Train Less, Learn More: Adaptive Efficient Rollout Optimization for Group-Based Reinforcement Learning
作者: Zhi Zhang, Zhen Han, Costas Mavromatis, Qi Zhu, Yunyi Zhang, Sheng Guan, Dingmin Wang, Xiong Zhou, Shuai Wang, Soji Adeshina, Vassilis Ioannidis, Huzefa Rangwala
分类: cs.LG, cs.AI
发布日期: 2026-02-15
💡 一句话要点
AERO:自适应高效Rollout优化,提升基于群组强化学习的LLM微调效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 Rollout优化 自适应学习 计算效率 模型微调 群组策略优化
📋 核心要点
- 现有GRPO方法在Rollout结果一致时产生零梯度,导致计算资源浪费,这是LLM强化学习微调中的一个关键问题。
- AERO通过自适应Rollout策略和选择性拒绝机制,避免产生无效的Rollout,并使用贝叶斯后验来维持有效的梯度信号。
- 实验表明,AERO在降低计算成本的同时,能够保持甚至提升LLM在Pass@8和Avg@8等指标上的性能。
📝 摘要(中文)
本文提出了一种名为自适应高效Rollout优化(AERO)的GRPO增强方法,旨在提高基于群组的强化学习(GRPO)在大型语言模型(LLM)后训练中的计算效率。GRPO在处理LLM生成的一组Rollout时,若所有Rollout结果一致(全对或全错),会导致梯度消失,浪费计算资源。AERO通过自适应Rollout策略、选择性拒绝Rollout以及维护贝叶斯后验来避免零优势区域。在Qwen2.5-Math-1.5B、Qwen2.5-7B和Qwen2.5-7B-Instruct三种模型配置下,AERO在不牺牲性能的前提下,将总训练计算量减少约48%,并将每步的实际运行时间平均缩短约45%。在大幅降低计算成本的同时,AERO在Pass@8和Avg@8指标上与GRPO持平甚至有所提升,展示了一种实用、可扩展且计算高效的LLM对齐策略。
🔬 方法详解
问题定义:论文旨在解决基于群组的强化学习(GRPO)在大型语言模型(LLM)微调过程中,因Rollout结果一致而导致的梯度消失问题。当一个群组内的所有Rollout都产生相同的结果(全部正确或全部错误)时,GRPO计算出的群组归一化优势会变为零,从而导致没有梯度信号,浪费了大量的计算资源。这种现象在复杂的任务中尤为常见,严重影响了训练效率。
