Neural Scaling Laws for Boosted Jet Tagging
作者: Matthias Vigl, Nicole Hartman, Michael Kagan, Lukas Heinrich
分类: hep-ex, cs.LG, hep-ph, physics.data-an
发布日期: 2026-02-17
备注: 9 pages, 6 figures
💡 一句话要点
研究喷注标记任务的神经标度律,揭示算力、数据与性能间的关系。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经标度律 喷注标记 高能物理 机器学习 计算资源优化
📋 核心要点
- 高能物理领域模型训练算力远低于工业界,限制了性能提升,亟需研究算力与性能的scaling law。
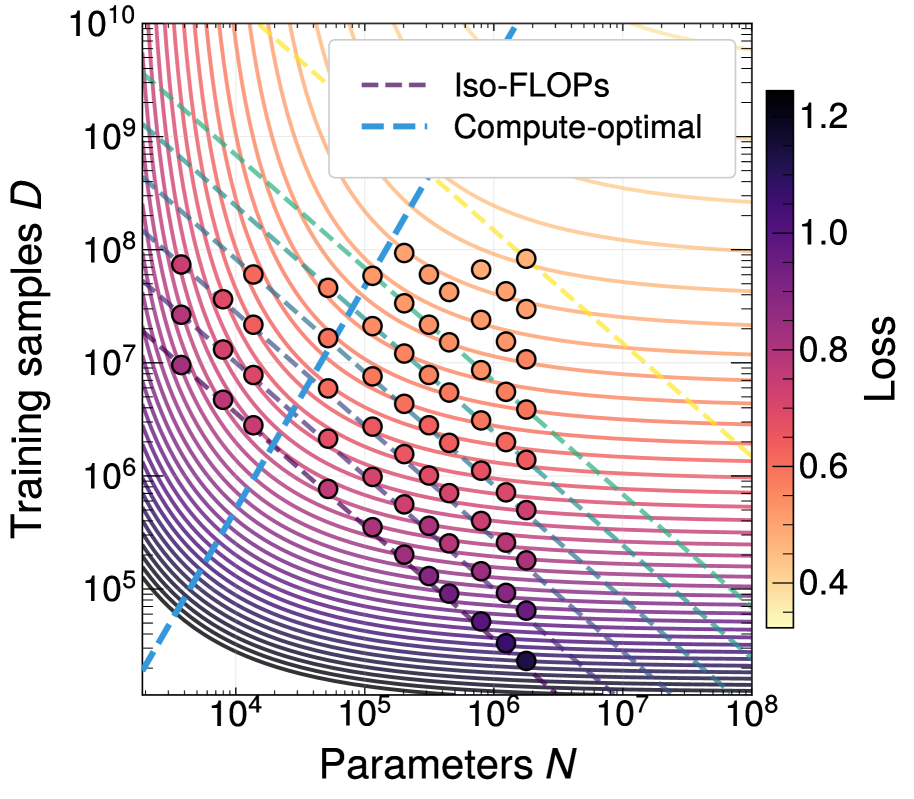
- 论文通过研究喷注分类任务,探索了算力、模型容量和数据集大小之间的关系,并推导了计算最优的scaling law。
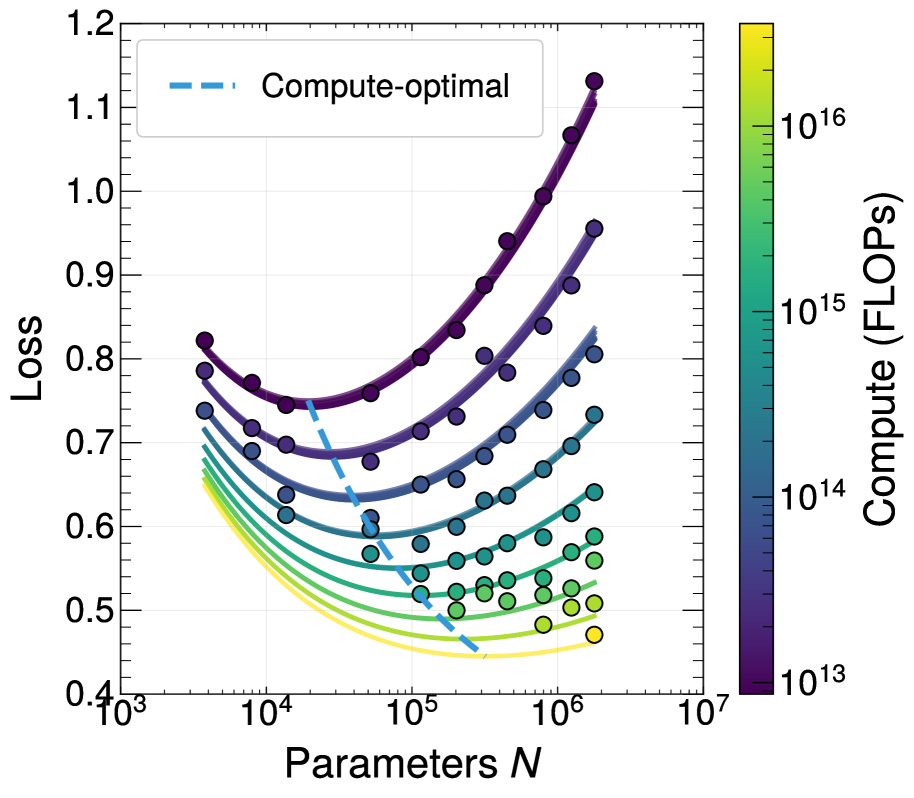
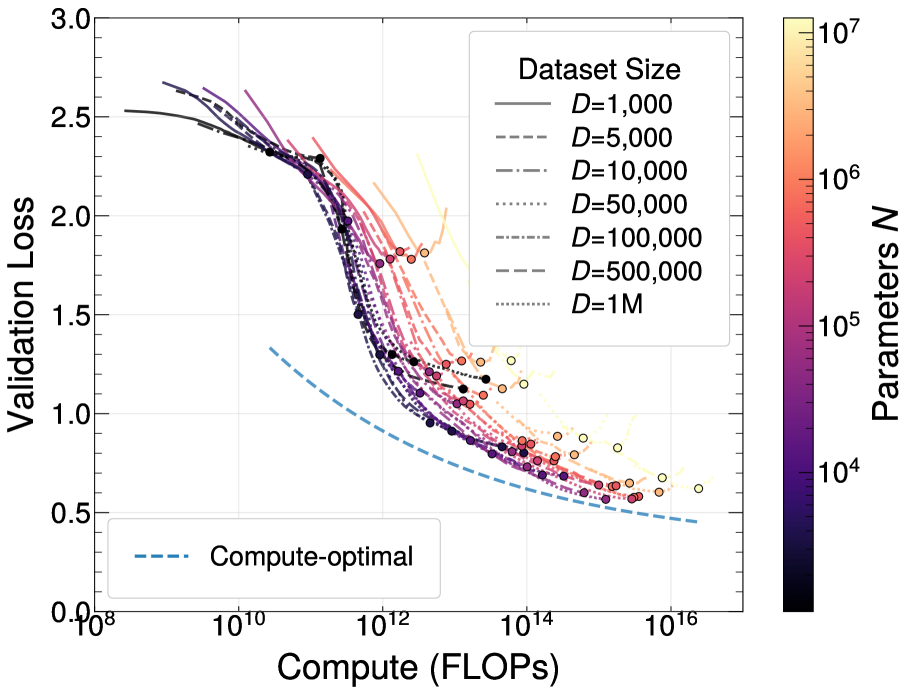
- 实验表明,增加算力能可靠地提升性能至渐近极限,更具表达力的底层特征能提高性能上限,改善结果。
📝 摘要(中文)
大型语言模型(LLM)的成功表明,通过联合增加模型容量和数据集大小来扩展计算是现代机器学习性能的主要驱动力。虽然机器学习早已是高能物理(HEP)数据分析工作流程不可或缺的组成部分,但用于训练最先进的HEP模型的计算量仍然比工业基础模型低几个数量级。由于该领域的标度律才刚刚开始研究,我们使用公开的JetClass数据集研究了增强喷注分类的神经标度律。我们推导了计算最优标度律,并确定了一个可以通过增加计算量持续接近的有效性能极限。我们研究了在模拟成本高昂的HEP中常见的数据重复如何改变标度,从而产生可量化的有效数据集大小增益。然后,我们研究了标度系数和渐近性能极限如何随输入特征和粒子多重性的选择而变化,证明了增加的计算量可靠地将性能推向渐近极限,并且更具表现力的低级特征可以提高性能极限并在固定的数据集大小下改善结果。
🔬 方法详解
问题定义:论文旨在研究高能物理领域中喷注标记任务的神经标度律。现有方法在高能物理领域应用机器学习时,由于算力资源的限制,模型性能提升受限,缺乏对算力、数据量和模型性能之间关系的深入理解。现有方法难以充分利用高能物理领域的数据特性,例如数据重复等,从而影响模型性能。
