On the Out-of-Distribution Generalization of Reasoning in Multimodal LLMs for Simple Visual Planning Tasks
作者: Yannic Neuhaus, Nicolas Flammarion, Matthias Hein, Francesco Croce
分类: cs.LG, cs.CV
发布日期: 2026-02-17
💡 一句话要点
评估多模态LLM在简单视觉规划任务中的推理泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 推理泛化 视觉规划 思维链 异分布泛化
📋 核心要点
- 现有大型语言模型和视觉-语言模型的推理泛化能力定义模糊,理解不足,尤其是在复杂任务中。
- 论文提出一个基于网格导航的评估框架,通过控制输入表示和推理策略,系统评估模型的同分布和异分布泛化能力。
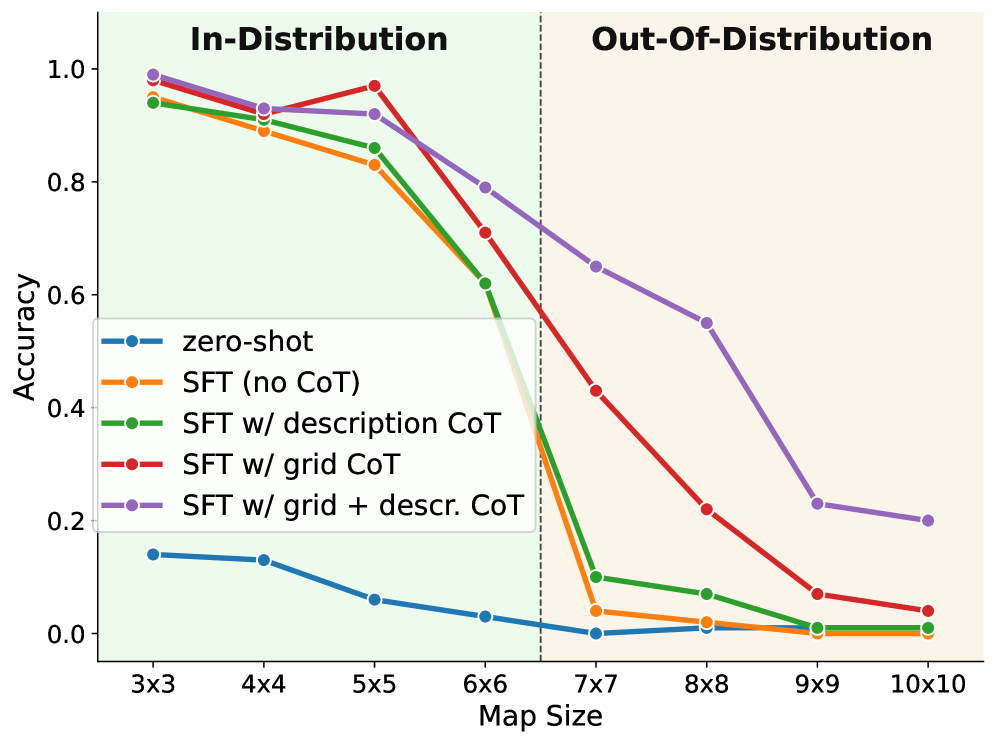
- 实验表明,思维链推理提升了同分布泛化能力,但异分布泛化能力有限,结合多种文本格式的推理轨迹表现最佳。
📝 摘要(中文)
本文旨在评估大型语言模型和视觉-语言模型中推理能力的泛化性。作者提出了一个评估框架,用于严格检验思维链(CoT)方法在简单规划任务中的泛化能力。该任务是一个基于网格的导航任务,模型需要根据地图输出一系列动作,引导玩家从起点到达目标点,同时避开障碍物。通过调整输入表示(视觉和文本)和CoT推理策略,并在同分布(ID)和异分布(OOD)测试条件下进行系统评估。实验结果表明,虽然CoT推理提高了所有表示的ID泛化能力,但OOD泛化能力(例如,对于更大的地图)在大多数情况下仍然非常有限。令人惊讶的是,结合多种文本格式的推理轨迹产生了最佳的OOD泛化能力。此外,纯文本模型始终优于使用基于图像输入的模型,包括最近提出的基于潜在空间推理的方法。
🔬 方法详解
问题定义:论文旨在研究多模态大型语言模型(MLLM)在简单视觉规划任务中的推理泛化能力。现有方法在异分布(OOD)数据上的泛化性能较差,尤其是在控制了与同分布(ID)数据的简单匹配后,性能下降更为明显。现有研究对推理泛化能力的评估不够系统和严格。
核心思路:论文的核心思路是通过设计一个可控的网格导航任务,系统地评估不同输入表示(视觉和文本)和思维链(CoT)推理策略对模型泛化能力的影响。通过控制地图大小、障碍物分布等因素,可以更精确地衡量模型在OOD数据上的表现。
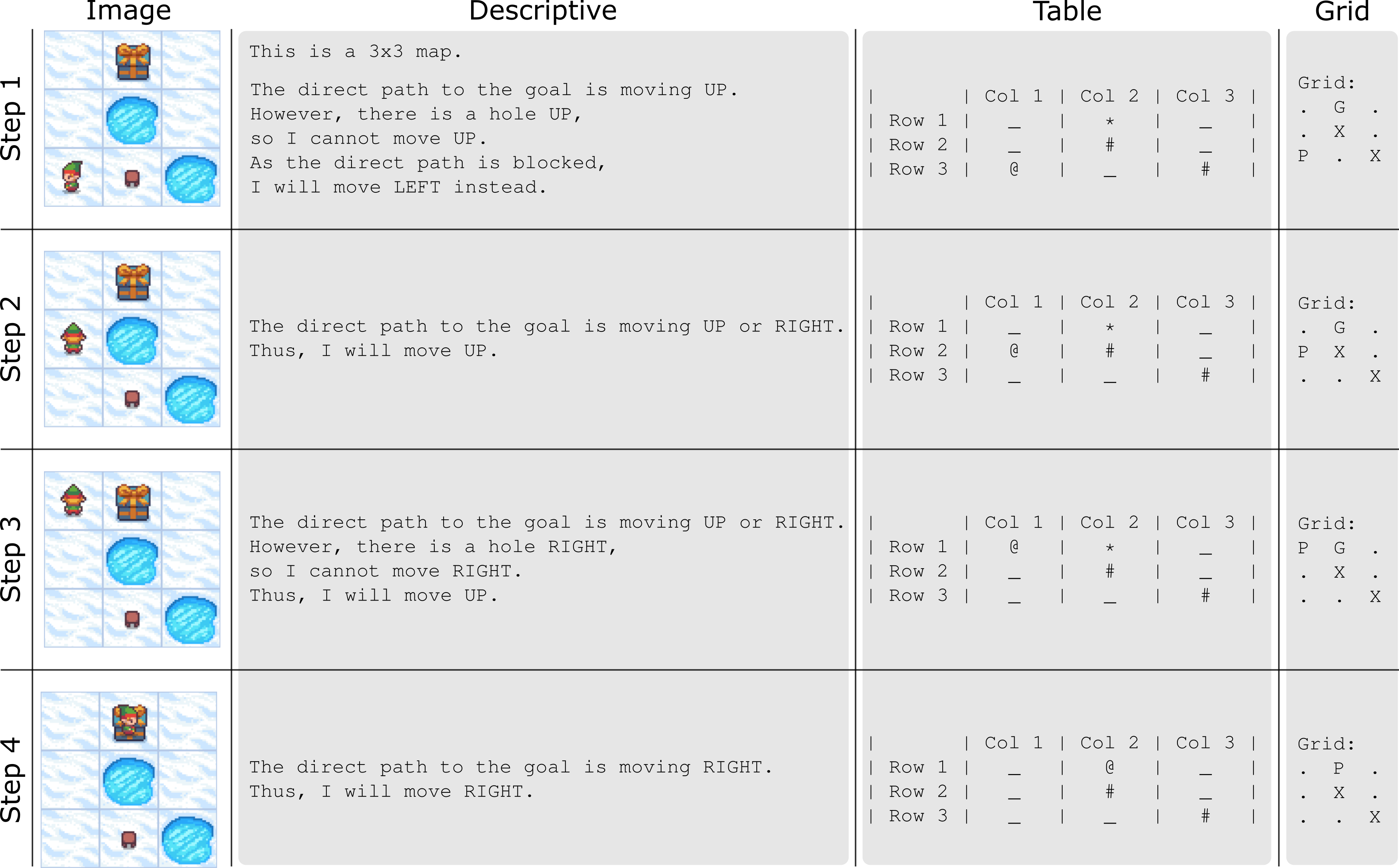
