DeepFusion: Accelerating MoE Training via Federated Knowledge Distillation from Heterogeneous Edge Devices
作者: Songyuan Li, Jia Hu, Ahmed M. Abdelmoniem, Geyong Min, Haojun Huang, Jiwei Huang
分类: cs.LG, cs.AI, cs.MA
发布日期: 2026-02-15
备注: Index Terms: Large language models, Mixture-of-experts, Federated knowledge distillation, Edge device heterogeneity
💡 一句话要点
DeepFusion:通过联邦知识蒸馏加速异构边缘设备上的MoE模型训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 知识蒸馏 混合专家模型 异构设备 自然语言处理
📋 核心要点
- 现有联邦学习方法要求边缘设备托管本地MoE模型,这对于资源受限的设备来说是不切实际的,因为MoE模型体积庞大。
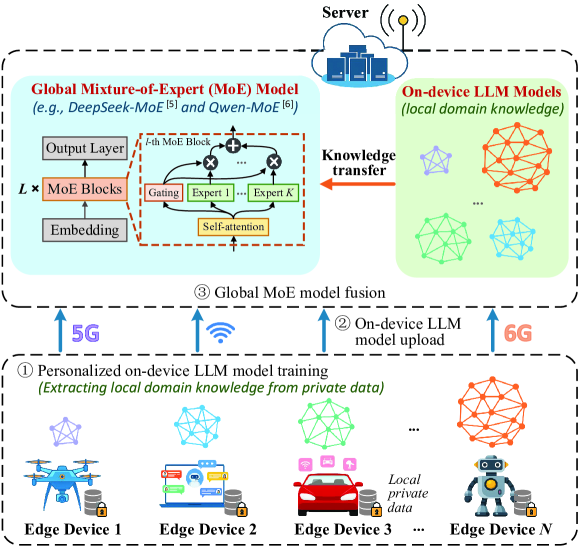
- DeepFusion通过联邦知识蒸馏,融合异构边缘设备上的LLM知识,构建一个知识丰富的全局MoE模型,无需设备托管大型MoE模型。
- 实验表明,DeepFusion性能接近集中式MoE训练,显著降低了通信成本并提高了token困惑度,验证了其有效性。
📝 摘要(中文)
本文提出DeepFusion,一个可扩展的联邦MoE训练框架,旨在通过联邦知识蒸馏融合异构边缘设备上的LLM知识,从而生成知识丰富的全局MoE模型。DeepFusion允许每个设备独立配置和训练适应自身需求和硬件限制的本地LLM。此外,提出了视图对齐注意力(VAA)模块,该模块整合来自全局MoE模型的多阶段特征表示,构建与本地LLM对齐的预测视角,从而实现有效的跨架构知识蒸馏。VAA通过显式对齐预测视角,解决了传统联邦知识蒸馏中由于模型架构和预测行为差异导致的视图不匹配问题。在工业级MoE模型(Qwen-MoE和DeepSeek-MoE)和真实世界数据集(医疗和金融)上的实验表明,DeepFusion的性能接近集中式MoE训练,与关键的联邦MoE基线相比,DeepFusion降低了高达71%的通信成本,并将token困惑度提高了高达5.28%。
🔬 方法详解
问题定义:论文旨在解决在资源受限的异构边缘设备上训练大型MoE模型的问题。传统的联邦学习方法需要每个设备都部署一个完整的MoE模型,这对于边缘设备来说负担过重。此外,由于设备之间的模型架构和数据分布存在差异,直接进行联邦学习会导致性能下降。
核心思路:DeepFusion的核心思路是通过联邦知识蒸馏,将每个设备上训练的轻量级LLM的知识迁移到一个全局的MoE模型中。每个设备可以根据自身的资源和数据特点训练一个定制化的LLM,然后将这些LLM的知识通过知识蒸馏的方式聚合到全局MoE模型中,从而避免了在边缘设备上部署大型MoE模型的需求。
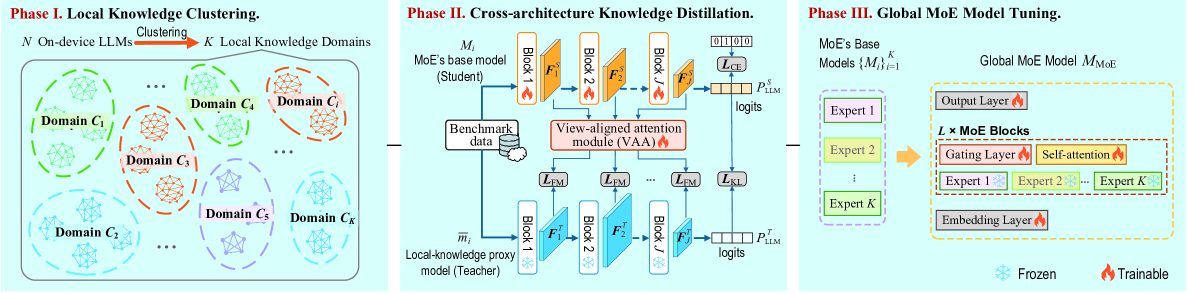
技术框架:DeepFusion框架主要包含以下几个阶段:1) 本地模型训练:每个边缘设备根据自身的数据和资源限制,训练一个本地的LLM模型。2) 全局模型训练:服务器维护一个全局的MoE模型,并接收来自边缘设备的知识蒸馏信号。3) 知识蒸馏:边缘设备将本地LLM的预测结果作为教师信号,指导全局MoE模型的训练。4) 模型聚合:服务器定期将全局MoE模型的参数发送给边缘设备,以便进行下一轮的训练。
关键创新:DeepFusion的关键创新在于提出了视图对齐注意力(VAA)模块。VAA模块能够将全局MoE模型的多阶段特征表示与本地LLM的预测视角对齐,从而实现更有效的知识蒸馏。传统的知识蒸馏方法在异构模型之间进行知识迁移时,容易出现视图不匹配的问题,导致知识迁移效果不佳。VAA模块通过显式地对齐预测视角,解决了这个问题。
关键设计:VAA模块的设计是DeepFusion的关键。VAA模块通过引入注意力机制,将全局MoE模型的多层特征进行加权融合,从而构建一个与本地LLM预测视角对齐的特征表示。具体来说,VAA模块首先将全局MoE模型的每一层特征进行线性变换,然后使用注意力机制计算每一层特征的权重,最后将加权后的特征进行融合。此外,DeepFusion还使用了对比学习损失函数来进一步提高知识蒸馏的效果。损失函数的设计目标是使全局MoE模型的预测结果与本地LLM的预测结果尽可能接近。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DeepFusion在Qwen-MoE和DeepSeek-MoE等工业级MoE模型上取得了显著的性能提升。与传统的联邦MoE基线相比,DeepFusion降低了高达71%的通信成本,并将token困惑度提高了高达5.28%。在医疗和金融等真实世界数据集上的实验也验证了DeepFusion的有效性,其性能接近集中式MoE训练。
