Prescriptive Scaling Reveals the Evolution of Language Model Capabilities
作者: Hanlin Zhang, Jikai Jin, Vasilis Syrgkanis, Sham Kakade
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2026-02-17
备注: Blog Post: https://jkjin.com/prescriptive-scaling
💡 一句话要点
提出Prescriptive Scaling方法,揭示语言模型能力随算力演进规律,并评估其稳定性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 缩放法则 能力边界 分位数回归 模型评估
📋 核心要点
- 现有方法难以准确预测给定算力下,语言模型在下游任务中的性能上限,缺乏指导性的缩放法则。
- 论文提出Prescriptive Scaling方法,通过分位数回归估计模型性能的条件高分位数,从而确定能力边界。
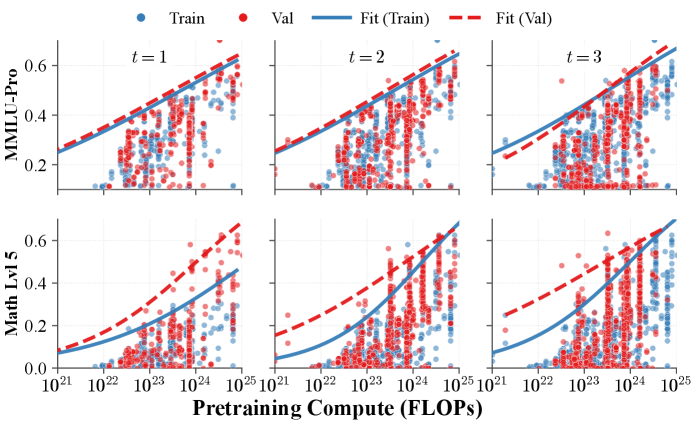
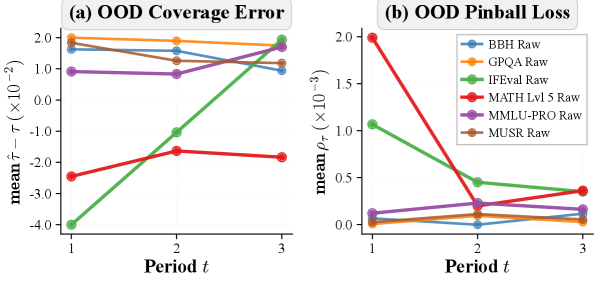
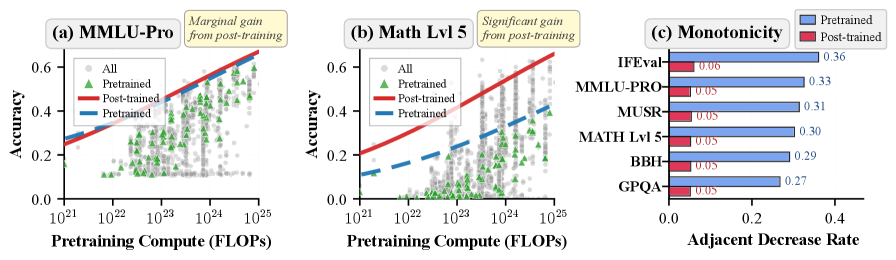
- 实验表明,该方法估计的能力边界在多数任务上稳定,但数学推理能力边界随时间推进,并发布了Proteus 2k数据集。
📝 摘要(中文)
为了部署基础模型,从业者日益需要指导性的缩放法则:给定预训练算力预算,通过当前的后训练实践可以达到的下游精度是多少?并且随着领域的发展,这种映射关系有多稳定?通过对5k个观测数据和2k个新采样数据的模型性能进行大规模观测评估,我们使用单调饱和sigmoid参数化的平滑分位数回归来估计能力边界,即基准分数的条件高分位数作为log预训练FLOPs的函数。我们通过拟合早期模型并评估后期版本来验证时间可靠性。在各种任务中,估计的边界大多是稳定的,但数学推理除外,它表现出随时间持续推进的边界。然后,我们扩展我们的方法来分析任务相关的饱和度,并探究数学推理任务上与污染相关的变化。最后,我们引入了一种高效的算法,该算法使用大约20%的评估预算来恢复接近完整的数据前沿。总而言之,我们的工作发布了Proteus 2k,这是最新的模型性能评估数据集,并引入了一种实用的方法,用于将算力预算转化为可靠的性能期望,并用于监控能力边界何时随时间变化。
🔬 方法详解
问题定义:现有方法在预训练计算预算下,难以准确预测下游任务的性能上限,缺乏对模型能力边界的有效估计。此外,随着模型迭代,能力边界的稳定性也难以评估。现有方法难以有效利用有限的评估预算来探索模型的能力边界。
核心思路:论文的核心思路是通过大规模观测评估,建立预训练算力与下游任务性能之间的映射关系,并使用分位数回归估计性能的条件高分位数,从而确定能力边界。通过对不同时间段的模型进行评估,分析能力边界的稳定性。同时,设计高效算法,在有限的评估预算下探索能力边界。
技术框架:论文的技术框架主要包括以下几个阶段: 1. 数据收集:收集大规模的模型性能数据,包括观测数据和新采样数据。 2. 能力边界估计:使用平滑分位数回归,以预训练FLOPs为自变量,基准分数为因变量,估计性能的条件高分位数,从而确定能力边界。 3. 时间可靠性验证:通过拟合早期模型并评估后期版本,验证能力边界的时间可靠性。 4. 任务相关饱和度分析:分析不同任务的性能饱和度,以及污染对数学推理任务的影响。 5. 高效边界探索算法:设计高效算法,在有限的评估预算下探索能力边界。
关键创新:论文的关键创新在于: 1. 提出了Prescriptive Scaling方法,通过分位数回归估计模型能力边界,为模型部署提供指导。 2. 验证了能力边界的时间可靠性,并发现数学推理能力边界随时间推进。 3. 设计了高效算法,在有限的评估预算下探索能力边界。
