Neural-POD: A Plug-and-Play Neural Operator Framework for Infinite-Dimensional Functional Nonlinear Proper Orthogonal Decomposition
作者: Changhong Mou, Binghang Lu, Guang Lin
分类: physics.comp-ph, cs.LG, math.NA
发布日期: 2026-02-17
💡 一句话要点
提出Neural-POD,一种即插即用的神经算子框架,用于无限维函数非线性本征正交分解。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 神经算子 本征正交分解 降阶建模 非线性系统 AI for Science
📋 核心要点
- 传统AI for Science受限于离散化,学习到的表示依赖于训练时使用的特定网格或分辨率。
- Neural-POD通过神经网络构建无限维空间中的非线性正交基函数,解决了传统POD的线性局限性。
- 实验表明,Neural-POD在Burgers'和Navier-Stokes方程等复杂系统中表现出鲁棒性,并能与ROM和DeepONet集成。
📝 摘要(中文)
本文提出了一种神经本征正交分解(Neural-POD)框架,这是一种即插即用的神经算子框架,它利用神经网络在无限维空间中构建非线性正交基函数。与经典POD受限于通过奇异值分解(SVD)获得的线性子空间近似不同,Neural-POD将基函数的构建形式化为一系列残差最小化问题,并通过神经网络训练解决。每个基函数通过学习表示数据中的剩余结构获得,类似于Gram-Schmidt正交化过程。与经典POD相比,这种神经公式具有几个关键优势:它支持在任意范数(例如,$L^2$,$L^1$)中进行优化,学习分辨率不变的无限维函数空间之间的映射,有效地推广到未见过的参数范围,并固有地捕获复杂时空系统中的非线性结构。生成的基函数是可解释的、可重用的,并且能够集成到降阶建模(ROM)和算子学习框架(如DeepONet)中。通过Burgers'和Navier-Stokes方程等不同的复杂时空系统,验证了Neural-POD的鲁棒性。进一步表明,Neural-POD是经典Galerkin投影和算子学习之间的高性能即插即用桥梁,能够与基于投影的降阶模型和DeepONet框架保持一致的集成。
🔬 方法详解
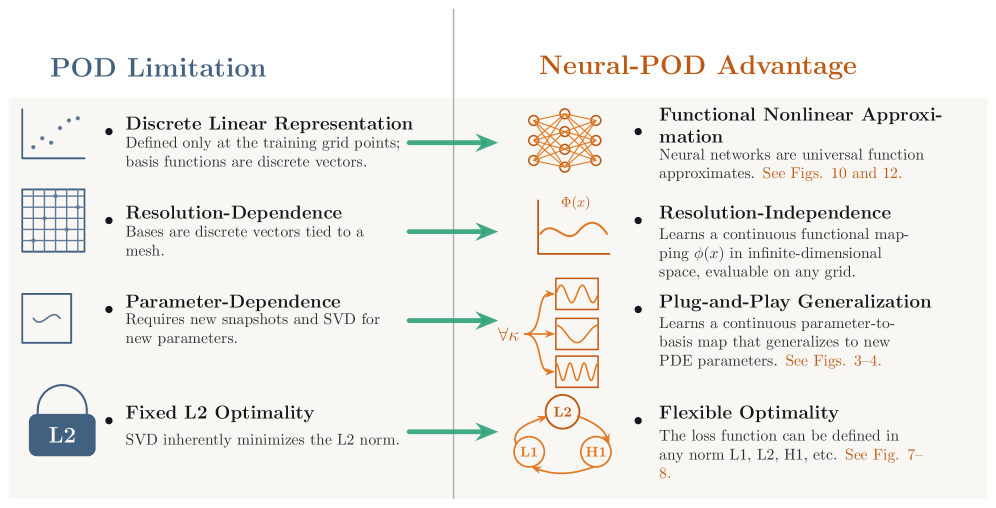
问题定义:传统Proper Orthogonal Decomposition (POD) 方法依赖于奇异值分解(SVD),只能进行线性子空间近似,无法有效捕捉复杂时空系统中的非线性结构,且对训练时使用的特定网格或分辨率具有依赖性。此外,经典POD在优化目标的选择上较为受限,难以灵活适应不同的应用场景。
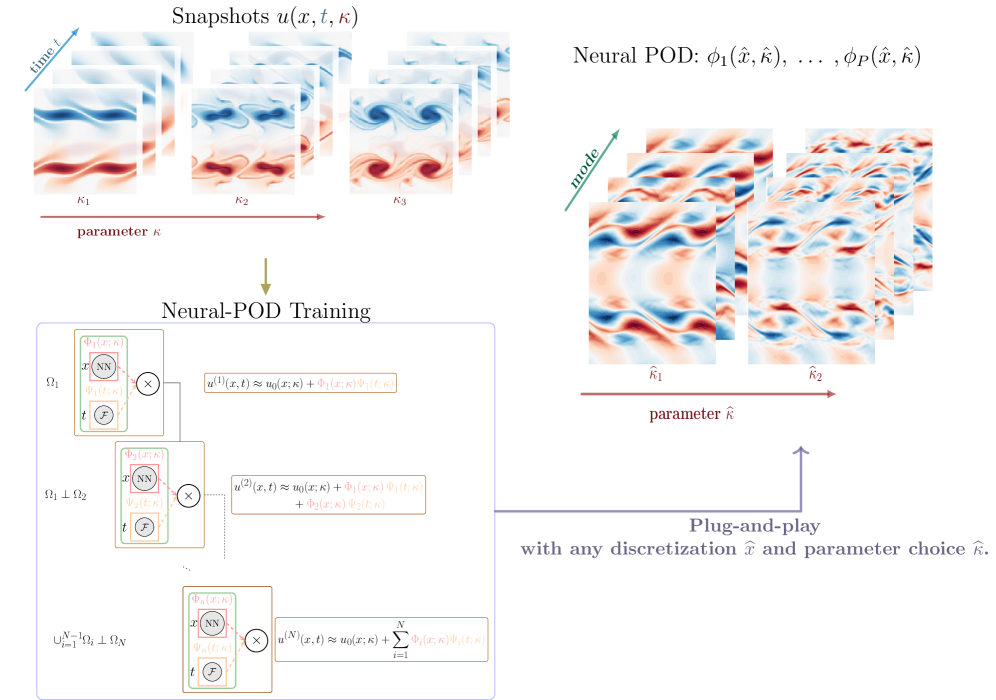
核心思路:Neural-POD的核心思路是将基函数的构建过程转化为一系列残差最小化问题,并通过神经网络来学习这些基函数。通过迭代地学习数据中的剩余结构,类似于Gram-Schmidt正交化过程,从而构建出一组非线性正交基函数。这种方法允许在任意范数下进行优化,并能够学习分辨率不变的函数空间映射。