🎯 应用场景
DeepFusion适用于各种需要利用边缘设备数据进行模型训练的场景,例如医疗、金融、自动驾驶等。在这些场景中,数据通常具有隐私敏感性,无法直接上传到云端进行集中式训练。DeepFusion可以在保护数据隐私的前提下,利用边缘设备的数据来训练高性能的MoE模型,从而提高模型的泛化能力和准确性。该技术有望加速AI在各个行业的落地应用。
📄 摘要(原文)
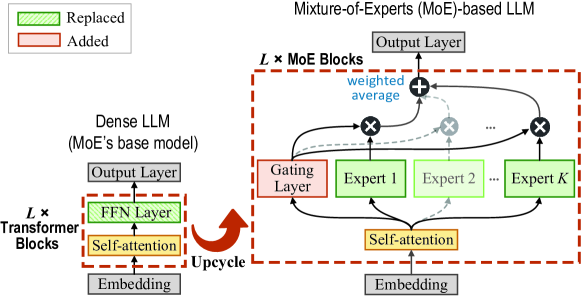
Recent Mixture-of-Experts (MoE)-based large language models (LLMs) such as Qwen-MoE and DeepSeek-MoE are transforming generative AI in natural language processing. However, these models require vast and diverse training data. Federated learning (FL) addresses this challenge by leveraging private data from heterogeneous edge devices for privacy-preserving MoE training. Nonetheless, traditional FL approaches require devices to host local MoE models, which is impractical for resource-constrained devices due to large model sizes. To address this, we propose DeepFusion, the first scalable federated MoE training framework that enables the fusion of heterogeneous on-device LLM knowledge via federated knowledge distillation, yielding a knowledge-abundant global MoE model. Specifically, DeepFusion features each device to independently configure and train an on-device LLM tailored to its own needs and hardware limitations. Furthermore, we propose a novel View-Aligned Attention (VAA) module that integrates multi-stage feature representations from the global MoE model to construct a predictive perspective aligned with on-device LLMs, thereby enabling effective cross-architecture knowledge distillation. By explicitly aligning predictive perspectives, VAA resolves the view-mismatch problem in traditional federated knowledge distillation, which arises from heterogeneity in model architectures and prediction behaviors between on-device LLMs and the global MoE model. Experiments with industry-level MoE models (Qwen-MoE and DeepSeek-MoE) and real-world datasets (medical and finance) demonstrate that DeepFusion achieves performance close to centralized MoE training. Compared with key federated MoE baselines, DeepFusion reduces communication costs by up to 71% and improves token perplexity by up to 5.28%.