On Surprising Effectiveness of Masking Updates in Adaptive Optimizers
作者: Taejong Joo, Wenhan Xia, Cheolmin Kim, Ming Zhang, Eugene Ie
分类: cs.LG, cs.AI
发布日期: 2026-02-17
备注: Preprint
💡 一句话要点
提出Magma,通过掩码更新优化LLM训练,显著提升性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自适应优化器 梯度掩码 动量对齐 模型训练
📋 核心要点
- 现有LLM训练严重依赖复杂的自适应优化器,但计算成本高昂,且可能存在优化不稳定问题。
- 论文提出随机掩码参数更新策略,并进一步设计动量对齐梯度掩码(Magma)来调节更新,实现更平滑的优化。
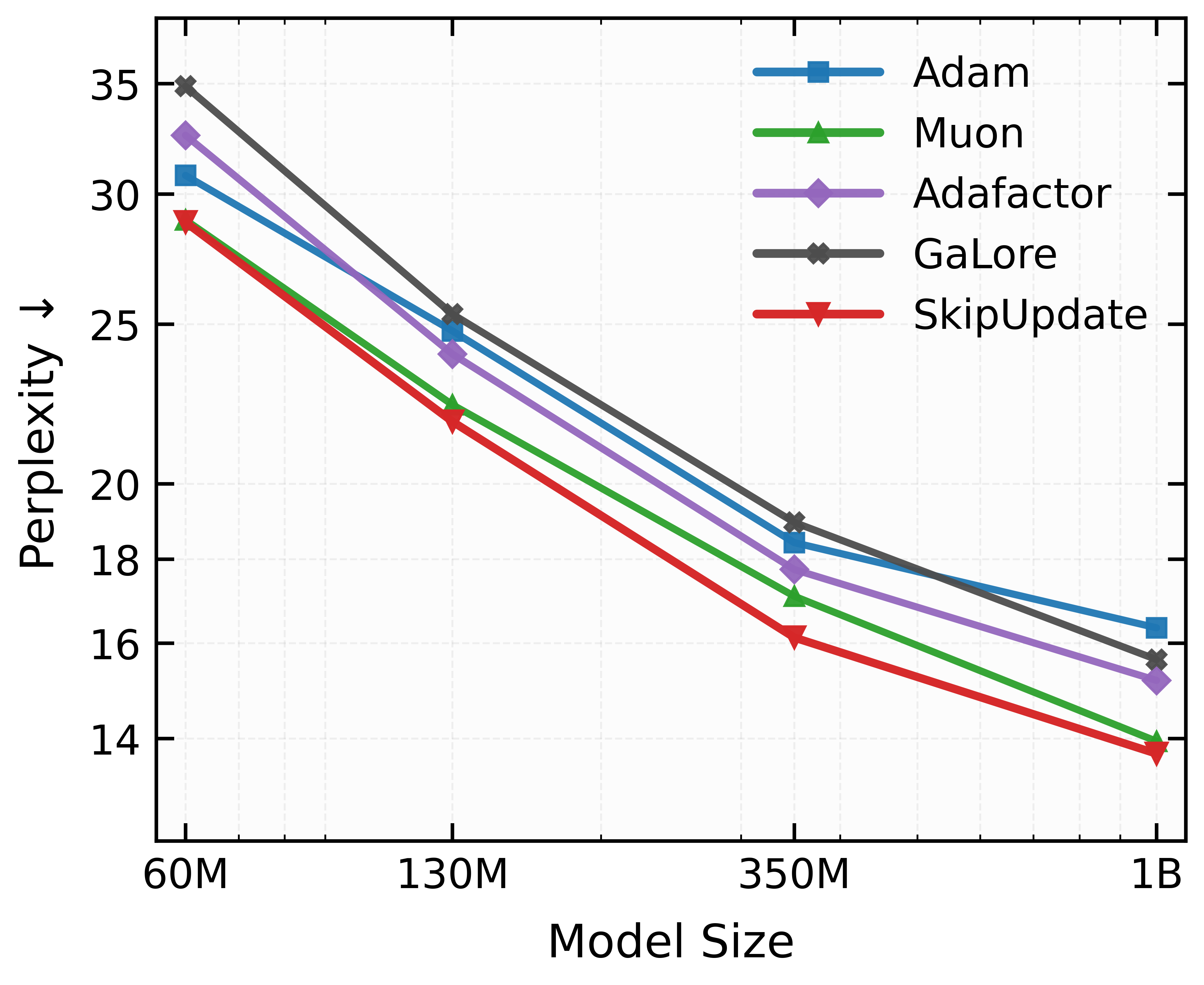
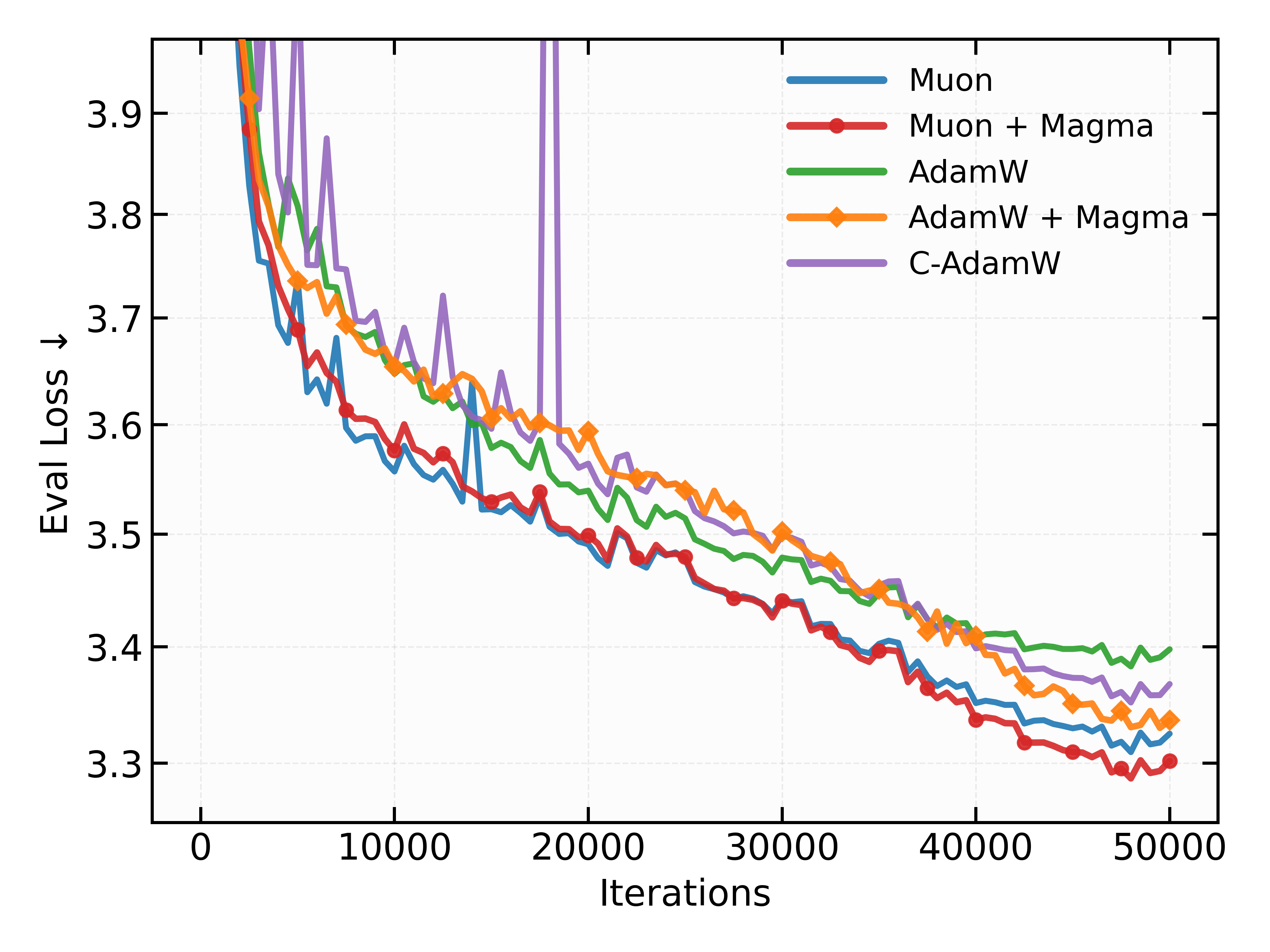
- 实验表明,Magma作为自适应优化器的替代方案,在LLM预训练中能显著降低困惑度,且计算开销可忽略不计。
📝 摘要(中文)
大型语言模型(LLM)的训练几乎完全依赖于具有日益复杂的预处理器的密集自适应优化器。本文对此提出挑战,表明随机掩码参数更新可能非常有效,RMSProp的掩码变体始终优于最新的优化器。分析表明,随机掩码会诱导一种曲率相关的几何正则化,从而平滑优化轨迹。受此发现的启发,本文提出了一种动量对齐梯度掩码(Magma),它使用动量-梯度对齐来调节掩码更新。