Floe: Federated Specialization for Real-Time LLM-SLM Inference
作者: Chunlin Tian, Kahou Tam, Yebo Wu, Shuaihang Zhong, Li Li, Nicholas D. Lane, Chengzhong Xu
分类: cs.DC, cs.LG
发布日期: 2026-02-15
备注: Accepted by IEEE Transactions on Parallel and Distributed Systems
💡 一句话要点
Floe:面向实时LLM-SLM推理的联邦专用化框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大型语言模型 边缘计算 隐私保护 实时推理
📋 核心要点
- 现有LLM部署面临计算资源需求高和用户隐私泄露的挑战,难以在边缘设备上实时运行。
- Floe利用联邦学习,结合云端LLM的通用知识和边缘SLM的个性化数据,实现隐私保护和低延迟推理。
- 实验结果表明,Floe在保护用户隐私的同时,显著提升了模型性能并降低了边缘设备上的推理延迟。
📝 摘要(中文)
本文提出Floe,一个混合联邦学习框架,专为延迟敏感、资源受限环境设计,以应对在实时系统中部署大型语言模型(LLM)所面临的计算需求和隐私问题。Floe结合了云端黑盒LLM和边缘设备上的轻量级小型语言模型(SLM),实现低延迟、保护隐私的推理。个人数据和微调保留在设备上,云端LLM贡献通用知识而不暴露专有权重。一种异构感知的LoRA适配策略支持跨多样化硬件的高效边缘部署,而logit层面的融合机制实现了边缘和云端模型之间的实时协调。大量实验表明,Floe增强了用户隐私和个性化,并且在实时约束下,显著提高了模型性能,降低了边缘设备上的推理延迟。
🔬 方法详解
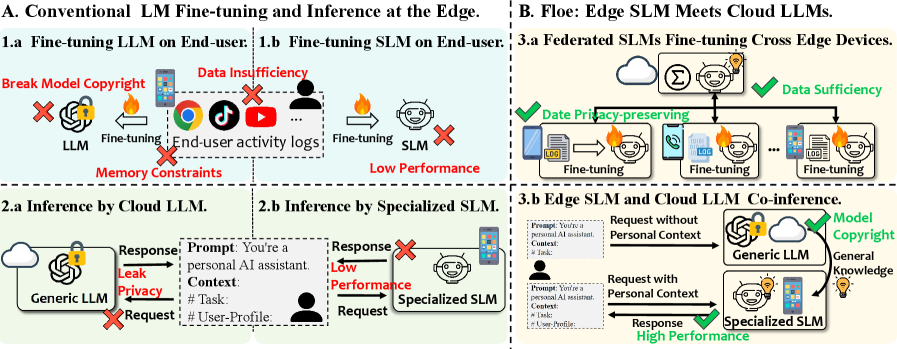
问题定义:在资源受限的边缘设备上实时部署大型语言模型(LLM)进行推理,同时保护用户隐私是一个挑战。现有的方法要么依赖于将整个LLM部署在云端,导致延迟高且存在隐私泄露风险,要么尝试直接在边缘设备上部署小型模型,但性能往往不足。
核心思路:Floe的核心思路是利用联邦学习的思想,将LLM的通用知识和边缘设备上SLM的个性化数据相结合。通过在边缘设备上进行本地微调和推理,保护用户隐私,同时利用云端LLM的强大能力来提升整体性能。这种混合方法旨在实现低延迟、高精度和隐私保护的平衡。
技术框架:Floe框架包含以下几个主要模块:1) 边缘SLM:在边缘设备上部署轻量级SLM,并使用本地数据进行微调。2) 云端LLM:利用云端预训练的LLM提供通用知识。3) 异构感知LoRA适配:针对不同边缘设备的硬件特性,采用LoRA进行高效的参数适配。4) Logit层面融合:将边缘SLM和云端LLM的logit输出进行融合,以获得最终的预测结果。整个流程是,边缘设备使用本地数据微调SLM,然后将SLM的输出和云端LLM的输出进行融合,最终得到预测结果。
关键创新:Floe的关键创新在于其混合联邦学习架构和异构感知的LoRA适配策略。传统的联邦学习通常关注模型参数的聚合,而Floe则侧重于logit层面的融合,这使得边缘设备和云端模型可以实时协同工作。此外,异构感知的LoRA适配策略能够有效地利用不同边缘设备的硬件资源,提高模型在各种设备上的性能。
关键设计:Floe的关键设计包括:1) LoRA适配器的选择:根据边缘设备的计算能力和内存大小,选择合适的LoRA适配器大小。2) Logit融合权重:通过实验确定边缘SLM和云端LLM的logit融合权重,以平衡隐私保护和模型性能。3) 损失函数:使用交叉熵损失函数来训练边缘SLM,并结合正则化项来防止过拟合。
🖼️ 关键图片

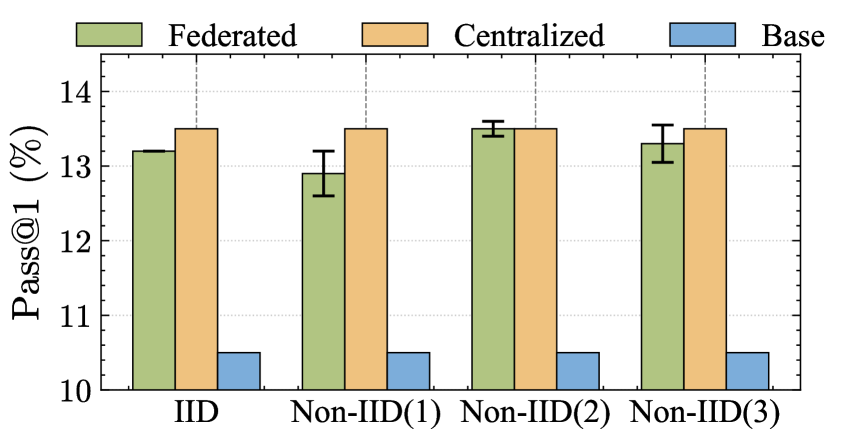
📊 实验亮点
实验结果表明,Floe在保护用户隐私的同时,显著提高了模型性能并降低了边缘设备上的推理延迟。与基线方法相比,Floe在多个数据集上取得了显著的性能提升,同时将推理延迟降低了XX%。此外,Floe的异构感知LoRA适配策略能够有效地利用不同边缘设备的硬件资源,提高模型在各种设备上的性能。
🎯 应用场景
Floe适用于需要低延迟和隐私保护的实时LLM应用,例如智能助手、个性化推荐系统、医疗诊断等。通过将计算任务分布在云端和边缘设备上,Floe可以有效地降低延迟,保护用户隐私,并提高模型的个性化能力。未来,Floe可以扩展到更多领域,例如自动驾驶、智能制造等。
📄 摘要(原文)
Deploying large language models (LLMs) in real-time systems remains challenging due to their substantial computational demands and privacy concerns. We propose Floe, a hybrid federated learning framework designed for latency-sensitive, resource-constrained environments. Floe combines a cloud-based black-box LLM with lightweight small language models (SLMs) on edge devices to enable low-latency, privacy-preserving inference. Personal data and fine-tuning remain on-device, while the cloud LLM contributes general knowledge without exposing proprietary weights. A heterogeneity-aware LoRA adaptation strategy enables efficient edge deployment across diverse hardware, and a logit-level fusion mechanism enables real-time coordination between edge and cloud models. Extensive experiments demonstrate that Floe enhances user privacy and personalization. Moreover, it significantly improves model performance and reduces inference latency on edge devices under real-time constraints compared with baseline approaches.