Discovering Implicit Large Language Model Alignment Objectives
作者: Edward Chen, Sanmi Koyejo, Carlos Guestrin
分类: cs.LG, cs.CL
发布日期: 2026-02-17
💡 一句话要点
提出Obj-Disco框架以解决LLM对齐目标不明确问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对齐目标 奖励信号 自动化分析 可解释性 安全性提升 迭代贪心算法
📋 核心要点
- 现有的对齐方法在奖励信号的解释上存在不足,容易导致模型行为的错位和奖励黑客。
- 提出的Obj-Disco框架通过自动分解奖励信号,识别可解释的自然语言目标,提供了一种新的解决方案。
- 实验结果显示,该框架在多种任务和模型上表现出色,能够捕获超过90%的奖励行为,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLM)的对齐依赖于复杂的奖励信号,这些信号往往模糊了具体的激励行为,导致潜在的错位和奖励黑客问题。现有的解释方法通常依赖于预定义的标准,可能遗漏“未知的未知”,或未能识别全面且因果的目标。为了解决这些局限性,本文提出了Obj-Disco框架,能够自动将对齐奖励信号分解为稀疏的、加权的人类可解释自然语言目标。该方法利用迭代贪心算法分析训练检查点间的行为变化,识别和验证最佳解释残余奖励信号的候选目标。广泛的评估表明该框架的稳健性,实验结果显示其能够持续捕获超过90%的奖励行为,并通过人类评估得到了进一步验证。
🔬 方法详解
问题定义:本文旨在解决大型语言模型对齐过程中奖励信号不明确的问题,现有方法容易导致模型行为的错位和奖励黑客现象。
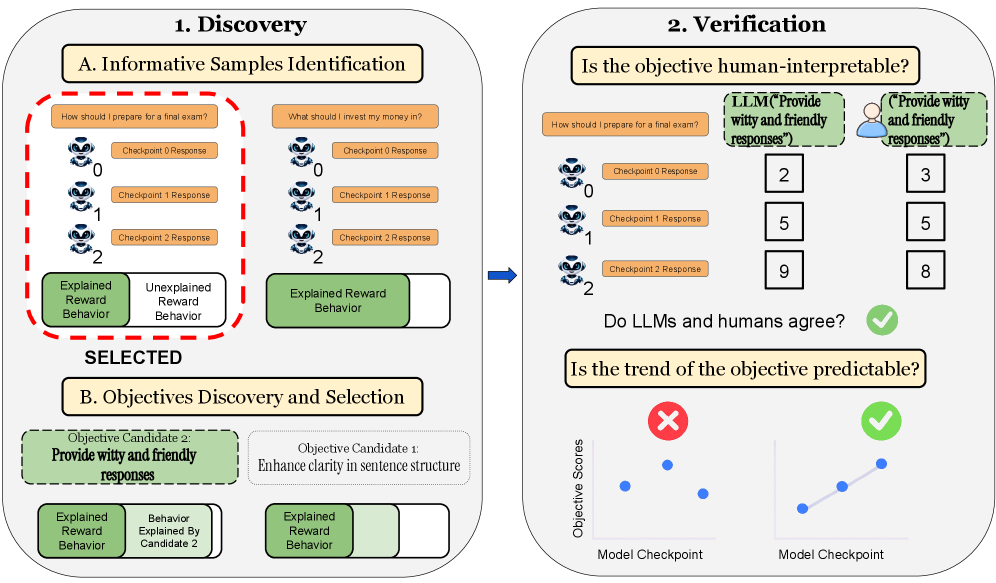
核心思路:提出的Obj-Disco框架通过自动分解对齐奖励信号,识别出人类可解释的自然语言目标,从而提高对齐的透明度和安全性。
技术框架:该框架采用迭代贪心算法,分析训练检查点间的行为变化,识别和验证候选目标。主要模块包括奖励信号分析、目标识别和验证。
关键创新:Obj-Disco的核心创新在于其自动化的目标识别能力,能够捕捉到现有方法未能识别的潜在激励,显著提升了对齐的准确性。
关键设计:框架中使用的参数设置和损失函数经过精心设计,以确保在不同任务和模型规模下的适应性和有效性。
🖼️ 关键图片

📊 实验亮点
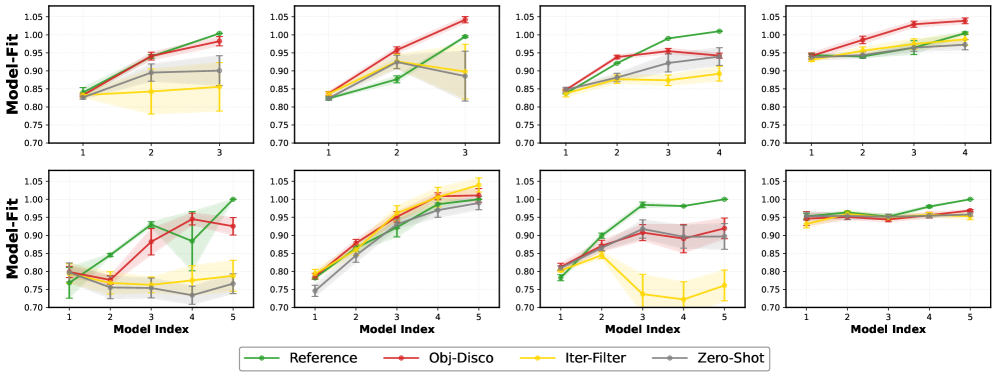
实验结果表明,Obj-Disco框架能够持续捕获超过90%的奖励行为,且这一发现得到了人类评估的进一步验证。这一性能在多种任务和模型上均表现出色,显示出框架的广泛适用性和有效性。
🎯 应用场景
该研究的潜在应用领域包括大型语言模型的开发与优化、AI系统的安全性提升以及对齐目标的透明化。通过识别潜在的激励,Obj-Disco能够帮助开发者更好地理解和控制模型行为,从而推动更安全的AI技术进步。
📄 摘要(原文)
Large language model (LLM) alignment relies on complex reward signals that often obscure the specific behaviors being incentivized, creating critical risks of misalignment and reward hacking. Existing interpretation methods typically rely on pre-defined rubrics, risking the omission of "unknown unknowns", or fail to identify objectives that comprehensively cover and are causal to the model behavior. To address these limitations, we introduce Obj-Disco, a framework that automatically decomposes an alignment reward signal into a sparse, weighted combination of human-interpretable natural language objectives. Our approach utilizes an iterative greedy algorithm to analyze behavioral changes across training checkpoints, identifying and validating candidate objectives that best explain the residual reward signal. Extensive evaluations across diverse tasks, model sizes, and alignment algorithms demonstrate the framework's robustness. Experiments with popular open-source reward models show that the framework consistently captures > 90% of reward behavior, a finding further corroborated by human evaluation. Additionally, a case study on alignment with an open-source reward model reveals that Obj-Disco can successfully identify latent misaligned incentives that emerge alongside intended behaviors. Our work provides a crucial tool for uncovering the implicit objectives in LLM alignment, paving the way for more transparent and safer AI development.