大量的LLM预训练实验表明,Magma是一种简单的自适应优化器替代方案,具有一致的增益和可忽略的计算开销。值得注意的是,对于1B模型大小,与Adam和Muon相比,Magma分别将困惑度降低了超过19%和9%。
🔬 方法详解
问题定义:现有的大型语言模型训练主要依赖于诸如Adam等自适应优化器,这些优化器虽然在一定程度上加速了训练过程,但其复杂的预处理器带来了巨大的计算开销,并且在某些情况下可能导致优化不稳定。论文旨在寻找一种更高效、更稳定的优化方法,以降低LLM的训练成本并提升模型性能。
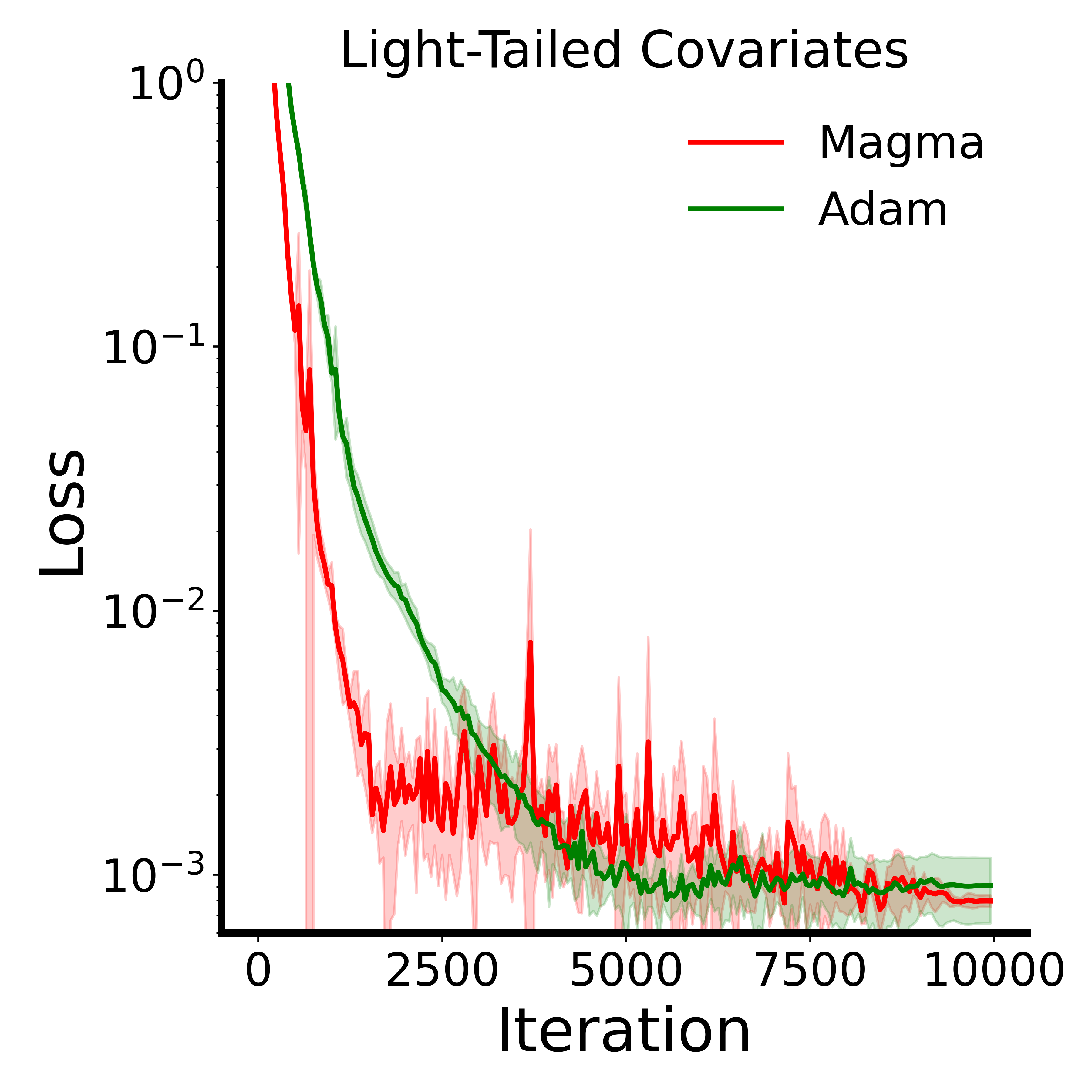
核心思路:论文的核心思路是通过随机掩码参数更新来引入一种曲率相关的几何正则化,从而平滑优化轨迹。这种掩码操作可以看作是对梯度更新的一种约束,使得模型在训练过程中更加关注重要的参数,避免过度拟合。进一步地,论文提出了动量对齐梯度掩码(Magma),利用动量信息来指导掩码的选择,从而更有效地利用梯度信息。
技术框架:Magma的整体框架可以简单描述为:在每个训练步骤中,首先计算梯度,然后根据动量-梯度对齐程度对梯度进行掩码,最后使用掩码后的梯度更新模型参数。具体来说,Magma在标准自适应优化器的基础上增加了一个掩码层,该掩码层根据动量和梯度的对齐程度动态地选择需要更新的参数。
关键创新:论文的关键创新在于发现了随机掩码参数更新的有效性,并提出了动量对齐梯度掩码(Magma)。与传统的自适应优化器相比,Magma引入了一种新的正则化方式,可以更有效地平滑优化轨迹,提高模型的泛化能力。此外,Magma的计算开销很小,可以作为现有自适应优化器的简单替代方案。
