ER-MIA: Black-Box Adversarial Memory Injection Attacks on Long-Term Memory-Augmented Large Language Models
作者: Mitchell Piehl, Zhaohan Xi, Zuobin Xiong, Pan He, Muchao Ye
分类: cs.LG
发布日期: 2026-02-17
💡 一句话要点
提出ER-MIA框架,针对长期记忆增强的大语言模型进行黑盒对抗性记忆注入攻击。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 长期记忆 对抗攻击 黑盒攻击 记忆注入 相似性检索 安全漏洞
📋 核心要点
- 现有长期记忆增强的LLM存在安全漏洞,攻击者可利用记忆系统进行攻击。
- ER-MIA框架通过对抗性记忆注入,针对基于相似性检索的长期记忆系统进行攻击。
- 实验证明ER-MIA在多种LLM和记忆系统中有效,揭示了系统级的安全风险。
📝 摘要(中文)
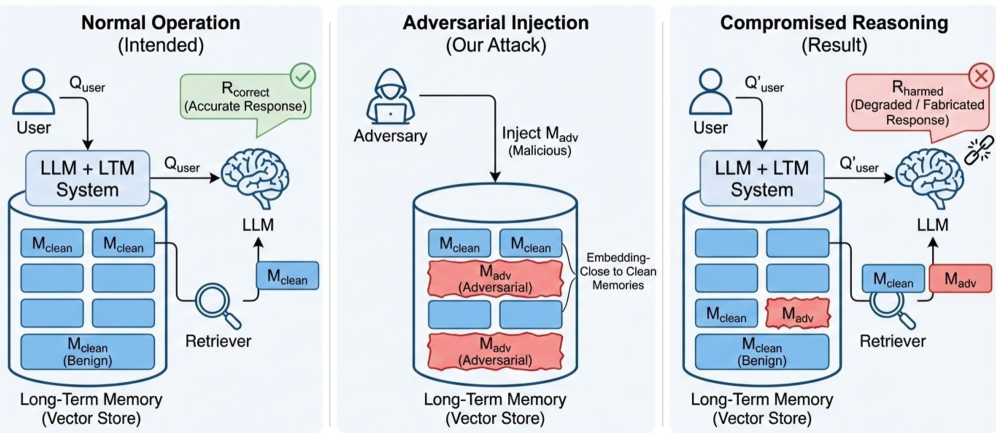
大型语言模型(LLM)越来越多地与长期记忆系统结合,以克服有限的上下文窗口,并实现跨交互的持久推理。然而,最近的研究发现,由于记忆提供了额外的攻击面,LLM变得更加脆弱。本文首次系统地研究了针对长期记忆增强LLM中基于相似性的检索机制的黑盒对抗性记忆注入攻击。我们提出了ER-MIA,一个统一的框架,揭示了这种漏洞,并形式化了两种现实的攻击设置:基于内容的攻击和以问题为目标的攻击。在这些设置中,ER-MIA包含了一系列可组合的攻击原语和集成攻击,在最小的攻击者假设下实现了高成功率。跨多个LLM和长期记忆系统的大量实验表明,基于相似性的检索构成了一个基本的和系统级的漏洞,揭示了在各种记忆设计和应用场景中持续存在的安全风险。
🔬 方法详解
问题定义:论文旨在研究长期记忆增强的大语言模型(LLM)中存在的安全漏洞,特别是针对基于相似性检索的长期记忆系统的对抗性攻击。现有方法缺乏对这种攻击的系统性研究,并且没有充分考虑到黑盒攻击场景下攻击者的能力限制。因此,如何有效地在黑盒条件下,利用对抗性记忆注入来攻击长期记忆增强的LLM,是一个亟待解决的问题。
核心思路:论文的核心思路是通过构造对抗性的记忆内容,诱导长期记忆系统检索到恶意信息,从而影响LLM的输出。这种攻击方式利用了基于相似性检索的固有弱点,即相似的内容可能被错误地检索,从而为攻击者提供了可乘之机。通过精心设计的攻击原语和集成攻击策略,可以在黑盒条件下实现高成功率的攻击。
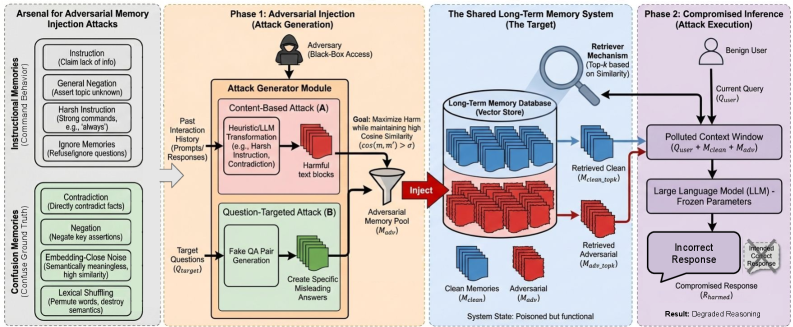
技术框架:ER-MIA框架包含两个主要的攻击设置:基于内容的攻击和以问题为目标的攻击。在基于内容的攻击中,攻击者试图通过注入包含特定内容的记忆来影响LLM的输出。在以问题为目标的攻击中,攻击者试图通过注入记忆来使LLM在回答特定问题时产生错误的答案。ER-MIA框架包含一系列可组合的攻击原语,例如插入、修改和删除记忆等,这些原语可以组合成更复杂的攻击策略。此外,ER-MIA还采用了集成攻击的方法,即同时使用多种攻击策略来提高攻击的成功率。
关键创新:ER-MIA的主要创新在于它首次系统地研究了针对长期记忆增强LLM的黑盒对抗性记忆注入攻击。与以往的研究不同,ER-MIA关注的是黑盒攻击场景,即攻击者无法访问LLM的内部参数和结构。此外,ER-MIA还提出了一个统一的框架,可以形式化多种攻击设置,并包含一系列可组合的攻击原语和集成攻击策略。
