Machine Learning as a Tool (MLAT): A Framework for Integrating Statistical ML Models as Callable Tools within LLM Agent Workflows
作者: Edwin Chen, Zulekha Bibi
分类: cs.LG, cs.AI
发布日期: 2026-02-15
备注: Submitted to the Google Gemini 3 Hackathon
💡 一句话要点
提出MLAT框架,将预训练ML模型作为LLM Agent工作流中的可调用工具,实现上下文推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 机器学习即服务 工具调用 上下文推理 结构化输出 定价模型 XGBoost
📋 核心要点
- 传统pipeline将ML推理作为静态预处理,缺乏灵活性,无法根据上下文动态调用和调整。
- MLAT框架将预训练ML模型作为LLM Agent的可调用工具,使LLM能根据上下文推理并决定何时使用。
- PitchCraft系统验证了MLAT,通过ML预测定价,将提案生成时间从数小时缩短到10分钟以内。
📝 摘要(中文)
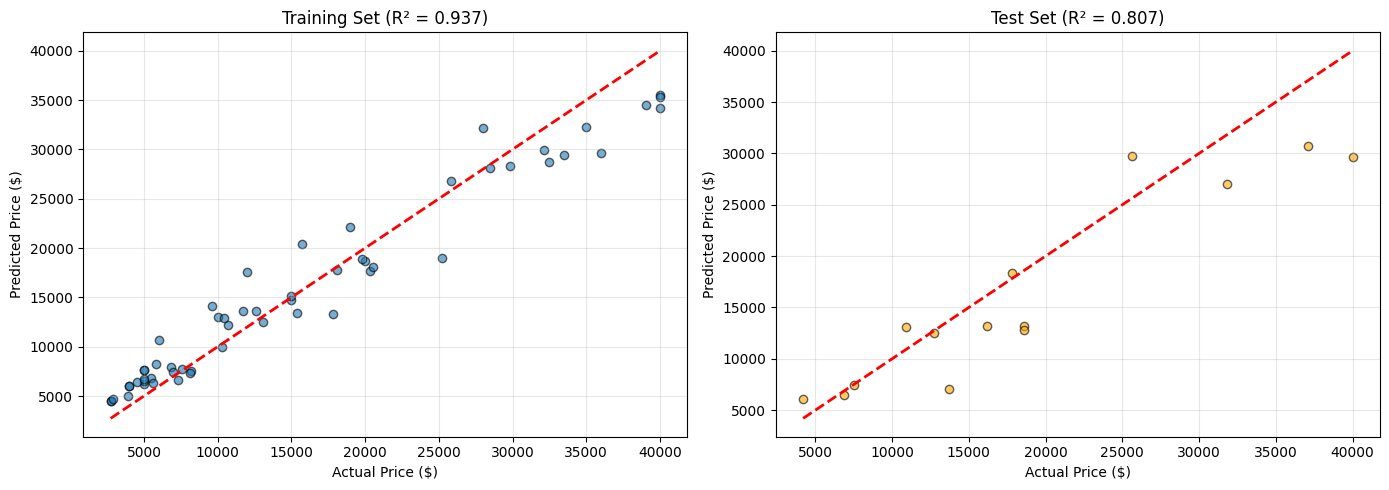
本文介绍了一种名为“机器学习即工具(MLAT)”的设计模式,该模式将预训练的统计机器学习模型作为大型语言模型(LLM)Agent工作流中的可调用工具。这使得编排Agent能够在需要时调用定量预测,并在上下文中推理其输出。与将ML推理视为静态预处理步骤的传统pipeline不同,MLAT将模型定位为与网络搜索、数据库查询和API同等重要的工具,使LLM能够根据对话上下文决定何时以及如何使用它。为了验证MLAT,我们展示了一个名为PitchCraft的试点生产系统,该系统将discovery call录音转换为包含ML预测定价的专业提案。该系统使用两个Agent:一个研究Agent,通过并行工具调用收集潜在客户情报;一个草稿Agent,调用XGBoost定价模型作为工具调用,并通过结构化输出生成完整的提案。该定价模型在包含真实数据和人工验证合成数据的70个样本上进行训练,在held-out数据上实现了R^2 = 0.807,平均绝对误差为3688美元。该系统将提案生成时间从数小时缩短到10分钟以内。我们描述了MLAT框架、结构化输出架构、极端数据稀缺情况下的训练方法以及展示有意义的学习关系的敏感性分析。MLAT可以推广到需要定量估计和上下文推理的领域。
🔬 方法详解
问题定义:现有方法通常将机器学习模型的推理作为静态的预处理步骤,缺乏与大型语言模型(LLM)的动态交互能力。这限制了LLM在复杂任务中利用定量预测进行推理的能力,尤其是在需要根据上下文信息灵活调整模型使用方式的场景下。现有方法难以将ML模型无缝集成到LLM Agent的工作流中,使其像其他工具(如网络搜索、数据库查询)一样被灵活调用和利用。
核心思路:MLAT的核心思想是将预训练的统计机器学习模型封装成可调用的工具,供LLM Agent在工作流中按需使用。这种设计允许LLM根据对话上下文和任务需求,动态地决定何时以及如何调用ML模型进行定量预测,并将预测结果纳入推理过程。通过将ML模型视为一等公民,MLAT赋予了LLM更强的决策能力和问题解决能力。
技术框架:MLAT框架包含以下主要组件:1) 预训练的统计机器学习模型,用于执行定量预测;2) LLM Agent,负责编排整个工作流,并根据上下文信息决定何时调用ML模型;3) 工具调用接口,用于将ML模型暴露为可调用的工具;4) 结构化输出架构,用于将ML模型的预测结果以结构化的方式传递给LLM Agent。在PitchCraft系统中,包含Research Agent和Draft Agent两个Agent,前者负责收集信息,后者负责生成提案。
关键创新:MLAT的关键创新在于将ML模型集成到LLM Agent工作流的方式。与传统的静态pipeline不同,MLAT允许LLM动态地调用和利用ML模型,从而实现了更灵活和智能的任务执行。此外,MLAT还提出了一种结构化输出架构,用于将ML模型的预测结果以清晰和易于理解的方式传递给LLM Agent。
关键设计:PitchCraft系统使用XGBoost模型进行定价预测,该模型在包含70个样本的数据集上进行训练,数据集结合了真实数据和人工验证的合成数据。模型训练的目标是最小化预测价格与实际价格之间的误差。系统采用结构化输出架构,确保ML模型的预测结果能够以清晰和易于理解的方式传递给LLM Agent,以便进行后续的推理和决策。
