WIMLE: Uncertainty-Aware World Models with IMLE for Sample-Efficient Continuous Control
作者: Mehran Aghabozorgi, Alireza Moazeni, Yanshu Zhang, Ke Li
分类: cs.LG, cs.AI
发布日期: 2026-02-15
备注: Accepted at ICLR 2026. OpenReview: https://openreview.net/forum?id=mzLOnTb3WH
期刊: In Proceedings of the Fourteenth International Conference on Learning Representations (ICLR 2026), 2026
💡 一句话要点
WIMLE:基于IMLE和不确定性感知的世界模型,提升连续控制样本效率
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 强化学习 隐式最大似然估计 不确定性估计 连续控制 样本效率 多模态学习
📋 核心要点
- 基于模型的强化学习易受模型误差累积的影响,且传统方法难以处理多模态动态和过度自信的预测。
- WIMLE通过将IMLE引入模型预测,学习随机多模态世界模型,并利用集成和潜在采样估计预测不确定性。
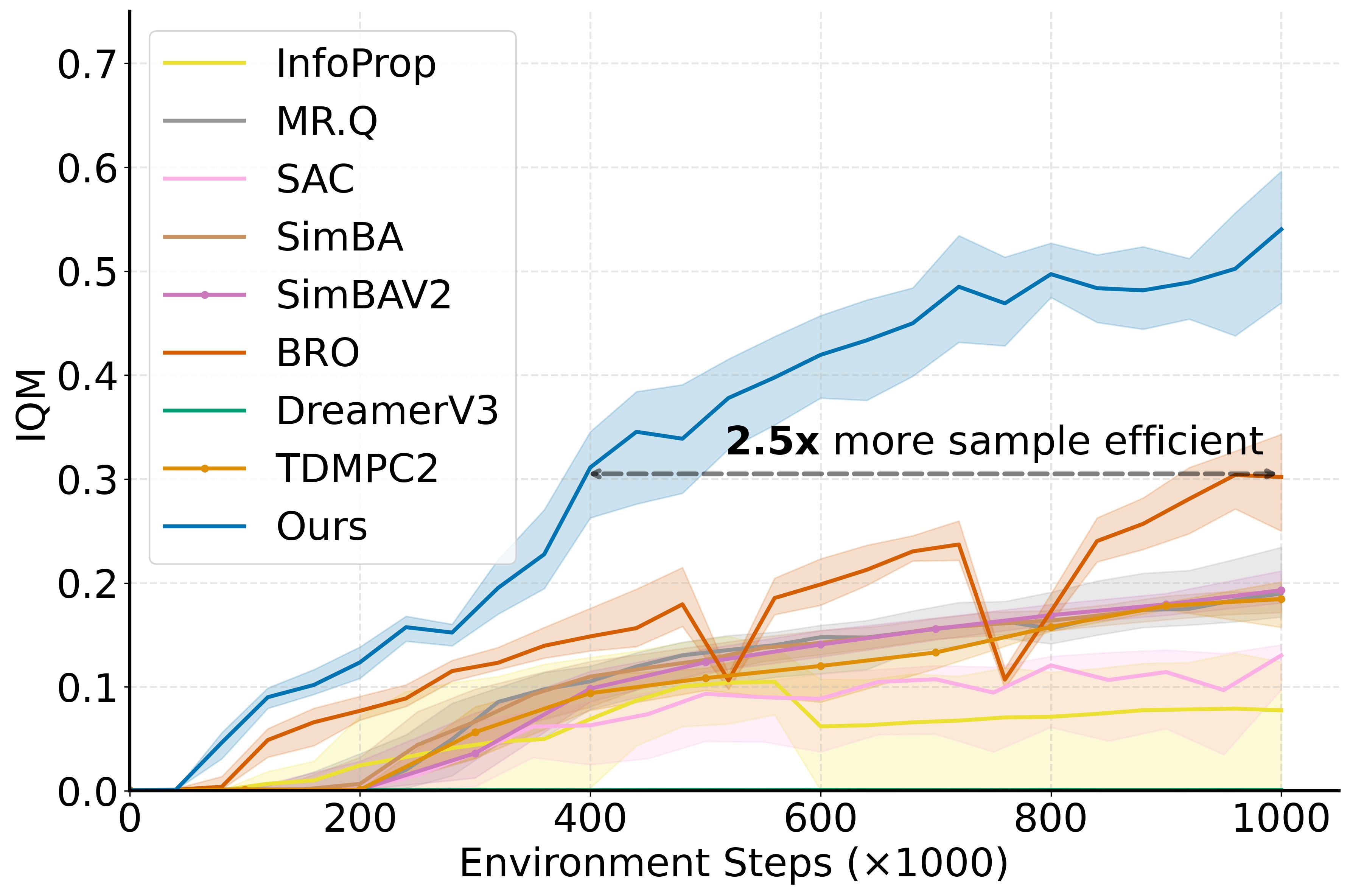
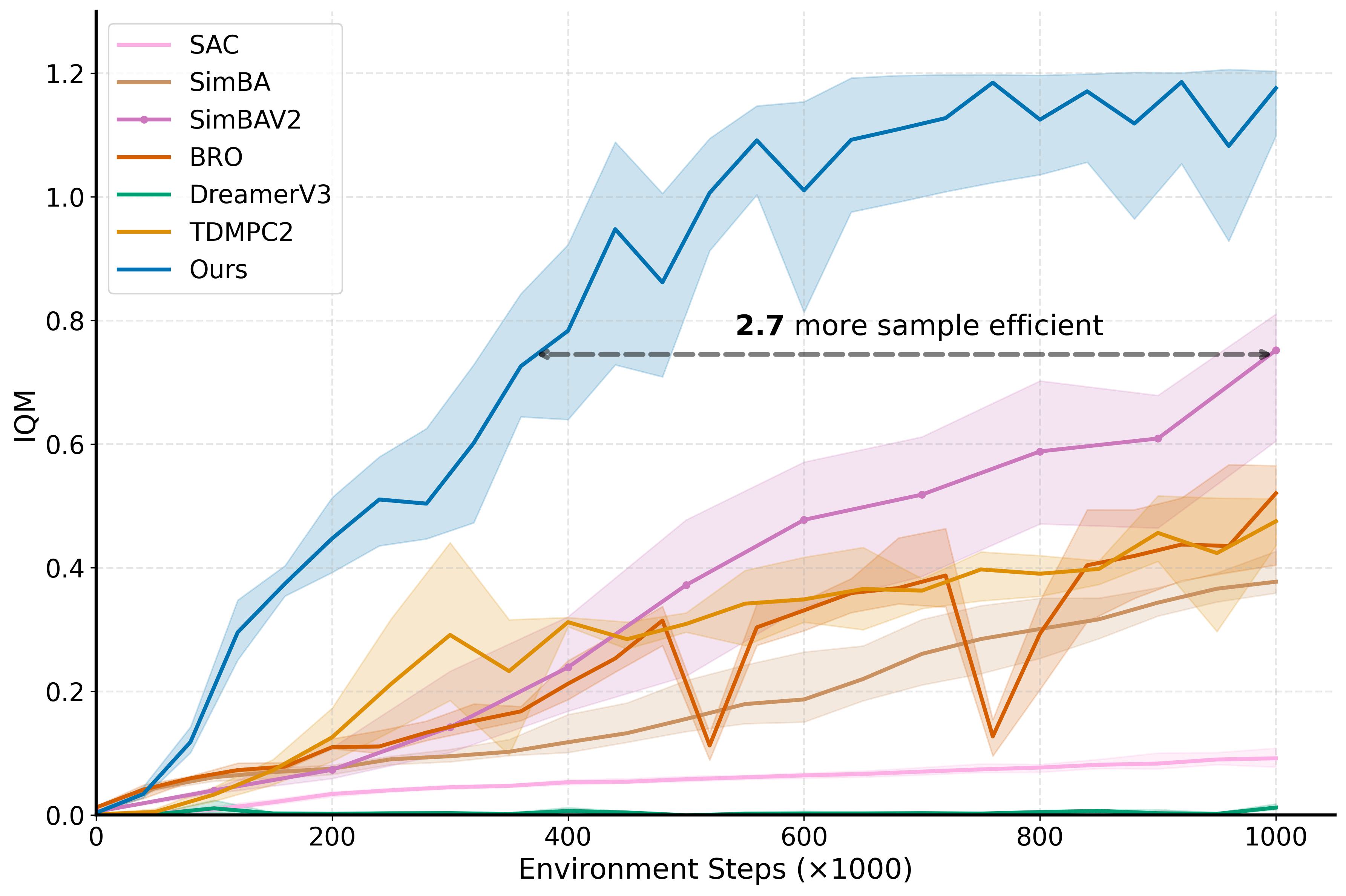
- 实验表明,WIMLE在多个连续控制任务中实现了优越的样本效率和性能,尤其在Humanoid任务上提升显著。
📝 摘要(中文)
本文提出了一种名为WIMLE的模型,它扩展了隐式最大似然估计(IMLE)到基于模型的强化学习框架中,用于学习随机的、多模态的世界模型,无需迭代采样,并通过集成和潜在采样来估计预测不确定性。在训练过程中,WIMLE根据预测置信度对每个合成转换进行加权,保留有用的模型rollout,同时减弱来自不确定预测的偏差,从而实现稳定的学习。在涵盖DeepMind Control、MyoSuite和HumanoidBench的40个连续控制任务中,WIMLE实现了优于强模型无关和基于模型的基线的样本效率和有竞争力的或更好的渐近性能。值得注意的是,在具有挑战性的Humanoid-run任务中,WIMLE相对于最强的竞争对手提高了超过50%的样本效率,并且在HumanoidBench上解决了14个任务中的8个(BRO为4个,SimbaV2为5个)。这些结果突出了基于IMLE的多模态性和不确定性感知加权对于稳定基于模型的强化学习的价值。
🔬 方法详解