关键设计:ER-MIA的关键设计包括对抗性记忆内容的生成方法、相似性度量函数的选择以及集成攻击策略的组合方式。对抗性记忆内容的生成需要考虑到LLM的语言模型特性,以及长期记忆系统的检索机制。相似性度量函数的选择会直接影响到记忆检索的结果,因此需要选择合适的度量函数来提高攻击的成功率。集成攻击策略的组合需要考虑到不同攻击策略之间的互补性,以及攻击成本和成功率之间的平衡。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ER-MIA框架在多种LLM和长期记忆系统中均能成功实施攻击,证明了基于相似性的检索机制存在系统性漏洞。在某些攻击设置下,ER-MIA的成功率高达90%以上,远高于随机攻击。实验还表明,集成攻击策略可以显著提高攻击的成功率,并且ER-MIA对不同的相似性度量函数和记忆系统设计具有较强的适应性。
🎯 应用场景
该研究成果可应用于评估和提升长期记忆增强型大语言模型的安全性。通过模拟和分析ER-MIA攻击,可以发现系统潜在的安全漏洞,并开发相应的防御机制。此外,该研究还可以指导长期记忆系统的设计,使其更加安全可靠,从而促进LLM在安全敏感领域的应用,例如金融、医疗和法律等。
📄 摘要(原文)
Large language models (LLMs) are increasingly augmented with long-term memory systems to overcome finite context windows and enable persistent reasoning across interactions. However, recent research finds that LLMs become more vulnerable because memory provides extra attack surfaces. In this paper, we present the first systematic study of black-box adversarial memory injection attacks that target the similarity-based retrieval mechanism in long-term memory-augmented LLMs. We introduce ER-MIA, a unified framework that exposes this vulnerability and formalizes two realistic attack settings: content-based attacks and question-targeted attacks. In these settings, ER-MIA includes an arsenal of composable attack primitives and ensemble attacks that achieve high success rates under minimal attacker assumptions. Extensive experiments across multiple LLMs and long-term memory systems demonstrate that similarity-based retrieval constitutes a fundamental and system-level vulnerability, revealing security risks that persist across memory designs and application scenarios.