技术框架:整体框架包括以下几个主要步骤:1) 构建基于网格的导航任务,包括生成地图、定义起点和终点、以及障碍物;2) 使用不同的输入表示(图像、文本)对地图信息进行编码;3) 应用不同的CoT推理策略,生成导航指令序列;4) 在ID和OOD数据集上评估模型的导航成功率。模型主要包括视觉编码器(用于处理图像输入)、文本编码器(用于处理文本输入)和语言模型(用于生成导航指令)。
关键创新:论文的关键创新在于:1) 提出了一个用于评估MLLM推理泛化能力的系统性框架;2) 发现结合多种文本格式的推理轨迹能够显著提升OOD泛化能力;3) 揭示了纯文本模型在视觉规划任务中优于图像模型的现象,挑战了多模态模型的固有优势。
关键设计:论文的关键设计包括:1) 网格导航任务的设计,允许控制地图大小、障碍物密度等参数,从而系统地评估OOD泛化能力;2) 多种CoT推理策略的设计,包括单文本格式、多文本格式等,以研究不同推理方式对泛化能力的影响;3) 详细的实验设置,包括ID和OOD数据集的划分、模型参数的调整等,以保证实验结果的可靠性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,结合多种文本格式的推理轨迹在OOD数据集上表现出最佳的泛化能力,显著优于其他CoT策略。纯文本模型在视觉规划任务中始终优于使用图像输入的模型,这与通常认为多模态模型更具优势的观点相悖。在控制了与ID数据的简单匹配后,大多数模型的OOD泛化能力仍然非常有限。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、智能交通等领域。通过提升模型在复杂环境下的推理和泛化能力,可以提高机器人在未知环境中的自主决策能力,降低对人工干预的依赖,并为开发更智能、更可靠的AI系统奠定基础。
📄 摘要(原文)
Integrating reasoning in large language models and large vision-language models has recently led to significant improvement of their capabilities. However, the generalization of reasoning models is still vaguely defined and poorly understood. In this work, we present an evaluation framework to rigorously examine how well chain-of-thought (CoT) approaches generalize on a simple planning task. Specifically, we consider a grid-based navigation task in which a model is provided with a map and must output a sequence of moves that guides a player from a start position to a goal while avoiding obstacles. The versatility of the task and its data allows us to fine-tune model variants using different input representations (visual and textual) and CoT reasoning strategies, and systematically evaluate them under both in-distribution (ID) and out-of-distribution (OOD) test conditions. Our experiments show that, while CoT reasoning improves in-distribution generalization across all representations, out-of-distribution generalization (e.g., to larger maps) remains very limited in most cases when controlling for trivial matches with the ID data. Surprisingly, we find that reasoning traces which combine multiple text formats yield the best (and non-trivial) OOD generalization. Finally, purely text-based models consistently outperform those utilizing image-based inputs, including a recently proposed approach relying on latent space reasoning.