问题定义:基于模型的强化学习(MBRL)在样本效率方面具有潜力,但由于模型误差的累积、对多模态动态的平均以及过度自信的预测,导致性能下降。现有的世界模型难以准确捕捉复杂环境中的多模态行为,并且对预测的不确定性估计不足,从而影响了策略学习的稳定性。
核心思路:WIMLE的核心思路是利用隐式最大似然估计(IMLE)来学习世界模型,从而能够捕捉多模态动态,并结合集成方法和潜在采样来估计预测的不确定性。通过对每个合成转换根据其预测置信度进行加权,可以保留有用的模型rollout,同时减少来自不确定预测的偏差,从而实现更稳定和高效的学习。
技术框架:WIMLE的整体框架包括以下几个主要模块:1) 基于IMLE的世界模型学习模块,用于学习环境的动态模型;2) 不确定性估计模块,通过集成和潜在采样来估计模型预测的不确定性;3) 策略优化模块,利用学习到的世界模型和不确定性估计来优化策略。在训练过程中,WIMLE首先使用IMLE学习世界模型,然后估计模型预测的不确定性,并根据不确定性对合成转换进行加权,最后利用加权后的数据来优化策略。
关键创新:WIMLE的关键创新在于将IMLE引入到基于模型的强化学习框架中,从而能够学习随机多模态世界模型,并结合不确定性估计来提高学习的稳定性。与传统的基于最大似然估计(MLE)的方法相比,IMLE能够更好地捕捉多模态动态,避免对多模态行为进行平均。此外,通过不确定性感知加权,WIMLE能够减少来自不确定预测的偏差,从而提高学习的鲁棒性。
关键设计:WIMLE的关键设计包括:1) 使用生成对抗网络(GAN)来实现IMLE,其中生成器用于生成合成数据,判别器用于区分真实数据和合成数据;2) 使用集成方法(例如,Bootstrap)来估计模型预测的不确定性;3) 使用潜在采样来探索环境中的不同状态;4) 使用置信度加权损失函数,根据预测置信度对每个合成转换进行加权。损失函数的设计旨在平衡模型的准确性和不确定性,从而实现更稳定和高效的学习。
🖼️ 关键图片

📊 实验亮点
WIMLE在40个连续控制任务上表现出色,尤其在Humanoid-run任务中,样本效率比最强基线提高了50%以上。在HumanoidBench测试中,WIMLE解决了14个任务中的8个,而BRO和SimbaV2分别只解决了4个和5个。这些结果表明,WIMLE在样本效率和渐近性能方面都优于现有的模型无关和基于模型的强化学习方法。
🎯 应用场景
WIMLE在机器人控制、自动驾驶、游戏AI等领域具有广泛的应用前景。通过学习准确且具有不确定性估计的世界模型,WIMLE可以帮助智能体更好地理解环境动态,从而制定更有效的策略。此外,WIMLE还可以用于模型预测控制(MPC)等任务,提高控制系统的鲁棒性和安全性。未来,WIMLE有望在更复杂的现实世界环境中得到应用,例如,在资源有限或环境动态变化的情况下,帮助机器人完成各种任务。
📄 摘要(原文)
Model-based reinforcement learning promises strong sample efficiency but often underperforms in practice due to compounding model error, unimodal world models that average over multi-modal dynamics, and overconfident predictions that bias learning. We introduce WIMLE, a model-based method that extends Implicit Maximum Likelihood Estimation (IMLE) to the model-based RL framework to learn stochastic, multi-modal world models without iterative sampling and to estimate predictive uncertainty via ensembles and latent sampling. During training, WIMLE weights each synthetic transition by its predicted confidence, preserving useful model rollouts while attenuating bias from uncertain predictions and enabling stable learning. Across $40$ continuous-control tasks spanning DeepMind Control, MyoSuite, and HumanoidBench, WIMLE achieves superior sample efficiency and competitive or better asymptotic performance than strong model-free and model-based baselines. Notably, on the challenging Humanoid-run task, WIMLE improves sample efficiency by over $50$\% relative to the strongest competitor, and on HumanoidBench it solves $8$ of $14$ tasks (versus $4$ for BRO and $5$ for SimbaV2). These results highlight the value of IMLE-based multi-modality and uncertainty-aware weighting for stable model-based RL.