核心思路:论文的核心思路是通过研究喷注分类任务,建立算力、模型容量和数据集大小之间的关系模型,即神经标度律。通过分析不同输入特征和粒子多重性对标度律的影响,揭示如何通过增加算力、选择更具表达力的特征来提升模型性能。论文还考虑了高能物理领域数据重复的特性,并将其纳入标度律的考量。
技术框架:论文使用JetClass数据集进行实验,该数据集包含喷注分类任务的数据。整体流程包括:1) 定义模型结构;2) 使用不同算力训练模型;3) 分析模型性能与算力、数据量之间的关系;4) 研究不同输入特征和粒子多重性对标度律的影响;5) 考虑数据重复对标度律的影响。通过实验数据拟合标度律的参数,并验证标度律的有效性。
关键创新:论文的关键创新在于:1) 在高能物理领域首次研究了神经标度律,为该领域模型训练提供了理论指导;2) 考虑了高能物理领域数据重复的特性,并将其纳入标度律的考量,更贴合实际应用场景;3) 分析了不同输入特征和粒子多重性对标度律的影响,为特征选择提供了依据。
关键设计:论文中,模型结构的选择、算力的分配、数据集的划分、以及标度律参数的拟合方法是关键设计。具体而言,模型结构需要足够灵活以适应不同复杂度的喷注分类任务,算力分配需要保证模型能够充分训练,数据集划分需要保证训练集和测试集的分布一致,标度律参数的拟合方法需要保证拟合结果的准确性。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了神经标度律在高能物理喷注分类任务中的有效性。实验结果表明,增加算力能够可靠地提升模型性能至渐近极限。更重要的是,使用更具表达力的底层特征能够提高性能上限,并在固定数据集大小下改善结果。论文还量化了数据重复对标度律的影响,为实际应用中数据增强策略的选择提供了依据。
🎯 应用场景
该研究成果可应用于高能物理实验的数据分析,例如喷注识别、粒子分类等任务。通过理解算力、数据和性能之间的关系,可以更有效地利用计算资源,提升模型性能,从而提高高能物理实验的分析效率和精度。此外,该研究方法也可推广到其他科学领域,为资源受限情况下的模型训练提供指导。
📄 摘要(原文)
The success of Large Language Models (LLMs) has established that scaling compute, through joint increases in model capacity and dataset size, is the primary driver of performance in modern machine learning. While machine learning has long been an integral component of High Energy Physics (HEP) data analysis workflows, the compute used to train state-of-the-art HEP models remains orders of magnitude below that of industry foundation models. With scaling laws only beginning to be studied in the field, we investigate neural scaling laws for boosted jet classification using the public JetClass dataset. We derive compute optimal scaling laws and identify an effective performance limit that can be consistently approached through increased compute. We study how data repetition, common in HEP where simulation is expensive, modifies the scaling yielding a quantifiable effective dataset size gain. We then study how the scaling coefficients and asymptotic performance limits vary with the choice of input features and particle multiplicity, demonstrating that increased compute reliably drives performance toward an asymptotic limit, and that more expressive, lower-level features can raise the performance limit and improve results at fixed dataset size.