关键设计:Magma的关键设计包括:1) 随机掩码的比例,需要根据具体任务进行调整;2) 动量-梯度对齐程度的计算方式,可以使用余弦相似度或其他相似度度量;3) 掩码的生成方式,可以使用硬掩码或软掩码。论文中具体使用了哪种方式以及具体的参数设置未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Magma在1B模型规模下,相较于Adam和Muon,分别将困惑度降低了超过19%和9%。这一显著的性能提升表明Magma是一种有效的优化方法,可以作为现有自适应优化器的替代方案。此外,Magma的计算开销可忽略不计,使其具有很高的实用价值。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的预训练和微调,降低训练成本,提升模型性能。此外,该方法也可推广到其他深度学习模型的训练中,尤其是在计算资源有限的情况下,可以作为一种有效的优化策略。未来,可以进一步研究Magma在不同模型结构和数据集上的表现,探索更优的掩码策略和动量对齐方式。
📄 摘要(原文)
Training large language models (LLMs) relies almost exclusively on dense adaptive optimizers with increasingly sophisticated preconditioners. We challenge this by showing that randomly masking parameter updates can be highly effective, with a masked variant of RMSProp consistently outperforming recent state-of-the-art optimizers. Our analysis reveals that the random masking induces a curvature-dependent geometric regularization that smooths the optimization trajectory. Motivated by this finding, we introduce Momentum-aligned gradient masking (Magma), which modulates the masked updates using momentum-gradient alignment. Extensive LLM pre-training experiments show that Magma is a simple drop-in replacement for adaptive optimizers with consistent gains and negligible computational overhead. Notably, for the 1B model size, Magma reduces perplexity by over 19\% and 9\% compared to Adam and Muon, respectively.