raises a fundamental mismatch: reachability seeks to maximize the set of states from which a system remains safe indefinitely, while RL optimizes expected returns over a user-specified distribution. This mismatch can result in policies that perform poorly on low-probability states that are still within the safe set. A natural alternative is to frame the problem as a robust optimization over a set of initial conditions that specify the initial state, dynamics and safe set, but whether this problem has a solution depends on the feasibility of the specified set, which is unknown a priori. We propose Feasibility-Guided Exploration (FGE), a method that simultaneously identifies a subset of feasible initial conditions under which a safe policy exists, and learns a policy to solve the reachability problem over this set of initial conditions. Empirical results demonstrate that FGE learns policies with over 50% more coverage than the best existing method for challenging initial conditions across tasks in the MuJoCo simulator and the Kinetix simulator with pixel observations.