🖼️ 关键图片
📊 实验亮点
PitchCraft系统验证了MLAT的有效性。在提案生成任务中,定价模型在held-out数据上实现了R^2 = 0.807,平均绝对误差为3688美元。该系统将提案生成时间从数小时缩短到10分钟以内,显著提高了效率。这些结果表明,MLAT能够有效地将ML模型的预测能力与LLM的推理能力相结合,从而解决实际问题。
🎯 应用场景
MLAT框架可应用于需要定量估计与上下文推理相结合的各种领域,例如销售提案生成、客户服务自动化、金融风险评估、医疗诊断辅助等。通过将ML模型集成到LLM Agent工作流中,可以显著提高任务执行的效率和准确性,并为用户提供更智能和个性化的服务。未来,MLAT有望成为构建复杂AI系统的通用设计模式。
📄 摘要(原文)
We introduce Machine Learning as a Tool (MLAT), a design pattern in which pre-trained statistical machine learning models are exposed as callable tools within large language model (LLM) agent workflows. This allows an orchestrating agent to invoke quantitative predictions when needed and reason about their outputs in context. Unlike conventional pipelines that treat ML inference as a static preprocessing step, MLAT positions the model as a first-class tool alongside web search, database queries, and APIs, enabling the LLM to decide when and how to use it based on conversational context. To validate MLAT, we present PitchCraft, a pilot production system that converts discovery call recordings into professional proposals with ML-predicted pricing. The system uses two agents: a Research Agent that gathers prospect intelligence via parallel tool calls, and a Draft Agent that invokes an XGBoost pricing model as a tool call and generates a complete proposal through structured outputs. The pricing model, trained on 70 examples combining real and human-verified synthetic data, achieves R^2 = 0.807 on held-out data with a mean absolute error of 3688 USD. The system reduces proposal generation time from multiple hours to under 10 minutes. We describe the MLAT framework, structured output architecture, training methodology under extreme data scarcity, and sensitivity analysis demonstrating meaningful learned relationships. MLAT generalizes to domains requiring quantitative estimation combined with contextual reasoning.