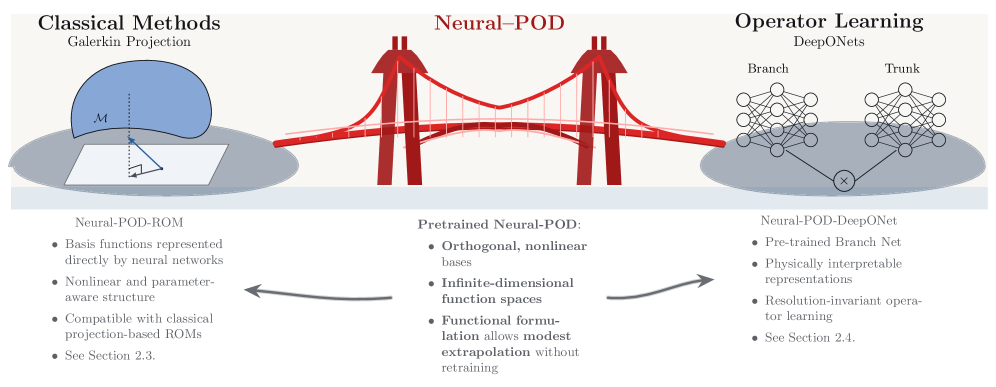
技术框架:Neural-POD的整体框架包含以下几个主要阶段:1) 数据准备:准备用于训练的时空系统数据。2) 基函数迭代学习:通过神经网络学习一系列基函数,每个基函数旨在表示数据中的剩余结构。3) 正交化:类似于Gram-Schmidt过程,确保学习到的基函数是正交的。4) 模型集成:将学习到的基函数集成到降阶模型(ROM)或算子学习框架(DeepONet)中。
关键创新:Neural-POD最重要的技术创新点在于使用神经网络来构建非线性正交基函数,从而突破了传统POD的线性局限性。与传统POD相比,Neural-POD能够更好地捕捉复杂时空系统中的非线性结构,并且具有分辨率不变性和更强的泛化能力。此外,Neural-POD允许在任意范数下进行优化,提供了更大的灵活性。
关键设计:Neural-POD的关键设计包括:1) 使用神经网络作为基函数的表示形式,允许学习复杂的非线性映射。2) 通过残差最小化来训练神经网络,确保每个基函数能够有效地表示数据中的剩余结构。3) 采用类似于Gram-Schmidt的正交化过程,保证基函数的正交性。4) 可以灵活选择不同的损失函数,以适应不同的优化目标(例如,$L^2$或$L^1$范数)。具体的网络结构和参数设置取决于具体的应用场景。
🖼️ 关键图片
📊 实验亮点
论文通过Burgers'和Navier-Stokes方程等复杂时空系统验证了Neural-POD的鲁棒性。实验结果表明,Neural-POD能够有效地学习非线性正交基函数,并能够与传统的Galerkin投影和DeepONet框架无缝集成。具体的性能数据和提升幅度在论文中进行了详细的展示,证明了Neural-POD在降阶建模和算子学习方面的优势。
🎯 应用场景
Neural-POD具有广泛的应用前景,包括但不限于:流体动力学、气候建模、材料科学等领域。它可以用于构建高性能的降阶模型,加速复杂系统的仿真和优化。此外,Neural-POD还可以作为算子学习框架的组成部分,提高算子学习的精度和泛化能力。该研究有望推动AI for Science的发展,并为解决科学和工程领域的实际问题提供新的工具。
📄 摘要(原文)
The rapid development of AI for Science is often hindered by the "discretization", where learned representations remain restricted to the specific grids or resolutions used during training. We propose the Neural Proper Orthogonal Decomposition (Neural-POD), a plug-and-play neural operator framework that constructs nonlinear, orthogonal basis functions in infinite-dimensional space using neural networks. Unlike the classical Proper Orthogonal Decomposition (POD), which is limited to linear subspace approximations obtained through singular value decomposition (SVD), Neural-POD formulates basis construction as a sequence of residual minimization problems solved through neural network training. Each basis function is obtained by learning to represent the remaining structure in the data, following a process analogous to Gram--Schmidt orthogonalization. This neural formulation introduces several key advantages over classical POD: it enables optimization in arbitrary norms (e.g., $L^2$, $L^1$), learns mappings between infinite-dimensional function spaces that is resolution-invariant, generalizes effectively to unseen parameter regimes, and inherently captures nonlinear structures in complex spatiotemporal systems. The resulting basis functions are interpretable, reusable, and enabling integration into both reduced order modeling (ROM) and operator learning frameworks such as deep operator learning (DeepONet). We demonstrate the robustness of Neural-POD with different complex spatiotemporal systems, including the Burgers' and Navier-Stokes equations. We further show that Neural-POD serves as a high performance, plug-and-play bridge between classical Galerkin projection and operator learning that enables consistent integration with both projection-based reduced order models and DeepONet frameworks.