关键设计:论文的关键设计包括: 1. 使用单调饱和sigmoid参数化的平滑分位数回归,以保证估计的能力边界单调递增且饱和。 2. 设计高效算法,通过主动学习等策略,在有限的评估预算下探索能力边界。 3. 针对数学推理任务,分析了污染对模型性能的影响,并提出了相应的缓解策略。
🖼️ 关键图片
📊 实验亮点
论文通过大规模实验验证了Prescriptive Scaling方法的有效性,发现多数任务的能力边界稳定,但数学推理能力边界随时间推进。论文还发布了包含2k个新采样数据的Proteus 2k数据集,并提出了一种高效的边界探索算法,仅使用20%的评估预算即可恢复接近完整的数据前沿。
🎯 应用场景
该研究成果可应用于指导基础模型的部署,帮助从业者在给定算力预算下选择合适的模型规模,并预测其在下游任务中的性能。此外,该方法可用于监控模型能力边界的演进,及时发现模型能力的提升或退化。该研究对于推动大语言模型的实际应用具有重要意义。
📄 摘要(原文)
For deploying foundation models, practitioners increasingly need prescriptive scaling laws: given a pre training compute budget, what downstream accuracy is attainable with contemporary post training practice, and how stable is that mapping as the field evolves? Using large scale observational evaluations with 5k observational and 2k newly sampled data on model performance, we estimate capability boundaries, high conditional quantiles of benchmark scores as a function of log pre training FLOPs, via smoothed quantile regression with a monotone, saturating sigmoid parameterization. We validate the temporal reliability by fitting on earlier model generations and evaluating on later releases. Across various tasks, the estimated boundaries are mostly stable, with the exception of math reasoning that exhibits a consistently advancing boundary over time. We then extend our approach to analyze task dependent saturation and to probe contamination related shifts on math reasoning tasks. Finally, we introduce an efficient algorithm that recovers near full data frontiers using roughly 20% of evaluation budget. Together, our work releases the Proteus 2k, the latest model performance evaluation dataset, and introduces a practical methodology for translating compute budgets into reliable performance expectations and for monitoring when capability boundaries shift across time.