核心思路:AERO的核心思路是通过自适应地调整Rollout策略,避免产生大量同质化的Rollout,从而减少梯度消失的可能性。具体来说,AERO会根据当前Rollout的结果,动态地决定是否继续生成新的Rollout,并有选择地拒绝一些Rollout,以保证群组内的Rollout具有多样性,从而维持有效的梯度信号。
技术框架:AERO是在GRPO的基础上进行改进的。其整体框架与GRPO类似,仍然是基于强化学习的策略优化过程。主要包含以下几个关键模块:1) 自适应Rollout策略:根据已有的Rollout结果,动态调整Rollout的数量。2) 选择性拒绝:根据一定的策略,拒绝一些Rollout,以保证群组内的多样性。3) 贝叶斯后验维护:维护一个贝叶斯后验,用于估计Rollout的质量,并用于指导Rollout策略和选择性拒绝。
关键创新:AERO最重要的创新点在于其自适应的Rollout策略和选择性拒绝机制。与传统的GRPO方法不同,AERO不是固定Rollout的数量,而是根据当前的学习状态动态调整。这种自适应性使得AERO能够更有效地利用计算资源,避免产生大量的无效Rollout。此外,AERO还引入了贝叶斯后验,用于估计Rollout的质量,从而更好地指导Rollout策略和选择性拒绝。
关键设计:AERO的关键设计包括:1) 自适应Rollout策略:使用一个策略网络来决定是否继续生成新的Rollout,该网络的输入包括当前Rollout的结果和贝叶斯后验的估计。2) 选择性拒绝:使用一个拒绝网络来决定是否拒绝一个Rollout,该网络的输入也包括当前Rollout的结果和贝叶斯后验的估计。3) 贝叶斯后验维护:使用一个贝叶斯模型来估计Rollout的质量,该模型的先验分布可以根据经验设置,后验分布则根据实际的Rollout结果进行更新。
🖼️ 关键图片
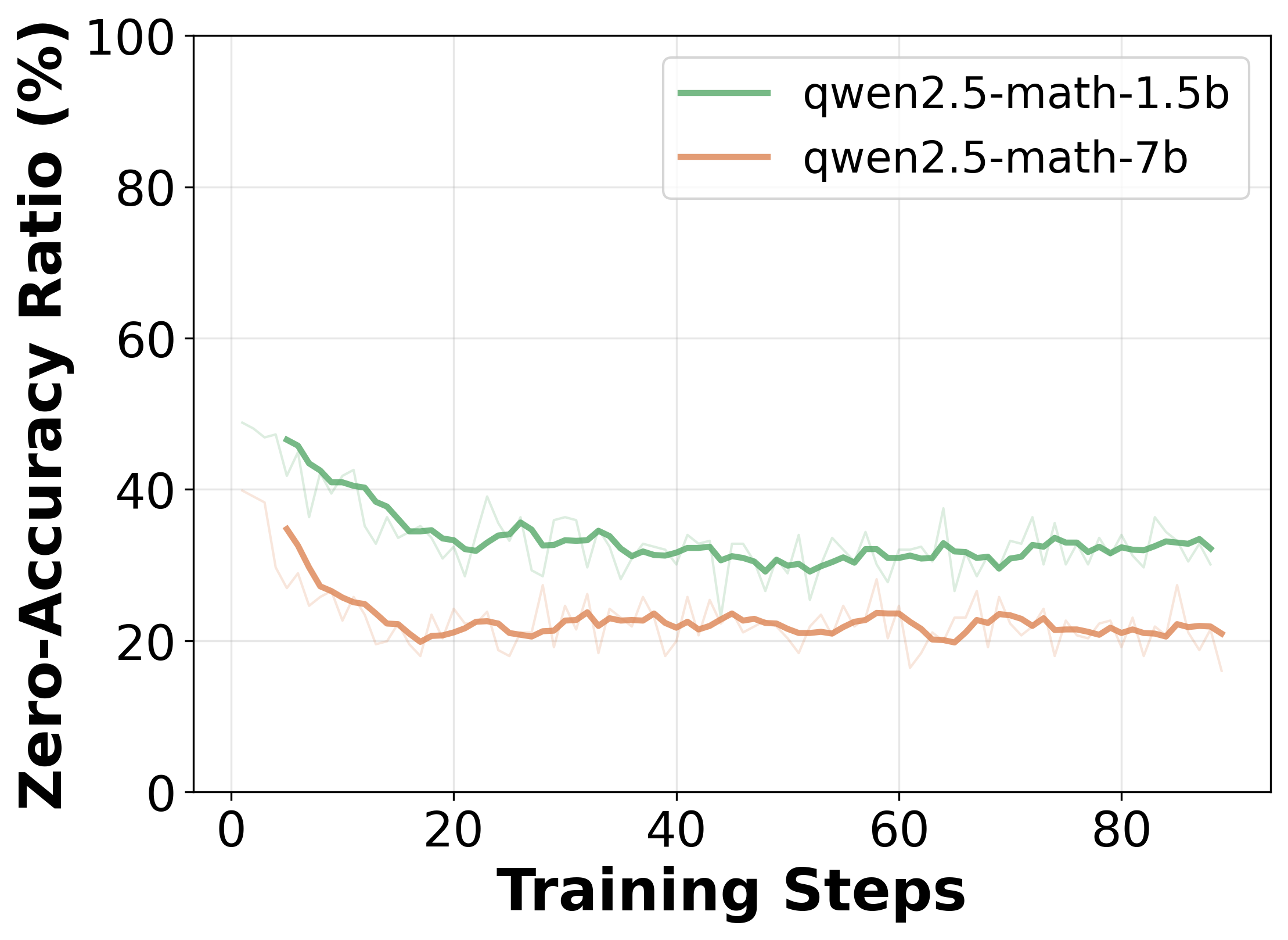
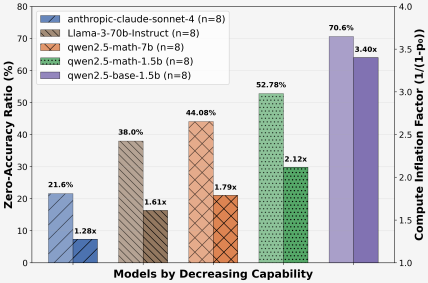
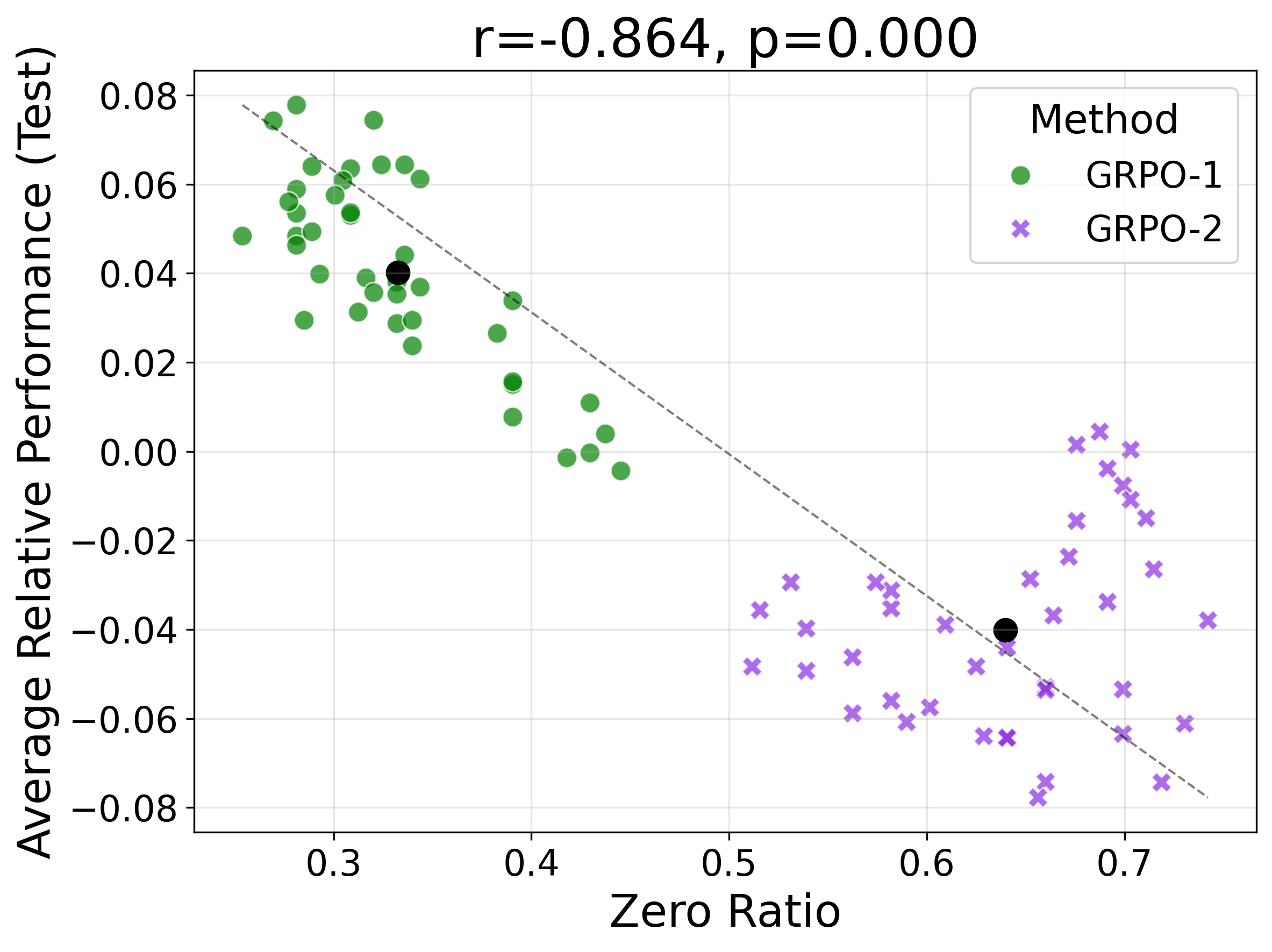
📊 实验亮点
实验结果表明,在相同的Rollout预算下,AERO相比GRPO能够将总训练计算量减少约48%,并将每步的实际运行时间平均缩短约45%。同时,AERO在Pass@8和Avg@8等指标上与GRPO持平甚至有所提升。例如,在Qwen2.5-7B-Instruct模型上,AERO在Pass@8指标上取得了略微的提升,证明了其在降低计算成本的同时,能够保持甚至提升模型的性能。
🎯 应用场景
AERO可广泛应用于需要通过强化学习进行微调的大型语言模型,尤其是在奖励信号稀疏或验证成本较高的场景下。该方法能够显著降低计算成本,提高训练效率,加速LLM的对齐过程。未来,AERO可以进一步扩展到其他类型的强化学习任务,例如机器人控制和游戏AI等。
📄 摘要(原文)
Reinforcement learning (RL) plays a central role in large language model (LLM) post-training. Among existing approaches, Group Relative Policy Optimization (GRPO) is widely used, especially for RL with verifiable rewards (RLVR) fine-tuning. In GRPO, each query prompts the LLM to generate a group of rollouts with a fixed group size $N$. When all rollouts in a group share the same outcome, either all correct or all incorrect, the group-normalized advantages become zero, yielding no gradient signal and wasting fine-tuning compute. We introduce Adaptive Efficient Rollout Optimization (AERO), an enhancement of GRPO. AERO uses an adaptive rollout strategy, applies selective rejection to strategically prune rollouts, and maintains a Bayesian posterior to prevent zero-advantage dead zones. Across three model configurations (Qwen2.5-Math-1.5B, Qwen2.5-7B, and Qwen2.5-7B-Instruct), AERO improves compute efficiency without sacrificing performance. Under the same total rollout budget, AERO reduces total training compute by about 48% while shortening wall-clock time per step by about 45% on average. Despite the substantial reduction in compute, AERO matches or improves Pass@8 and Avg@8 over GRPO, demonstrating a practical, scalable, and compute-efficient strategy for RL-based LLM alignment.