Latency-aware Human-in-the-Loop Reinforcement Learning for Semantic Communications
作者: Peizheng Li, Xinyi Lin, Adnan Aijaz
分类: eess.SP, cs.LG
发布日期: 2026-02-17
备注: 6 pages, 8 figures. This paper has been accepted for publication in IEEE ICC 2026
💡 一句话要点
提出时延感知的人在环强化学习框架,用于语义通信中的资源调度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语义通信 人在环强化学习 时延感知 资源调度 约束马尔可夫决策过程
📋 核心要点
- 现有语义通信方法难以在保证语义保真度的同时满足严格的时延需求,尤其是在人机交互场景下。
- 该论文提出了一种时延约束的人在环强化学习框架,通过人类反馈、语义效用和时延控制实现语义自适应。
- 实验结果表明,该方法在满足用户时延约束的同时,提升了奖励并稳定了资源消耗,优于传统调度器。
📝 摘要(中文)
语义通信旨在实现任务对齐的传输,但必须在沉浸式和安全关键服务中协调语义保真度和严格的时延保证。本文提出了一种时间约束的人在环强化学习(TC-HITL-RL)框架,该框架将人类反馈、语义效用和时延控制嵌入到语义感知的开放无线接入网络(RAN)架构中。我们将人类反馈驱动的语义自适应建模为一个约束马尔可夫决策过程(CMDP),其状态捕获语义质量、人类偏好、队列松弛和信道动态,并通过具有动作屏蔽和时延感知奖励塑造的原始-对偶近端策略优化算法来解决它。由此产生的策略在保持PPO级别语义奖励的同时,收紧了空口接口和近实时RAN智能控制器处理预算的可变性。在具有异构截止时间的点对多点链路上的仿真表明,TC-HITL-RL始终满足每个用户的时序约束,在奖励方面优于基线调度器,并稳定资源消耗,为时延感知的语义自适应提供了一个实用的蓝图。
🔬 方法详解
问题定义:论文旨在解决语义通信中,如何在满足严格时延约束的前提下,最大化语义信息的传输效用,尤其是在需要考虑人类反馈的场景下。现有方法通常难以兼顾语义保真度和时延要求,或者缺乏对人类偏好的有效建模。
核心思路:论文的核心思路是将语义通信问题建模为一个约束马尔可夫决策过程(CMDP),其中状态空间包含语义质量、人类偏好、队列松弛和信道动态等信息。通过强化学习算法学习最优策略,在满足时延约束的同时,最大化语义效用。关键在于将人类反馈融入到奖励函数中,并采用时延感知的奖励塑造方法。
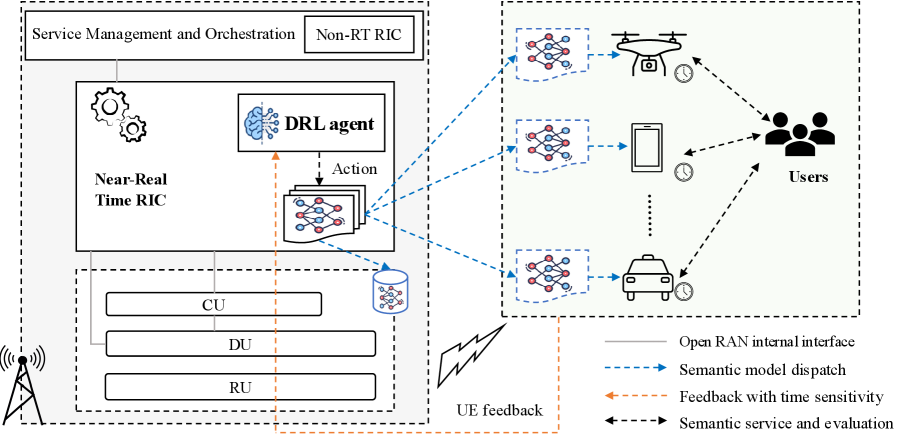
技术框架:整体框架包含三个主要部分:语义感知的开放无线接入网络(RAN)、人类反馈模块和强化学习智能体。RAN负责语义信息的提取和传输,人类反馈模块收集用户的偏好信息,强化学习智能体根据RAN的状态和人类反馈,动态调整传输策略。具体流程是:RAN将当前状态信息传递给强化学习智能体,智能体根据当前策略选择动作(例如,资源分配),RAN执行该动作并获得奖励,人类反馈模块提供反馈信号,智能体根据奖励和反馈更新策略。
关键创新:该论文的关键创新在于将人类反馈、语义效用和时延控制集成到一个统一的强化学习框架中。通过约束马尔可夫决策过程(CMDP)对问题进行建模,并设计了时延感知的奖励塑造方法,使得智能体能够学习到在满足时延约束的同时,最大化语义效用的策略。此外,采用了动作屏蔽技术,避免选择违反时延约束的动作。
关键设计:论文采用了原始-对偶近端策略优化(PPO)算法来解决CMDP问题。奖励函数的设计至关重要,它包含了语义奖励、时延惩罚和人类反馈。时延惩罚的设计需要仔细考虑,以保证智能体能够学习到满足时延约束的策略。动作屏蔽技术通过限制可选动作的范围,避免选择违反时延约束的动作。具体参数设置和网络结构在论文中未详细描述,属于未知信息。
🖼️ 关键图片
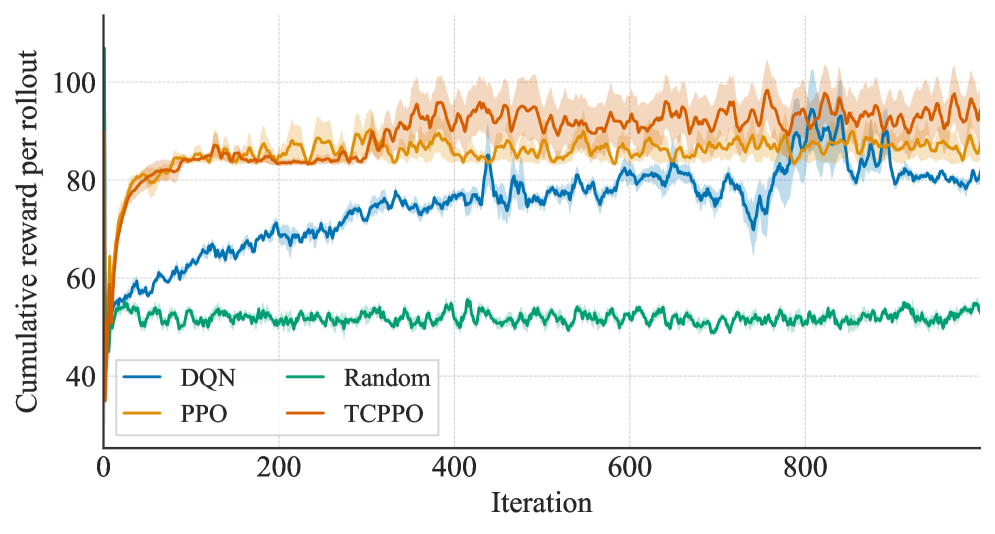
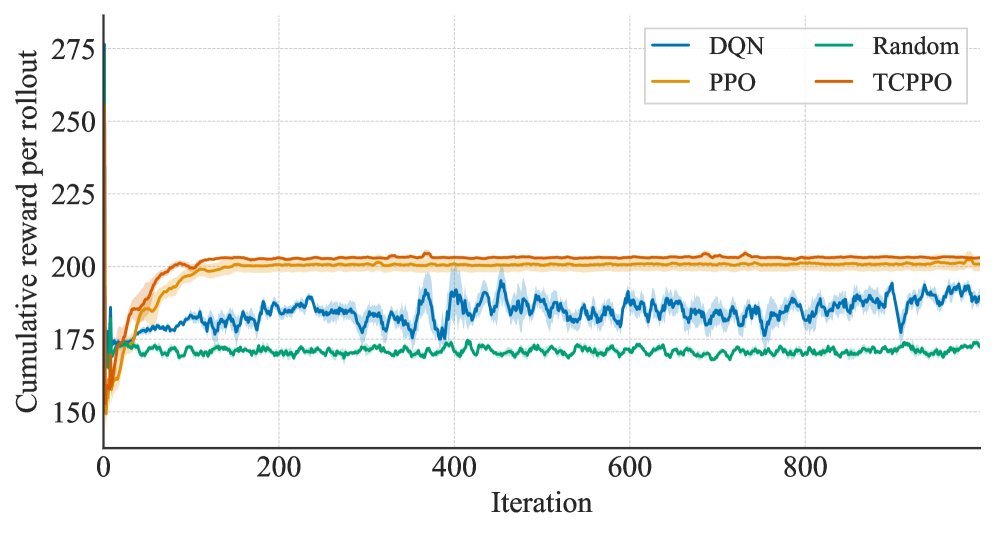
📊 实验亮点
仿真结果表明,TC-HITL-RL框架在满足用户时延约束方面表现出色,始终能够满足每个用户的时序要求。同时,在奖励方面优于基线调度器,表明该方法能够有效提升语义信息的传输效用。此外,该方法还能够稳定资源消耗,避免资源浪费。
🎯 应用场景
该研究成果可应用于需要低时延和高可靠性的语义通信场景,例如增强现实/虚拟现实(AR/VR)、远程医疗、自动驾驶等。通过考虑人类反馈和时延约束,可以提升用户体验和系统性能,为未来智能通信系统的设计提供参考。
📄 摘要(原文)
Semantic communication promises task-aligned transmission but must reconcile semantic fidelity with stringent latency guarantees in immersive and safety-critical services. This paper introduces a time-constrained human-in-the-loop reinforcement learning (TC-HITL-RL) framework that embeds human feedback, semantic utility, and latency control within a semantic-aware Open radio access network (RAN) architecture. We formulate semantic adaptation driven by human feedback as a constrained Markov decision process (CMDP) whose state captures semantic quality, human preferences, queue slack, and channel dynamics, and solve it via a primal--dual proximal policy optimization algorithm with action shielding and latency-aware reward shaping. The resulting policy preserves PPO-level semantic rewards while tightening the variability of both air-interface and near-real-time RAN intelligent controller processing budgets. Simulations over point-to-multipoint links with heterogeneous deadlines show that TC-HITL-RL consistently meets per-user timing constraints, outperforms baseline schedulers in reward, and stabilizes resource consumption, providing a practical blueprint for latency-aware semantic adaptation.